










1. 高级语言优化的本质:语义压缩与可预测性
- 目标:通过编译器中间表示(IR)将高层抽象(如动态类型、垃圾回收)静态化,转化为更接近机器语义的确定性操作(如SSA形式、显式内存布局)。
- 关键技术:
- 类型特化(Type Specialization):将动态类型检查转为静态类型推断(如Python的Cython)。
- 内存模型扁平化:将高级语言的对象图(Object Graph)分解为连续的机器内存块(如Java的逃逸分析后栈上分配)。
- 控制流线性化:将异常处理、协程等复杂控制流转换为跳转表或状态机(如C++协程的编译期状态机展开)。
2. 操作系统优化的本质:硬件语义的虚拟化与暴露
- 目标:在硬件透明性与资源抽象之间找到平衡点,减少“抽象惩罚”(Abstraction Penalty)。
- 关键技术:
- 硬件能力直通(Capability Pass-through):如DPDK绕过内核协议栈直接暴露网卡DMA队列给用户态。
- 语义下沉:将传统由OS管理的资源(如线程调度、内存分页)部分下沉到硬件(如Intel VT-d的I/O虚拟化或ARM的Memory Tagging Extension)。
- 系统调用批处理:通过内核旁路(Kernel Bypass)技术(如io_uring)将多次系统调用合并为单次硬件指令流。
3. 两者的协同优化:编译器-OS-硬件的垂直整合
- 案例1:语言运行时与OS的协同
Java的ZGC垃圾回收器依赖OS的内存屏障(如Linux的membarrier系统调用)实现并发标记,此时编译器需生成硬件感知型代码(如x86的MFENCE指令),将GC的“安全点”语义与CPU的缓存一致性协议对齐。 - 案例2:异构计算的统一抽象
CUDA/OpenCL的编译器将高级语言(如C++ AMP)的并行for循环映射为GPU的SIMT指令,同时OS需提供用户态驱动模型(如NVIDIA的UMD)避免内核上下文切换,此时语义压缩需同时考虑编译器(循环分块)、OS(零拷贝DMA)和硬件(Warp调度)。
4. 未来趋势:可重构硬件的语义动态性
- 随着CXL、Chiplet等技术的普及,硬件资源本身可能动态重组(如内存池化、加速器热插拔)。此时:
- 编译器需支持运行时重编译(如LLVM JIT针对新硬件拓扑重新布局数据结构)。
- OS需暴露硬件拓扑感知API(如Linux的numactl扩展为chiplet-aware调度)。
总结:高级语言与OS的优化不是单向“缩小差距”,而是通过分层语义协商(Compiler-OS-Hardware Co-Design)实现动态平衡。未来的关键挑战是如何在可编程硬件(如FPGA、DSA)上让高层抽象与底层实现形成可演化的语义契约。
你提到的这两种优化思路,本质上是计算机系统分层设计中“语义鸿沟”(Semantic Gap)问题的解决方向,核心是通过减少不同层级间的抽象差异,提升系统整体效率。以下从具体内涵、实现方式和典型案例展开说明:
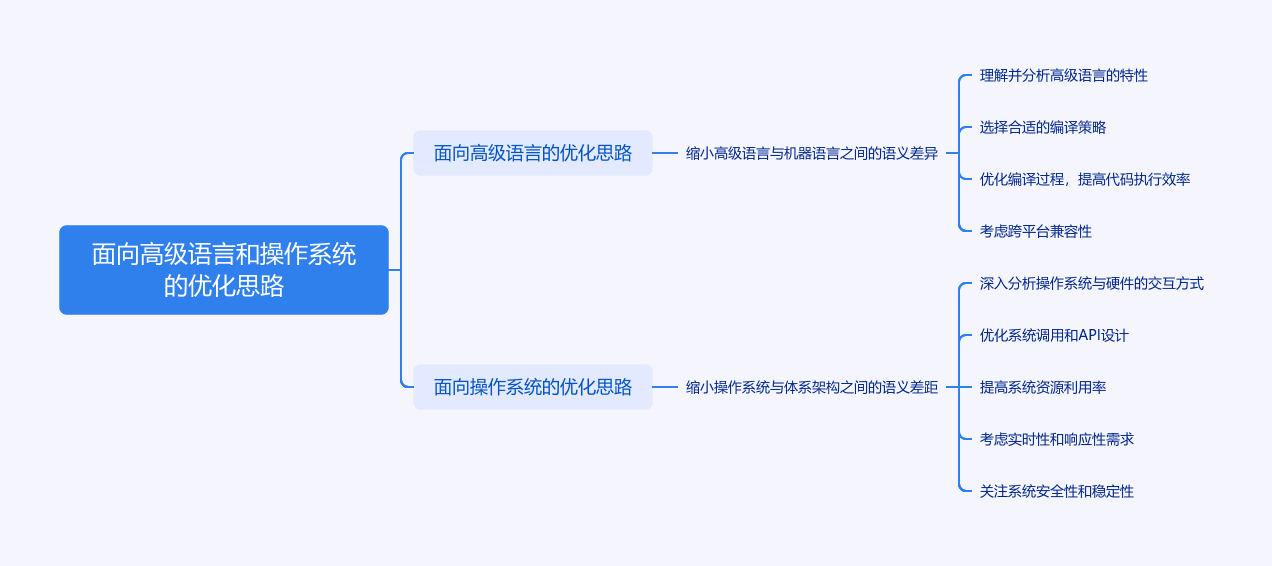
一、面向高级语言的优化:缩小与机器语言的语义差异
高级语言(如Python、Java、C++)通过抽象屏蔽了硬件细节(如内存地址、寄存器操作),但这种抽象与机器语言(二进制指令)的底层语义存在天然差异(例如高级语言的“对象”“函数调用”在机器语言中需转化为内存操作、栈帧管理等)。优化的目标是让高级语言的语义更贴近机器可直接执行的逻辑,减少转换过程中的开销。
核心实现思路:
-
编译器/解释器优化
- 通过静态分析(如类型推断、数据流分析)将高级语言的抽象语义“降维”为更接近机器的操作。例如:
- 把高级语言的“循环”转化为机器语言的“条件跳转+寄存器自增”,减少冗余指令;
- 对面向对象的“方法调用”进行虚函数表优化或内联展开,避免间接寻址的开销(C++的
inline关键字即为此思路)。
- 通过静态分析(如类型推断、数据流分析)将高级语言的抽象语义“降维”为更接近机器的操作。例如:
-
语言设计层面的调整
- 引入贴近硬件的语义元素,例如Rust的“所有权”机制直接映射内存管理逻辑,减少垃圾回收(GC)这种高级抽象带来的性能损耗;
- 动态语言(如Python)通过JIT(即时编译)将频繁执行的代码片段编译为机器码,弥合“解释执行”与“直接运行”的差距(如PyPy解释器)。
-
库与运行时优化
- 高级语言的标准库(如C++的STL、Java的JDK)底层用机器友好的代码实现(如C语言),将高级语义(如“容器遍历”)转化为高效的内存访问模式(如连续地址遍历)。
二、面向操作系统的优化:缩小与体系架构的语义差距
操作系统是硬件(体系架构,如x86、ARM)与应用程序的中间层,其核心功能(如进程调度、内存管理、设备驱动)需要直接与硬件交互。但操作系统的抽象语义(如“进程”“虚拟内存”)与硬件的物理特性(如CPU核心、物理内存地址、中断机制)存在差异,优化的目标是让操作系统的逻辑更贴合硬件的工作方式,减少“抽象适配”的成本。
核心实现思路:
-
内核与硬件特性的深度绑定
- 针对特定体系架构的硬件特性设计内核机制,例如:
- 利用CPU的“中断向量表”优化操作系统的中断处理流程,避免软件层面的冗余判断;
- 结合CPU的“缓存层次结构”(L1/L2/L3缓存)设计内存分配算法(如Linux的SLAB分配器),减少缓存未命中(Cache Miss)的开销。
- 针对特定体系架构的硬件特性设计内核机制,例如:
-
抽象语义的硬件化实现
- 将操作系统的关键抽象通过硬件直接支持,减少软件模拟的开销。例如:
- 虚拟内存原本是操作系统通过页表实现的抽象,而CPU的“内存管理单元(MMU)”直接硬件化这一逻辑,通过硬件地址转换加速虚拟地址到物理地址的映射;
- 进程调度中的“上下文切换”,通过CPU的“特权级模式”(如x86的Ring0-Ring3)和专用寄存器(如CR3)实现快速切换,避免纯软件切换的耗时。
- 将操作系统的关键抽象通过硬件直接支持,减少软件模拟的开销。例如:
-
驱动与设备模型的优化
- 操作系统的设备驱动需要匹配硬件的接口规范(如PCIe、USB协议),通过“设备树”(Device Tree)或“ACPI”等机制将硬件的物理特性(如寄存器地址、中断号)直接映射到操作系统的设备管理语义中,减少驱动程序的适配成本(如Linux对ARM架构的设备树支持)。
三、两种优化的共性与关联
两者本质上是**“自顶向下”与“自底向上”的协同优化**:
- 高级语言优化聚焦“应用层→机器层”的语义衔接,操作系统优化聚焦“系统层→硬件层”的语义衔接;
- 最终目标一致:减少跨层级的语义转换开销,提升系统效率。例如,Linux内核(操作系统)为x86架构优化后,C语言(高级语言)编译的程序能更高效地调用系统调用,形成“语言→系统→硬件”的语义闭环。
这种思路在嵌入式系统、高性能计算等场景尤为重要——例如实时操作系统(RTOS)需极致缩小与硬件的语义差距,才能保证任务调度的微秒级响应;而高性能语言(如CUDA)则通过直接映射GPU的并行计算语义,实现接近硬件极限的算力利用。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











