







 超级会员免费看
超级会员免费看
摘要
面向目标的全新分子设计,即生成具有特定性质或子结构约束的分子,是药物发现中一项至关重要但极具挑战性的任务。现有的方法,如贝叶斯优化和强化学习,通常需要训练多个性质预测器,并且在纳入子结构约束方面存在困难。受大语言模型(LLMs)在文本生成领域成功的启发,我们提出了ChatMol,这是一种新颖的方法,利用大语言模型在多种约束条件下进行分子设计。首先,我们构建了一种与大语言模型兼容的分子表示形式,并在多个在线大语言模型上验证了其有效性。随后,我们针对各种受约束的分子生成任务开发了特定的提示词,以进一步微调当前的大语言模型,同时整合从性质预测中获得的反馈学习。最后,为了解决大语言模型在数值识别方面的局限性,我们参考位置编码方法,在提示词中对数值进行额外编码。在单性质、子结构 - 性质和多性质约束任务上的实验结果表明,ChatMol始终优于包括基于变分自编码器(VAE)和强化学习的方法在内的最先进基线模型。值得注意的是,在多目标结合亲和力最大化任务中,ChatMol针对蛋白质靶点ESR1实现了显著更低的KD值0.25,同时保持了最高的整体性能,比先前的方法提高了4.76%。此外,通过数值增强,指定的性质值与生成分子的性质值之间的皮尔逊相关系数提高了0.49。这些发现凸显了大语言模型作为通用分子生成框架的潜力,为基于传统潜在空间和强化学习的方法提供了有前景的替代方案。
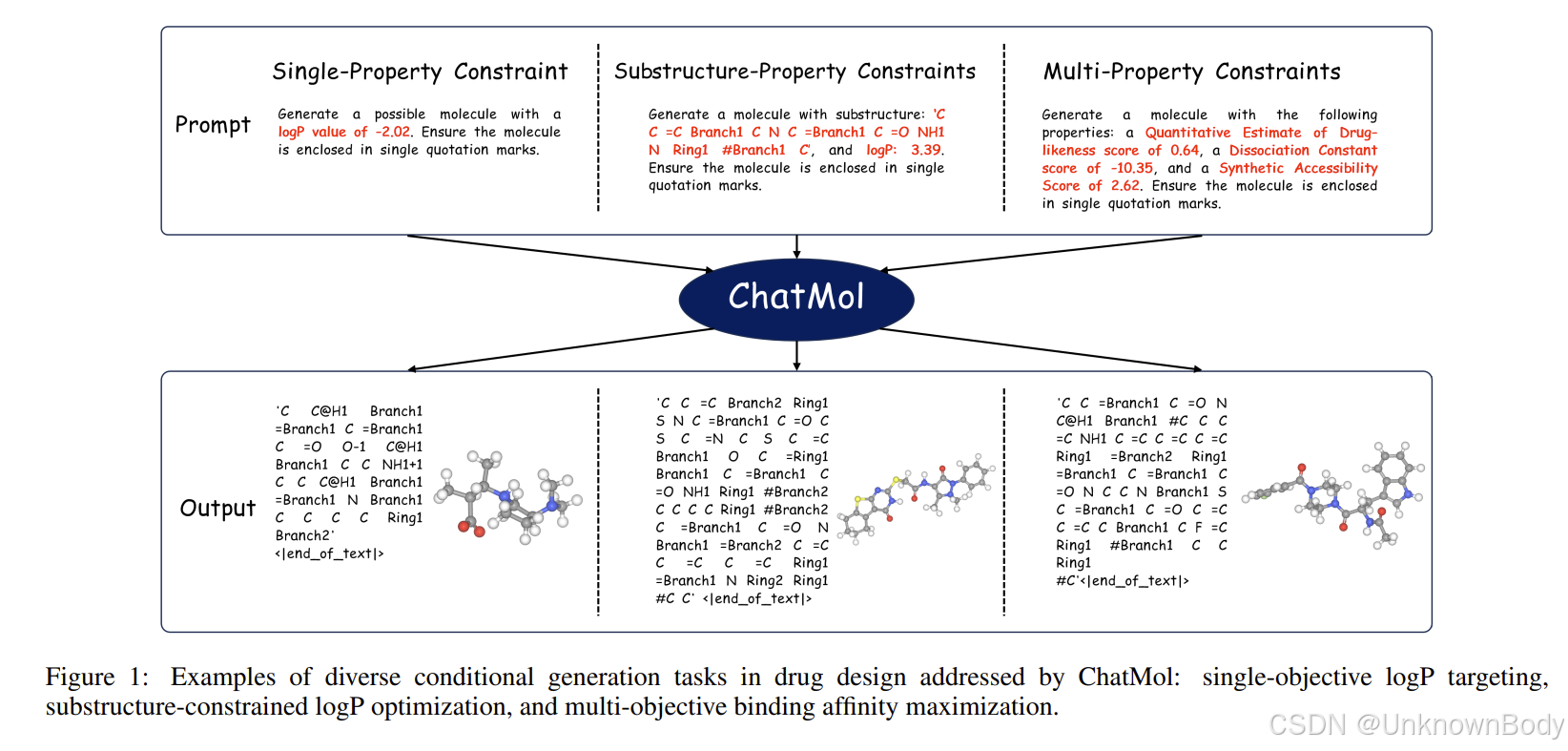
引言
探索小分子的化学空间以发现新药和新材料,是药理学和人工智能辅助科学研究中的关键问题。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4265
4265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











