







【图书推荐】《深入探索Mamba模型架构与应用》-优快云博客
Mamba能用在什么场景
Mamba架构在以下场景中具有显著优势:
(1)长序列数据处理与生成
在需要处理超长文本、视频或时序数据的场景中,Mamba通过选择性状态空间机制(SSM)和Hybrid-Mamba-Transformer架构,能有效降低计算复杂度,减少KV-Cache缓存占用,从而提升训练和推理效率。
典型应用包括大语言模型的上下文理解、长视频内容分析等,例如腾讯混元Turbo S模型即采用该架构实现高性价比的长文本处理。
(2)自动驾驶场景语义补全(SSC)
面对动态交通参与者的突发行为和复杂环境遮挡问题,Mamba可增强自动驾驶系统的场景理解能力,通过推理缺失的几何和语义信息,提升车辆对周围环境的感知全面性。
(3)多模态检索任务
在文本-视频检索等跨模态任务中,Mamba结合端到端学习框架(如CLIP4Clip),可优化视频帧特征提取效率,减少过拟合风险,提升跨模态对齐精度。
(4)具身智能机器人
通过端到端VLA模型与机器人硬件结合,Mamba能够支持高自由度机械臂在多样化商业场景中的实时感知与操作,例如智平方Alpha Bot系列产品已实现该技术的商业化落地。
(5)高并发实时系统
状态空间模型(SSM)的特性使Mamba适合处理时间序列依赖强、需低延迟响应的场景,如实时传感器数据处理或工业自动化控制。
说明:以上场景均基于Mamba架构在长序列建模、高效计算和跨模态融合方面的核心优势,结合具体行业需求形成差异化竞争力。 这块内容来源于DeepSeek大模型生成内容。
Mamba带来了新的突破
Mamba是一种新型的深度学习模型,它通过选择性状态空间模型(Selective State Space Models,SSMs)来改进传统的状态空间模型。Mamba模型下载网站为https://github.com/state-spaces/mamba,其下载页面如图1-3所示。
图1-3 Mamba下载页面
以下是Mamba模型的核心思想和架构的简单介绍。
1. 核心思想
Mamba的核心思想是利用选择性机制来实现更高效和灵活的序列建模。与传统的SSMs不同,Mamba的SSMs参数是根据输入进行动态调整的,从而使模型能够根据当前数据选择性地传递或遗忘信息。这种选择性机制使得Mamba能够更好地处理离散和信息密集型数据,如文本。
2. 架构
- 固定主干:Mamba的架构包括一个固定的主干,用于从一个隐藏状态到下一个隐藏状态的转换。这个主干是由一个矩阵A定义的,它允许跨序列进行预计算,从而提高计算效率。
- 输入相关转换:输入对下一个隐藏状态的影响是通过一个矩阵B来定义的。与传统的SSMs不同,Mamba的矩阵B是根据当前输入进行动态调整的,从而使模型能够更好地适应不同的输入数据。
- 选择性机制:选择性机制是Mamba的关键组成部分。它通过对SSM参数进行输入依赖的调整,使模型能够根据当前数据选择性地传播或遗忘信息。这种选择性机制使得Mamba能够更好地处理长序列数据,并提高模型的性能。
- 硬件感知算法:为了满足选择性机制的计算需求,Mamba使用了一种硬件感知算法。该算法使用扫描操作而不是卷积来循环执行计算,从而在GPU上实现了高效的计算。
总的来说,Mamba是一种基于选择性状态空间模型的深度学习模型,它通过选择性机制和硬件感知算法来实现更高效和灵活的序列建模。
这些突破使得Mamba在处理长序列数据时具有更高的效率和性能,为深度学习模型的发展带来了新的可能性。它在自然语言处理、音频处理、视频内容生成等领域都有着广泛的应用前景,并在多个领域都取得了很好的性能,是一种非常有前途的深度学习模型。
现在,我们将进一步开展Mamba的基本学习,带领读者逐步掌握这款强大的工具。
首先,我们将手把手教你如何完成第一次使用Mamba预训练模型的基本操作,以文本生成任务为起点,开启你的Mamba之旅。在这个过程中,你将亲身体验到Mamba如何快速、准确地生成流畅自然的文本内容,感受其强大的语言生成能力。
然后,我们将详细介绍Mamba的三大核心模块。这三大模块是Mamba功能的基石,了解它们将为你更深入地使用Mamba打下坚实的基础。我们会逐一剖析每个模块的工作原理、功能特点以及应用场景,让你对Mamba有一个全面而系统的认识。
通过学习这三大模块,你将能够更好地理解Mamba的运行机制,从而更加熟练地运用它来完成各种复杂的自然语言处理任务。无论是文本生成、文本分类,还是情感分析、问答系统等,Mamba都能为你提供强大的支持。
让我们共同踏上Mamba的学习之旅,探索自然语言处理的无限可能。
Hello Mamba:使用预训练Mamba模型生成实战
Hello Mamba!为了让读者能够顺利与Mamba接触,作者准备了一段实战代码供读者学习,读者首先需要打开Miniconda Prompt控制台界面,安装我们所需的类库modelscope和Mamba库。具体的安装代码如下:
conda install modelscope
conda install Mamba 之后在PyCharm新建一个可执行的Python程序,直接输入作者提供的代码。注意,这里snapshot_download函数可以直接下载对应的存档,而AutoTokenizer.from_pretrained需要使用本书提供的文件。
import model
from model import Mamba
from modelscope import snapshot_download,AutoTokenizer
model_dir = snapshot_download('AI-ModelScope/mamba-130m', cache_dir="./mamba/")
mamba_model = Mamba.from_pretrained("./mamba/AI-ModelScope/mamba-130m")
tokenizer = AutoTokenizer.from_pretrained('./mamba/tokenizer')
print(model.generate(mamba_model, tokenizer, 'Mamba is the'))这里需要提示一下,在上述代码段中,Mamba is the是起始内容,然后根据所输入的起始内容输出后续的文本,当然读者也可以自行定义起始句子,如下所示:
Mamba is the player on the side as he provides a lot of offense for the Dukes and also does some awesome blocking that the Mamba must work hard to avoid. This unit is a must for any offensive player to have when playing on the d1 side另外,这里做一个预告,目前使用训练好的Mamba生成中文内容尚不可行。在后续章节中,我们将详细讲解Mamba在文本生成任务中的应用,到时会提供这方面的解决方案。读者可以按照章节顺序循序渐进地学习相关内容。
构建Mamba的三大模块说明
接下来,我们将深入了解Mamba模型。通过文本生成任务,我们可以看到Mamba展现出了令人瞩目的性能,这主要得益于其内部三种核心模块的精妙融合。每个模块都设计独到,通过协同作用,赋予了Mamba卓越的学习和泛化能力。这种精心的组合不仅提高了模型处理复杂任务的准确性,还增强了其稳定性和效率,使Mamba能在多个领域中发挥出色的表现,如图2-30所示。
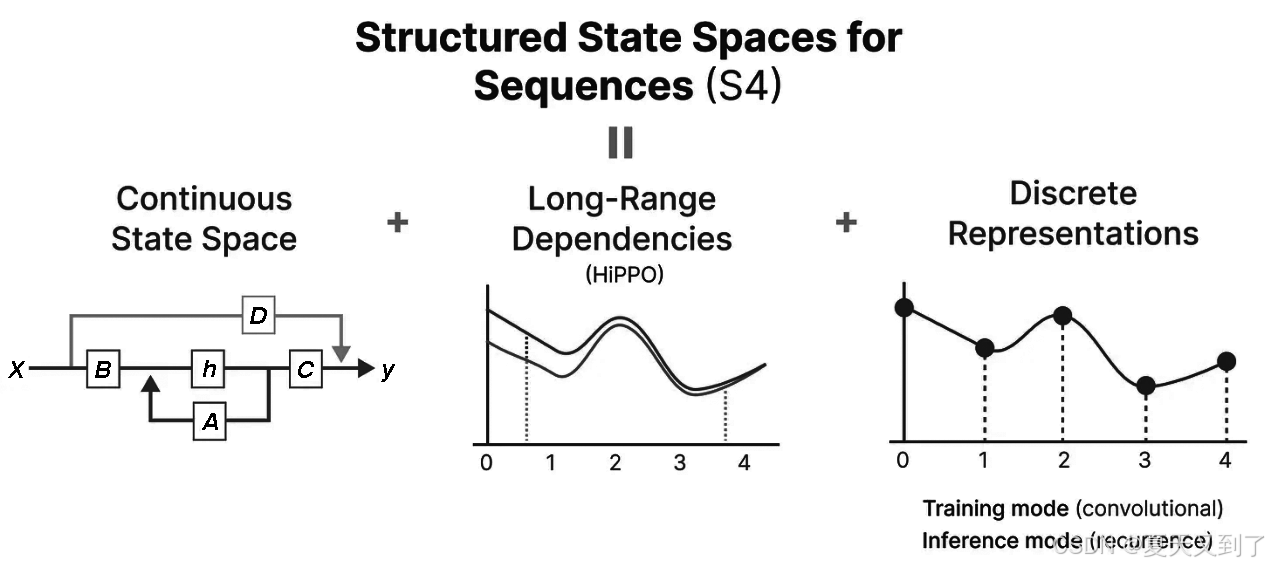
图2-30 Mamba的组成构建
- 首先是状态空间模型(SSM),它为Mamba提供了强大的动态系统建模能力,使得网络能够更好地理解和模拟复杂数据的内在状态变化。状态空间模型通过捕捉系统的动态行为,为Mamba带来了对序列数据的深入洞察能力。
- 为了创建循环的离散化方法,Mamba采用了先进的离散化技术。这项技术不仅提高了模型的计算效率,还使得Mamba能够灵活地使用循环进行计算,从而适应不同类型的数据和任务需求。通过这种离散化方法,Mamba在处理序列数据时展现出了更高的灵活性和准确性。
- 最后,Mamba引入了HiPPO(High-order Polynomial Projection Operator)算法对状态转移矩阵进行初始化,这一创新技术的运用显著增强了模型处理远程依赖关系(long-range dependencies)的能力。在处理长序列数据时,远程依赖关系的捕捉是至关重要的,而HiPPO通过高效压缩历史信息为系数向量,使得Mamba能够轻松应对这一挑战。
因此,在了解组建Mamba架构的基本模块的基础上,Mamba的基本内容可以总结如下。
1. 基本思想
Mamba代表的是“结构化状态空间序列建模”,它是一种新型的神经网络架构,专为处理非常长的序列而设计,如视觉、语言和音频数据。
Mamba的核心思想是,通过将长序列数据压缩成更紧凑的表示形式,从而更有效地捕获长距离依赖关系。
2. 工作原理
在传统的序列模型中,如RNN或LSTM,信息的传递是逐步的,这可能导致在处理非常长的序列时出现信息丢失或梯度消失的问题。
Mamba通过使用高阶多项式来近似输入信号,从而能够在有限的内存预算内压缩长序列的信息。这种方法允许模型在接收到更多信号时,仍然能够在有限的内存中对整个信号进行压缩和处理。
3. 性能表现
Mamba架构在处理包含数万个元素的长序列时表现出了令人印象深刻的能力。例如,在某些基准测试中,S4能够准确地推理出包含16 000多个元素的长序列,显示出其强大的长距离依赖捕获能力。
4. 应用潜力
Mamba架构由于其出色的长序列处理能力,在需要处理长距离依赖关系的任务中具有巨大的应用潜力。这包括语音识别、自然语言处理、时间序列预测等领域,其中对长序列数据的理解和建模至关重要。
可以看到,Mamba通过状态空间模型、HiPPO以及先进的离散化技术的有机结合,构建了一个强大而灵活的神经网络模型,为处理复杂序列数据提供了新的解决方案。后面将分别对其进行讲解。


















 2999
2999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









