




在大规模智能体系统中,单个Agent的行为偏离不仅可能导致局部功能失常,更可能在信息与决策层面蔓延,污染整个集群的输出质量与可靠性。面对这一现实威胁,传统的被动监控与事后纠偏方法显得力不从心。因而,需要将“免疫”理念引入智能体架构,设计一套能在运行时快速识别、精准隔离并安全恢复的机制,像生物免疫系统一样保护集群免受“胡言乱语”Agent的扩散性影响。本文从威胁建模、检测策略、隔离与缓解、恢复与溯源、系统设计与实践落地五个维度展开,提出一条可实施、可扩展的工程化路径。
一、威胁建模:何为“胡言乱语”的Agent及其风险传染路径
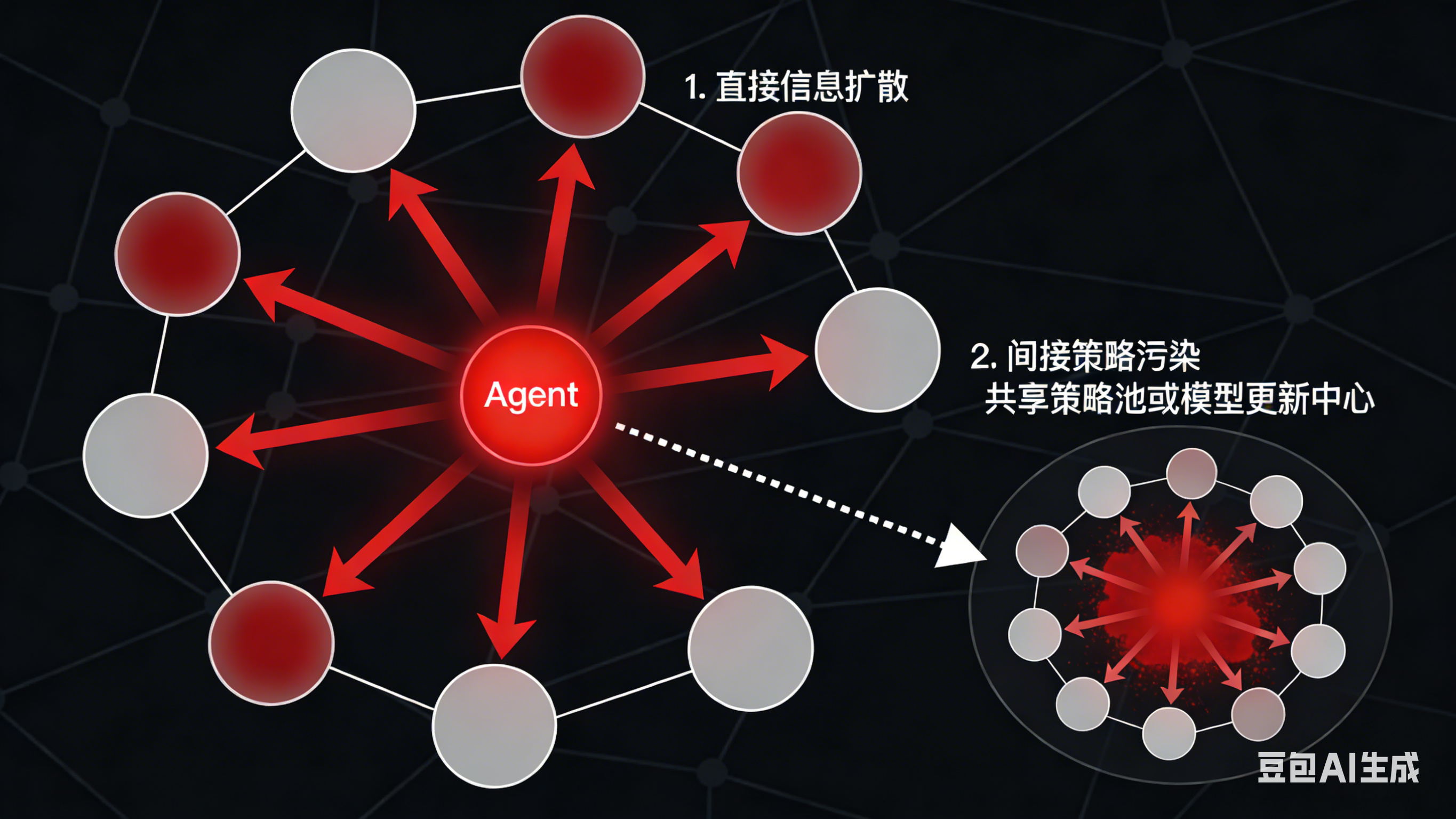
要设计有效的免疫系统,首先要界定何为“胡言乱语”。这里将其定义为:Agent在输入、推理或输出环节产生与任务语义或事实显著偏离的结果,且这种偏差在时间或空间上具有扩散潜能。偏差来源可包括模型内部参数异常、输入数据篡改、Prompt注入、资源竞争导致的退化、以及环境变化使得策略失效等。风险传染路径则分为直接信息扩散和间接策略污染两类:前者指异常输出被其他Agent作为输入继承,从而直接传播错误信息;后者指异常Agent改变共享策略或模型更新,导致集群性能系统性下降。理解这些路径有助于设计检测触发点与防御优先级。
二、检测策略:多模态、层次化与渐进式的信号融合
单一检测手段往往难以兼顾灵敏度与精确性。有效的检测应当采用多模态信号融合,并在系统层次上做出区分。主要检测维度包括:
-
输出一致性检测:利用参考模型或历史轨迹对Agent当前输出进行一致性评估。参考可以是较高置信度的专家模型、集群中多数投票的结果,或本地缓存的近期高质量响应。通过统计偏差、语义相似度与事实校验三类判据,来衡量输出的可疑程度。
-
行为异常检测:监控Agent的内部运行指标(推理时间、内存占用、梯度幅度等)与交互模式(请求频率、输入复杂度、对外调用次数)。这些元数据常常在模型发生内部故障或受
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











