




DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
要使用深度学习与语音特征进行抽取,首先需要准备能够对语音特征进行解析的工具。
Librosa是一个用于音频、音乐分析与处理的Python工具包,常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。Librosa提供了多种音频读取和写入的方法,支持多种音频格式的读取和写入,如WAV、FLAC、MP3等。Librosa提供了多种音频特征提取的方法,如MFCC、Chromagram等。此外,Librosa还提供了多种音频可视化的方法,如绘制声谱图、绘制频谱图等。
下面将使用Librosa完成音频信号的特征提取和可视化,并对其涉及的内容进行详细讲解。
15.1.1 基于Librosa的音频信号读取
音频信号是日常生活中最常见且人们接触最多的信号类型,它们以具有频率、带宽、分贝等参数的音频信号形式存在。典型的音频信号可以表示为振幅随时间变化的函数,如图15-1所示。
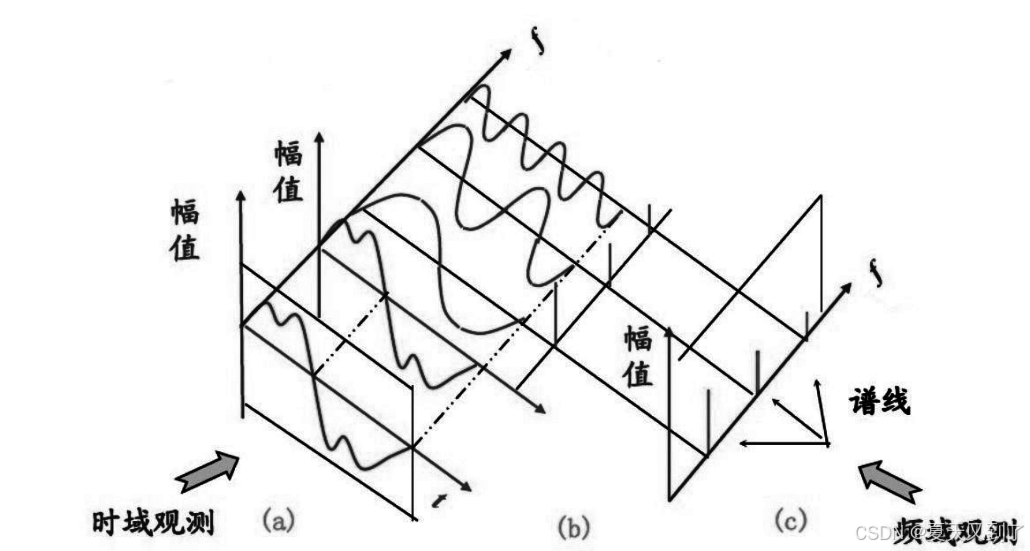
图15-1 音频信号的分解
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4033
4033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









