




《DEEPSEEK原生应用与智能体开发实践 图书》【摘要 书评 试读】- 京东图书
在上一节(自回归生成模型中的推理加速详解-优快云博客)中,我们详细探讨了自回归模型的计算负担,以及如何通过缓存优化技术来减轻这种负担。显然,在模型计算过程中,若使用完整序列,会显著增加计算量。而缓存技术的引入,正是为了解决这个问题。
接下来,我们将通过实现带有缓存功能的经典自回归模型——GPT-2,来具体展示缓存优化带来的效果。我们将编写GPT-2模型的完整代码,并在使用和未使用缓存技术的情况下,分别进行序列生成测试。
通过对比实验,我们可以直观地看到缓存技术在减少内存占用和提高计算效率方面的显著效果。具体来说,我们将记录并分析两种情况下模型进行序列生成时的内存占用情况和所需时间。
在模型实现过程中,我们会重点关注如何将之前的计算结果存储起来,并在后续的计算中重用这些结果,从而减少重复计算。这种优化不仅可以加快模型的推理速度,还能显著降低内存消耗,尤其是在处理长序列时效果更为显著。
实验结束后,我们将对比数据进行分析,用具体数字说话,展示缓存优化在实际应用中的价值。通过这样的实践,我们可以更加深入地理解缓存技术在自然语言处理任务中的重要性,以及它如何帮助我们更有效地利用计算资源,提升模型的性能。
8.3.1 经典自回归模型详解
GPT-2模型是经典的基于自回归架构的语言模型,以其出色的文本生成能力而备受瞩目。我们首先从自回归的角度出发,深入剖析其工作原理与魅力所在。GPT-2模型架构如图8-7所示。
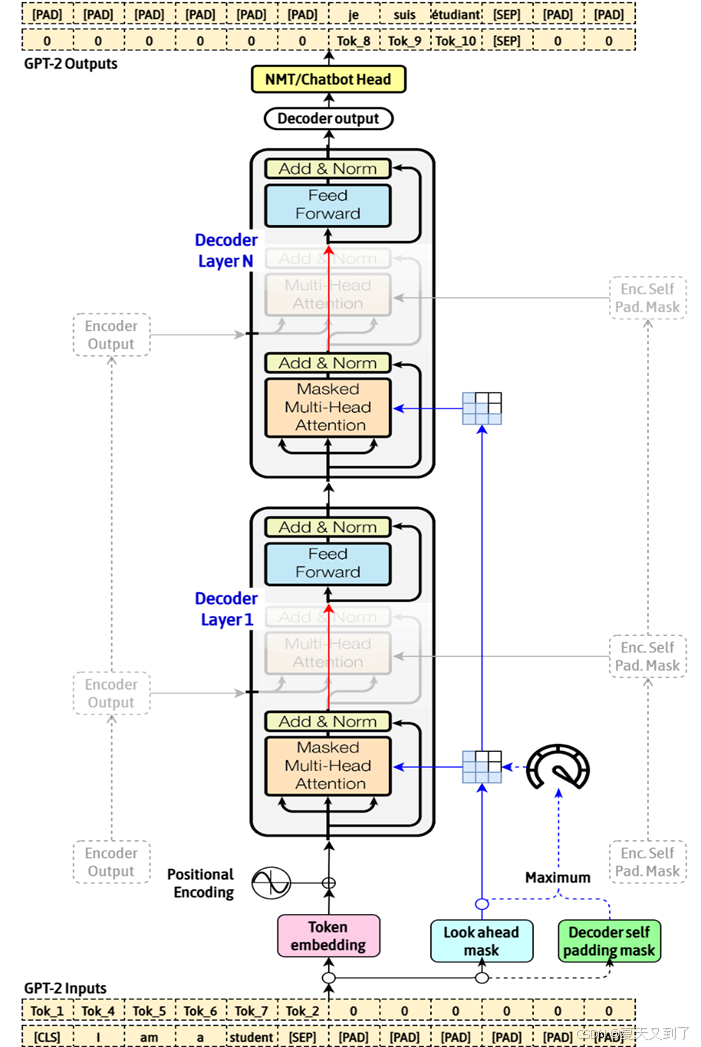
图8-7 GPT-2模型架构
首先,谈及自回归,不得不提及其核心理念:基于过往信息来推测未来的结果。在GPT-2模型中,这一理念被淋漓尽致地体现出来。模型在生成文本时,会紧密依托先前已生成的文本内容,精准预测下一个词语的出现概率。这种预测方式不仅确保了文本的连贯性,更赋予了模型一种“记忆”过往并据此推演的智能。
进一步探究发现,GPT-2所依托的自回归架构为其强大的文本生成能力奠定了坚实基础。特别是Transformers的Decoder部分,通过自注意力机制的运用,使得模型能够捕捉到文本中的长距离依赖关系,进而生成更加自然、流畅的文本。这种机制就像模型的“内心之眼”,能够洞察文本中的深层结构和语义联系。
此外,GPT-2模型在处理序列数据时,巧妙地引入了位置嵌入的概念。这一设计确保了模型能够深刻理解词汇在句子中的位置的重要性,从而生成语法正确、语义通顺的文本。位置嵌入就如同模型的“指南针”,指引着词汇在句子中的正确位置。
值得一提的是,GPT-2的预训练过程是在无监督的环境下进行的。这意味着模型仅依靠文本本身进行学习,无须额外的任务标签。这种学习方式赋予了模型极高的通用性和适应性,使其能够轻松应对各种下游任务。
8.3.2 能够减少空间占用的自回归模型代码完整实现
带有缓存的GPT-2模型,其实现代码如下所示,读者可以参看代码中的注释来理解:
import torch
from torch import einsum
from torch import nn
from einops import rearrange, reduce, repeat
import math
# 多头注意力机制的实现
class MultiheadAttention(nn.Module):
def __init__(self, hidden_size: int, num_heads: int):
super().__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads # 每个头的维度
assert self.head_size * num_heads == hidden_size # 确保总维度正确
self.attentionLL = nn.Linear(hidden_size, num_heads*self.head_size*3) # 生成Q、K、V的线性层
self.outputLL = nn.Linear(num_heads*self.head_size, hidden_size) # 输出线性层
# 前向传播
def forward(self, x: torch.Tensor, past_key_values = None, return_key_values = False):
# 输入形状: [batch, seq_length, hidden_size]
if past_key_values is None:
# 如果没有past_key_values,计算当前的Q、K、V
# 形状: batch seq_len hidden_size*3
KQV = self.attentionLL(x)
# 重新排列形状: batch num_heads seq_len head_size three
KQV = rearrange(KQV, "batch seq_len (three num_heads head_size) -> batch num_heads seq_len head_size three ",
num_heads=self.num_heads, three=3)
Q = KQV[:, :, :, :, 0] # 提取Q
K = KQV[:, :, :, :, 1] # 提取K
V = KQV[:, :, :, :, 2] # 提取V
# 计算注意力模式: batch num_heads seq_len seq_len
attention_pattern = einsum('b n s h, b n t h -> b n s t', K, Q)
# 缩放注意力模式
attention_pattern = attention_pattern / math.sqrt(self.head_size)
# 仅允许Masked自注意力(当前时间步只能看到过去的时间步)
attention_pattern = torch.triu(attention_pattern) + (-1e4) * torch.tril(torch.ones_like(attention_pattern), diagonal=-1)
# 应用Softmax
attention_pattern = torch.nn.Softmax(dim=2)(attention_pattern)
# 计算注意力加权值: batch num_heads seq_len head_size
out = einsum('b n k q, b n k h -> b n q h', attention_pattern, V)
# 重新排列形状: batch seq_len (num_heads head_size)
out = rearrange(out, 'batch num_heads seq_len head_size -> batch seq_len (num_heads head_size)')
# 线性变换输出
out = self.outputLL(out)
if return_key_values:
# 如果需要返回K和V(用于缓存)
assert x.shape[0] == 1 # 只支持单个batch
return out, torch.cat((K, V), dim=3) # 合并K和V
else:
return out
else:
# 如果有past_key_values,用于缓存(如生成任务)
assert x.shape == (1, 1, self.hidden_size) # 只支持单个时间步
kqv = self.attentionLL(x)
# 重新排列形状
kqv = rearrange(kqv, "batch seq_len (three num_heads head_size) -> batch num_heads seq_len head_size three ",
num_heads=self.num_heads, three=3)
q = kqv[0, :, :, :, 0] # 提取Q
k = kqv[0, :, :, :, 1] # 提取K
v = kqv[0, :, :, :, 2] # 提取V
# 从past_key_values中获取之前的K和V
oldK, oldV = torch.split(past_key_values, (self.head_size, self.head_size), dim=2)
# 拼接新的K和V
K = torch.cat((oldK, k), dim=1)
V = torch.cat((oldV, v), dim=1)
# 计算注意力模式
attention_pattern = einsum('n s h, n t h -> n s t', q, K)
attention_pattern = attention_pattern / math.sqrt(self.head_size)
attention_pattern = torch.nn.Softmax(dim=2)(attention_pattern)
# 计算注意力加权值
out = einsum('n s t, n t h -> n s h', attention_pattern, V)
# 重新排列形状
out = rearrange(out, '(batch num_heads) seq_len head_size -> batch seq_len (num_heads head_size)', batch=1)
# 线性变换输出
out = self.outputLL(out)
if return_key_values:
# 如果需要返回新的K和V
return out, torch.cat((k, v), dim=2).unsqueeze(0)
else:
return out
# GPT-2块,包括多头注意力和前馈网络
class GPT2Block(nn.Module):
def __init__(self, hidden_size: int, num_heads: int,
dropout: float, layer_norm_epsilon: float):
super().__init__()
self.ln1 = nn.LayerNorm(hidden_size, eps=layer_norm_epsilon) # 第一层归一化
self.attn = MultiheadAttention(hidden_size, num_heads) # 多头注意力
self.ln2 = nn.LayerNorm(hidden_size, eps=layer_norm_epsilon) # 第二层归一化
self.linear1 = nn.Linear(hidden_size, hidden_size * 4) # 前馈网络的第一层
self.linear2 = nn.Linear(hidden_size * 4, hidden_size) # 前馈网络的第二层
self.dropout = nn.Dropout(dropout) # Dropout层
# 前向传播
def forward(self, x: torch.Tensor, past_key_values = None, return_key_values = False):
if return_key_values:
# 如果需要返回K和V(用于缓存)
res = x # 保存残差连接
x, keyvals = self.attn(self.ln1(x), past_key_values=past_key_values, return_key_values=True) # 注意力层
x = x + res # 残差连接
# 前馈网络
x = x + self.dropout(self.linear2(torch.nn.functional.gelu(self.linear1(self.ln2(x)))))
return x, keyvals
else:
# 如果不需要返回K和V
x = x + self.attn(self.ln1(x), past_key_values=past_key_values, return_key_values=False) # 注意力层
x = x + self.dropout(self.linear2(torch.nn.functional.gelu(self.linear1(self.ln2(x))))) # 前馈网络
return x
# GPT-2模型
class GPT2(nn.Module):
def __init__(self, num_layers = 6, num_heads = 6, vocab_size = 4000,
hidden_size = 384, max_position_embeddings = 1024, dropout = 0.1,
layer_norm_epsilon = 1e-9, use_cache=False):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, hidden_size) # 词嵌入
self.position_embedding = nn.Embedding(max_position_embeddings, hidden_size) # 位置嵌入
self.dropout = nn.Dropout(dropout) # Dropout层
# 多层GPT-2块
self.GPTBlocks = nn.Sequential(
*[GPT2Block(hidden_size, num_heads, dropout, layer_norm_epsilon)
for i in range(num_layers)]
)
self.layer_norm = nn.LayerNorm(hidden_size, layer_norm_epsilon) # 最后一层归一化
self.use_cache = use_cache #是否使用缓存
self.head_size = hidden_size // num_heads # 每个头的维度
self.num_layers = num_layers # 层数
self.num_heads = num_heads # 头数
self.reset_kv_cache() # 初始化缓存
# 重置缓存
def reset_kv_cache(self):
self.past_key_values = torch.zeros((self.num_layers, self.num_heads, 0, 2 * self.head_size))
# 前向传播
def forward(self, input_ids): # 输入形状: [batch, seq_len]
if not self.use_cache:
# 如果不使用缓存
tokens = self.token_embedding(input_ids) # 词嵌入
batch, seq_len = input_ids.shape
# 位置嵌入
position_ids = repeat(torch.arange(seq_len), 's -> b s', b = batch).to(input_ids.device)
positions = self.position_embedding(position_ids)
embedding = tokens + positions # 嵌入叠加
x = self.dropout(embedding) # Dropout
x = self.GPTBlocks(x) # 通过GPT-2块
self.last_token_encodings = x # 保存最后的编码
final_encodings = self.layer_norm(x) # 归一化
# 计算logits
logits = einsum('b s d, v d -> b s v', final_encodings, self.token_embedding.weight)
return (logits, final_encodings)
else:
# 如果使用缓存
if self.past_key_values.shape[2] == 0:
# 如果缓存为空,初始化处理
tokens = self.token_embedding(input_ids) # 词嵌入
batch, seq_len = input_ids.shape
# 位置嵌入
position_ids = repeat(torch.arange(seq_len), 's -> b s', b = batch).to(input_ids.device)
positions = self.position_embedding(position_ids)
embedding = tokens + positions # 嵌入叠加
x = self.dropout(embedding) # Dropout
new_key_values = [] # 保存新的K和V
# 依次处理每个GPT-2块
for gptblock in self.GPTBlocks:
x, new_key_value = gptblock(x, return_key_values=True)
new_key_values.append(new_key_value)
self.past_key_values = torch.cat(new_key_values, dim=0) # 更新缓存
final_encodings = self.layer_norm(x) # 归一化
# 计算logits
logits = einsum('b s d, v d -> b s v', final_encodings, self.token_embedding.weight)
return (logits, final_encodings)
else:
# 如果缓存不为空,处理新的时间步
tokens = self.token_embedding(input_ids[:, -1:]) # 仅处理最后一个时间步
batch, seq_len = input_ids.shape
# 位置嵌入(仅处理最后一个时间步)
position_ids = repeat(torch.arange(seq_len), 's -> b s', b = batch).to(input_ids.device)
positions = self.position_embedding(position_ids[:, -1:])
embedding = tokens + positions # 嵌入叠加
x = self.dropout(embedding) # Dropout
new_key_values = [] # 保存新的K和V
# 依次处理每个GPT-2块
for i, gptblock in enumerate(self.GPTBlocks):
x, new_key_value = gptblock(x,
past_key_values=self.past_key_values[i, :, :, :],
return_key_values=True)
new_key_values.append(new_key_value)
new_key_values = torch.cat(new_key_values, dim=0) # 合并新的K和V
self.past_key_values = torch.cat((self.past_key_values, new_key_values), dim=2) # 更新缓存
final_encodings = self.layer_norm(x) # 归一化
# 计算logits
logits = einsum('b s d, v d -> b s v', final_encodings, self.token_embedding.weight)
return (logits, final_encodings)
在上面代码中,我们使用了缓存优化技术past_key_values,目的在减少重复计算,从而提高推理效率。
8.3.3 缓存使用与传递过程详解
GPT-2是经典的自回归生成模型。一般在生成任务中,模型通常逐个词生成序列,缓存机制可以避免在每一步都从头计算所有之前的键(Key)和值(Value),而是复用之前的结果。下面我们详细讲解GPT-2中缓存机制的使用。
1. 缓存初始化
缓存初始化在reset_kv_cache方法中完成:
def reset_kv_cache(self):
self.past_key_values = torch.zeros((self.num_layers, self.num_heads, 0, 2 * self.head_size))past_key_values是一个四维张量,形状为(num_layers, num_heads, 0, 2 * head_size):
- num_layers:GPT-2的层数。
- num_heads:每层中多头注意力的头数。
- 0:缓存的初始长度为0,表示没有存储任何历史键值。
- 2 * head_size:每一层的键值对(K和V)被拼接在一起,维度是2 * head_size。
2. 缓存的使用逻辑
缓存的使用逻辑主要在forward方法中实现:
1)缓存为空时的初始化
if self.past_key_values.shape[2] == 0:
tokens = self.token_embedding(input_ids)
batch, seq_len = input_ids.shape
position_ids = repeat(torch.arange(seq_len), 's -> b s', b = batch).to(input_ids.device)
positions = self.position_embedding(position_ids)
embedding = tokens + positions
x = self.dropout(embedding)
new_key_values = []
for gptblock in self.GPTBlocks:
x, new_key_value = gptblock(x, return_key_values=True)
new_key_values.append(new_key_value)
self.past_key_values = torch.cat(new_key_values, dim=0)
上面代码解释如下:
- 初始化嵌入:输入的编码(token_embedding和position_embedding)被计算。
- 逐层处理:每层GPT-2块(GPT2Block)都会返回新的键值对(new_key_value)。
- 缓存更新:新的键值对被收集到new_key_values中,并最终拼接到self.past_key_values。
2)缓存不为空时的处理
代码如下所示:
else:
tokens = self.token_embedding(input_ids[:, -1:])
batch, seq_len = input_ids.shape
position_ids = repeat(torch.arange(seq_len), 's -> b s', b = batch).to(input_ids.device)
positions = self.position_embedding(position_ids[:, -1:])
embedding = tokens + positions
x = self.dropout(embedding)
new_key_values = []
for i, gptblock in enumerate(self.GPTBlocks):
x, new_key_value = gptblock(x,
past_key_values=self.past_key_values[i, :, :, :],
return_key_values=True)
new_key_values.append(new_key_value)
new_key_values = torch.cat(new_key_values, dim=0)
self.past_key_values = torch.cat((self.past_key_values, new_key_values), dim=2)
上面代码解释如下:
- 处理新的输入:只处理当前时间步的输入(input_ids[:, -1:])。
- 复用缓存:每层GPT-2块(GPT2Block)接收当前时间步的输入和之前的键值对(past_key_values)。
- 生成新的键值对:当前时间步的键值对(K和V)被计算并返回。
- 缓存更新:新的键值对被添加到past_key_values中。
3)缓存的传递
缓存的传递主要发生在以下两部分:
(1)在MultiheadAttention的forward方法中,缓存通过past_key_values参数传递:
if past_key_values is not None:
assert x.shape == (1, 1, self.hidden_size) # 只支持单个时间步
kqv = self.attentionLL(x)
kqv = rearrange(kqv, "batch seq_len (three num_heads head_size) -> batch num_heads seq_len head_size three ", num_heads=self.num_heads, three=3)
q = kqv[0, :, :, :, 0] # 提取Q
k = kqv[0, :, :, :, 1] # 提取K
v = kqv[0, :, :, :, 2] # 提取V
oldK, oldV = torch.split(past_key_values, (self.head_size, self.head_size), dim=2)
K = torch.cat((oldK, k), dim=1) # 拼接旧的K和新的K
V = torch.cat((oldV, v), dim=1) # 拼接旧的V和新的V
在这里主要完成了以下几个步骤:
- 提取当前K和V:从当前时间步的输入中提取K和V。
- 拼接旧K和新K:将之前缓存的K(oldK)和当前的K拼接在一起。
- 拼接旧V和新V:将之前缓存的V(oldV)和当前的V拼接在一起。
(2)在GPT2Block的forward方法中,缓存通过past_key_values参数传递:
x, new_key_value = gptblock(x, past_key_values=past_key_values, return_key_values=True)如果past_key_values非空,GPT2Block会将之前的K和V与当前的K和V拼接在一起。
4)最后在每次计算新的Key和Value后,缓存都会更新:
new_key_values = torch.cat(new_key_values, dim=0)
self.past_key_values = torch.cat((self.past_key_values, new_key_values), dim=2)上面代码解释如下:
- 拼接新的K和V:新的键值对被拼接到缓存中。
- 维度扩展:缓存的长度(第三维)增加,对应新的时间步。
可以看到,生成模型中的缓存机制通过保存历史的键值对(Key和Value),避免了在生成任务中重复计算旧的Key和Value。这种优化显著提高了生成任务的推理速度,尤其是在处理长序列时。缓存的管理和更新是实现这一优化的关键,确保在每一步中都只计算当前时间步的键值对,并复用之前的缓存。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









