




Denoising Diffusion Probabilistic Models (DDPM)
1. 标题与摘要
1.1 核心信息
- 标题:去噪扩散概率模型
- 作者:Jonathan Ho, Ajay Jain, Pieter Abbeel (UC Berkeley)
- 代码:https://github.com/hojonathanho/diffusion
1.2 核心贡献
- 理论创新:
- 建立扩散模型与去噪得分匹配(Denoising Score Matching)和Langevin动力学的等价性。
- 提出加权变分下界目标函数(§3.4)。
- 性能突破:
- CIFAR10:Inception Score 9.46,FID 3.17(无条件生成SOTA)。
- 256×256 LSUN:样本质量媲美ProgressiveGAN。
- 新视角:
- 扩散采样过程可解释为渐进有损解压(Progressive Lossy Decompression),泛化自回归解码。
2. 引言
2.1 生成模型背景
- 现有模型(GANs/VAEs/自回归/流模型)在图像合成上取得进展,但扩散模型此前未证明能生成高质量样本。
2.2 扩散模型定义
- 前向过程(扩散过程):
q ( x 1 : T ∣ x 0 ) : = ∏ t = 1 T N ( x t ; 1 − β t x t − 1 , β t I ) q(\mathbf{x}_{1:T}|\mathbf{x}_{0}) := \prod_{t=1}^{T} \mathcal{N}(\mathbf{x}_{t}; \sqrt{1-\beta_{t}} \mathbf{x}_{t-1}, \beta_{t} \mathbf{I}) q(x1:T∣x0):=t=1∏TN(xt;1−βtxt−1,βtI)
逐步添加高斯噪声(方差表 β 1 : T \beta_{1:T} β1:T 固定或可学)。 - 反向过程:
p θ ( x 0 : T ) : = p ( x T ) ∏ t = 1 T N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) p_{\theta}(\mathbf{x}_{0:T}) := p(\mathbf{x}_{T}) \prod_{t=1}^{T} \mathcal{N}(\mathbf{x}_{t-1}; \boldsymbol{\mu}_{\theta}(\mathbf{x}_{t}, t), \Sigma_{\theta}(\mathbf{x}_{t}, t)) pθ(x0:T):=p(xT)t=1∏TN(xt−1;μθ(xt,t),Σθ(xt,t))
学习从噪声重建数据的马尔可夫链。
2.3 本文贡献
- 首次证明扩散模型可生成高质量样本(优于部分已有模型)。
- 关键发现:通过 ϵ \epsilon ϵ-预测参数化,建立与去噪得分匹配的显式联系(§3.2)。
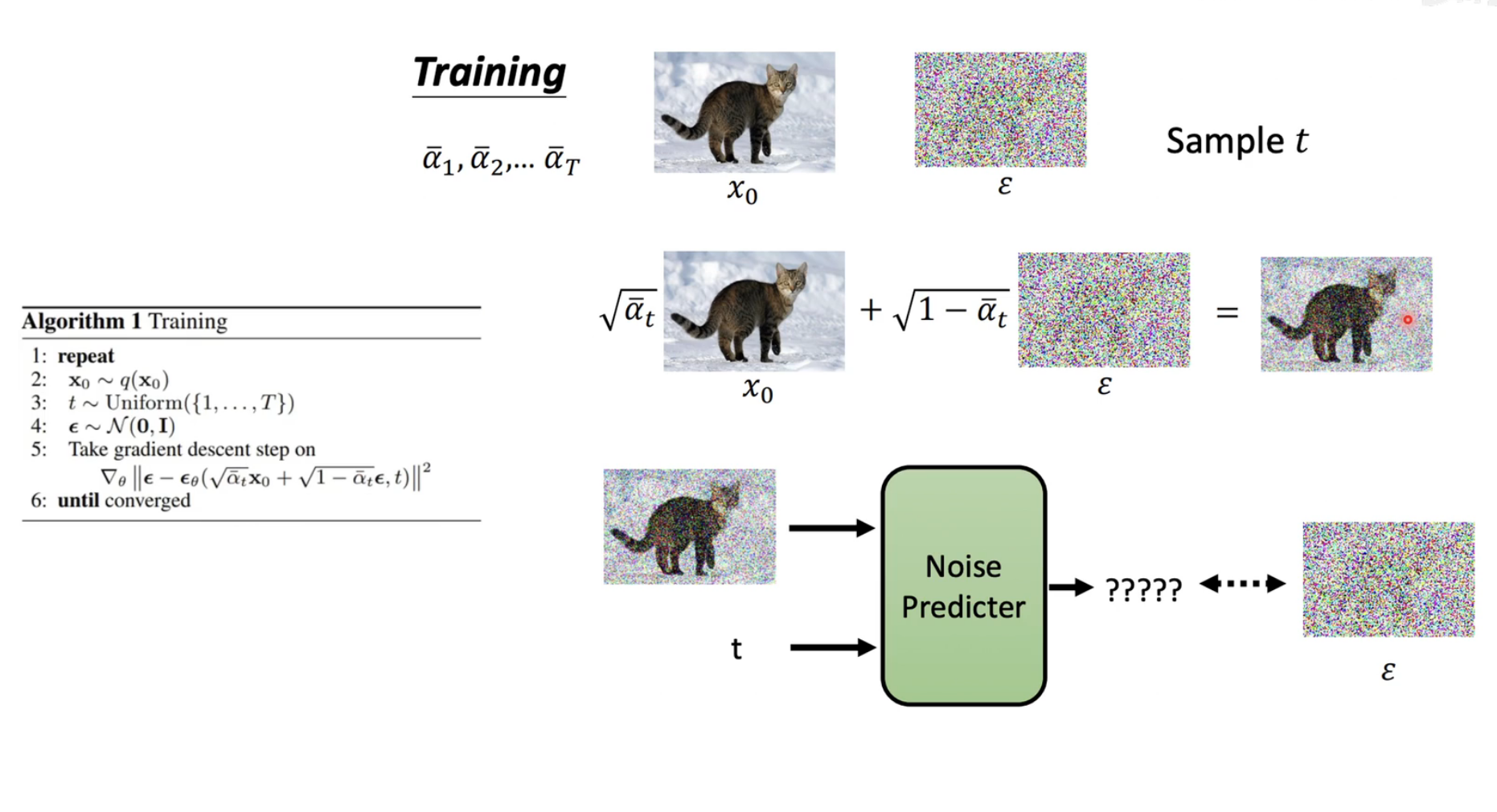
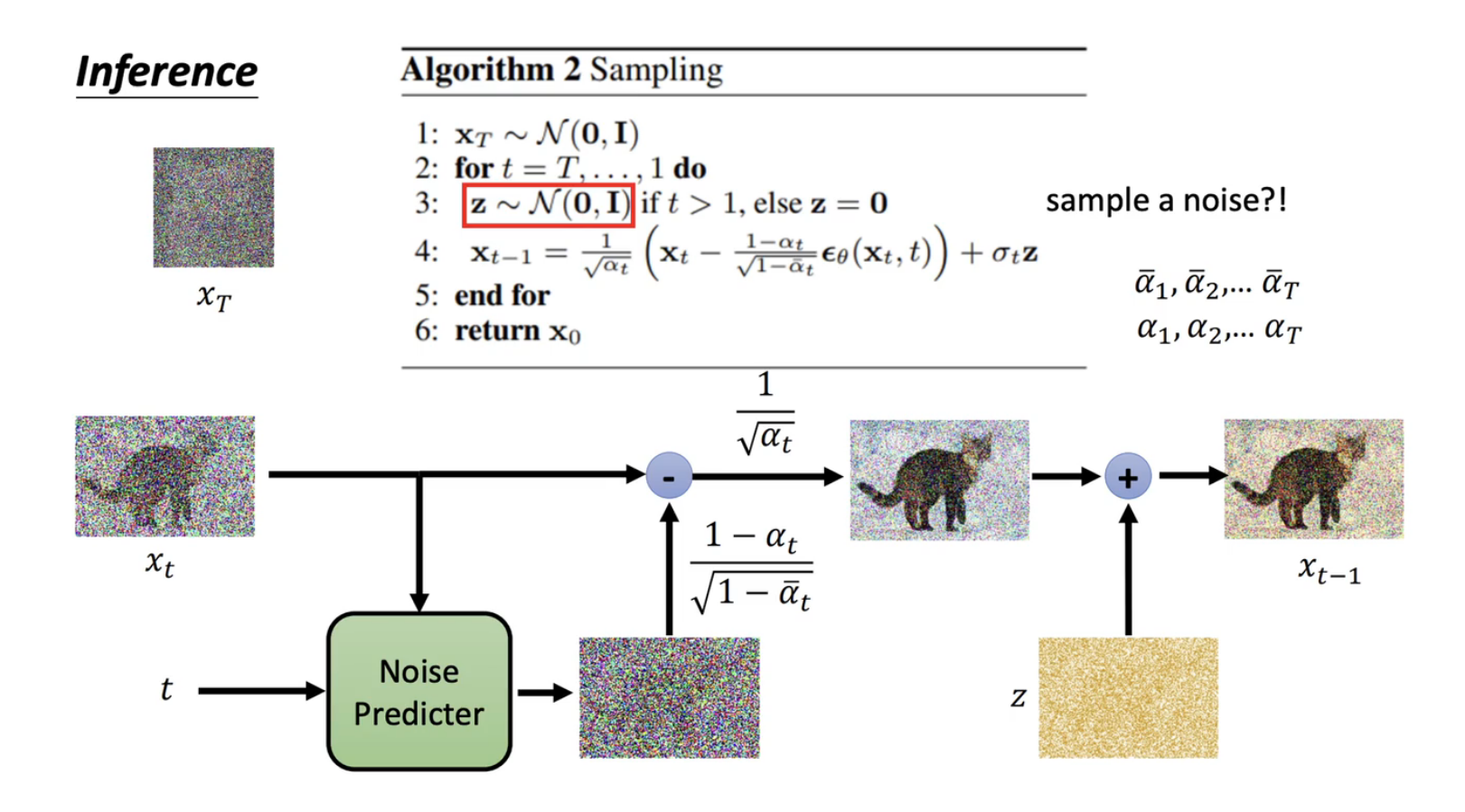
3. 背景
3.1 数学框架
| 符号 | 定义 |
|---|---|
| x 0 \mathbf{x}_{0} x0 | 原始数据 |
| x 1 : T \mathbf{x}_{1:T} x1:T | 隐变量(同维噪声) |
| q ( x t ∣ x t − 1 ) q(\mathbf{x}_{t}|\mathbf{x}_{t-1}) q(xt∣xt−1) | 前向转移(加噪) |
| p θ ( x t − 1 ∣ x t ) p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}) pθ(xt−1∣xt) | 反向转移(去噪) |
3.2 训练目标
优化变分下界(ELBO):
E [ − log p θ ( x 0 ) ] ≤ E q [ − log p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] = : L \mathbb{E}[-\log p_{\theta}(\mathbf{x}_{0})] \leq \mathbb{E}_{q} \left[ -\log \frac{p_{\theta}(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T}|\mathbf{x}_{0})} \right] =: L E[−logpθ(x0)]≤Eq[−logq(x1:T∣x0)pθ(x0:T)]=:L
方差缩减形式:
L = E q [ D KL ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) ⏟ L T + ∑ t > 1 D KL ( q ( x t − 1 ∣ x t , x 0 ) ∥ p θ ( x t − 1 ∣ x t ) ) ⏟ L t − 1 − log p θ ( x 0 ∣ x 1 ) ⏟ L 0 ] L = \mathbb{E}_{q} \left[ \underbrace{D_{\text{KL}}(q(\mathbf{x}_{T}|\mathbf{x}_{0}) \parallel p(\mathbf{x}_{T}))}_{L_{T}} + \sum_{t>1} \underbrace{D_{\text{KL}}(q(\mathbf{x}_{t-1}|\mathbf{x}_{t}, \mathbf{x}_{0}) \parallel p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}))}_{L_{t-1}} - \underbrace{\log p_{\theta}(\mathbf{x}_{0}|\mathbf{x}_{1})}_{L_{0}} \right] L=Eq
LT
DKL(q(xT∣x0)∥p(xT))+t>1∑Lt−1
DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−L0
logpθ(x0∣x1)
3.3 闭式性质
前向过程任意步采样:
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(\mathbf{x}_{t}|\mathbf{x}_{0}) = \mathcal{N}(\mathbf{x}_{t}; \sqrt{\bar{\alpha}_{t}} \mathbf{x}_{0}, (1 - \bar{\alpha}_{t}) \mathbf{I}) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
其中 α t : = 1 − β t \alpha_{t} := 1 - \beta_{t} αt:=1−βt, α ˉ t : = ∏ s = 1 t α s \bar{\alpha}_{t} := \prod_{s=1}^{t} \alpha_{s} αˉt:=∏s=1tαs。
4. 扩散模型与去噪自编码器
这一部分是整篇论文的核心,它建立了扩散模型与去噪分数匹配之间的深刻联系,并由此引出了简化且高效的训练目标。本章旨在为扩散模型的具体实现做出设计和论证。作者回答了三个关键问题:
- 前向过程的方差 β t \beta_t βt 应该如何设定?(对应 L T L_T LT)
- 反向过程(模型) 应该如何参数化和训练?(对应 L 1 : T − 1 L_{1:T-1} L1:T−1)
- 如何计算最终的数据对数似然?(对应 L 0 L_0 L0)
4.1 Forward process and L T L_T LT (前向过程与 L T L_T LT)
- 内容:作者选择将前向过程的方差 β t \beta_t βt 固定为常数,而不是作为可学习的参数。
- 原因:
- 简化问题:前向过程 q q q 因此不再包含任何可学习参数,成为一个固定的(预定义的)噪声添加过程。
- L T L_T LT 成为常数:损失函数中的 L T = D K L ( q ( x T ∣ x 0 ) ∥ p ( x T ) ) L_T = D_{KL}(q(x_T | x_0) \| p(x_T)) LT=DKL(q(xT∣x0)∥p(xT)) 衡量的是前向过程最终分布与先验分布(标准高斯分布)的差异。由于 q q q 和 p p p 都是固定的高斯分布,它们的KL散度是一个可以预先计算的常数,在训练过程中不需要优化,可以忽略。
- 实践意义:这大大简化了训练过程,我们只需要关注反向过程的训练 ( L 0 L_0 L0 到 L T − 1 L_{T-1} LT−1)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









