










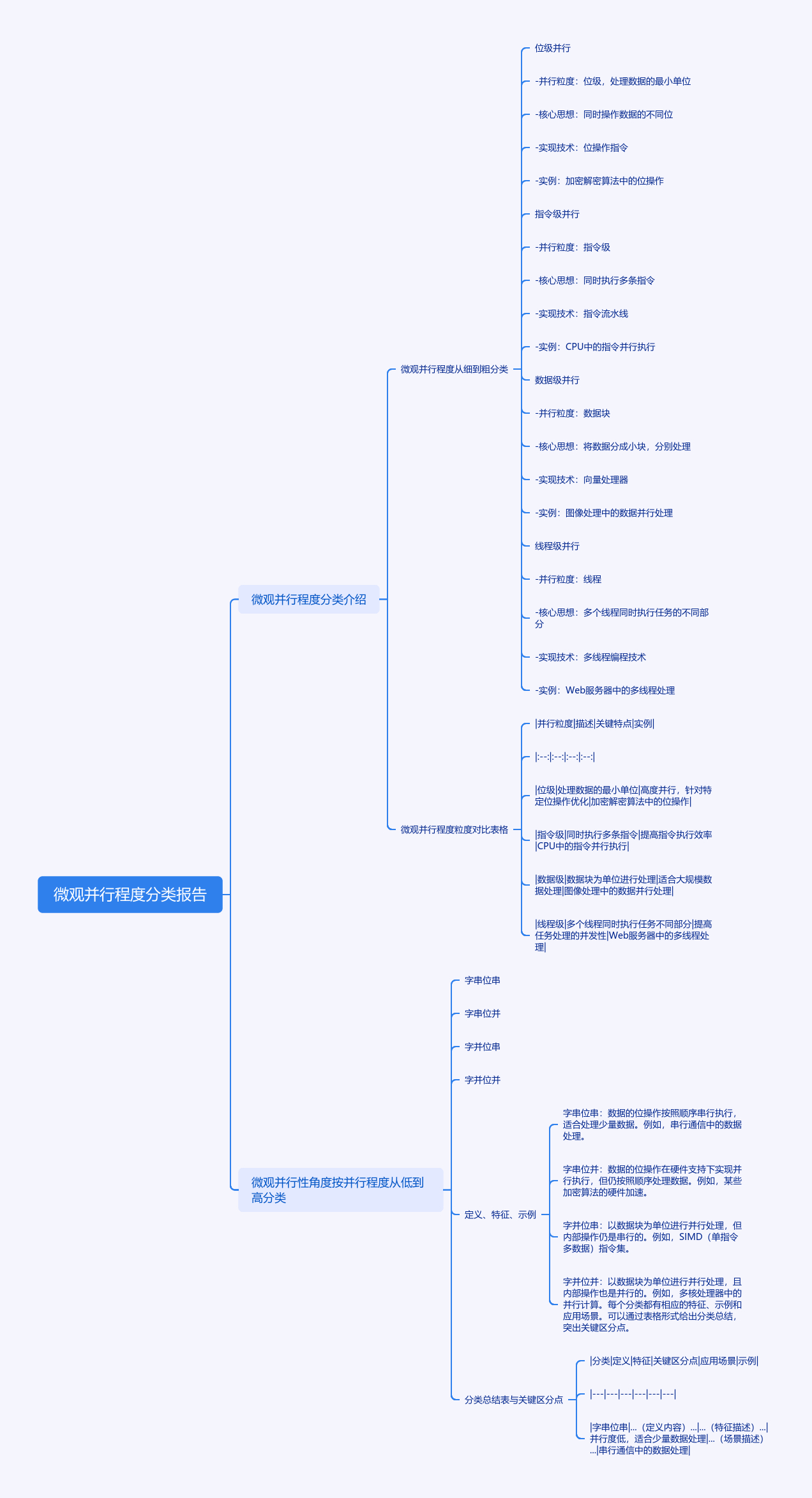
从微观角度(主要聚焦于处理器内部的并行机制,涉及硬件层面的细粒度并行),按并行程度(即并行操作的“粒度”,粒度越细表示并行处理的基本单元越小)可分为以下几类,从细到粗排列如下:
1. 位级并行(Bit-Level Parallelism, BLP)
- 并行粒度:最细,以“位”为基本单位。
- 核心思想:通过扩展数据的位宽,实现对多个位的并行操作。早期计算机字长较短(如8位、16位),随着技术发展,字长扩展到32位、64位甚至更长,本质是利用硬件电路的并行性同时处理更多位的数据。
- 实现技术:硬件层面通过加宽数据通路(如寄存器、总线、ALU的位宽)实现。例如,64位处理器的ALU可同时对64位数据的每一位进行运算(如加法中的进位并行处理)。
- 实例:32位加法器同时计算32位二进制数的和,相比8位加法器,一次操作可处理4倍的位数据,体现了位级并行的提升。
2. 指令级并行(Instruction-Level Parallelism, ILP)
- 并行粒度:中等偏细,以“指令”为基本单位,关注多条指令之间的并行执行。
- 核心思想:在单处理器(或单核)中,通过硬件或软件技术,让没有依赖关系的多条指令同时或重叠执行,提升指令吞吐量。
- 实现技术:
- 流水线技术:将一条指令的执行拆分为多个阶段(如取指、译码、执行、访存、写回),不同指令的不同阶段可并行处理(如指令1执行时,指令2译码,指令3取指)。
- 超标量技术:在一个时钟周期内发射多条指令(通过多个功能单元并行执行),例如超标量处理器可同时执行加法和乘法指令。
- 乱序执行:打破指令的顺序,优先执行无依赖的指令,减少等待时间。
- 实例:经典的5级流水线处理器,理论上每时钟周期可完成1条指令(理想状态);4发射超标量处理器,每时钟周期可执行4条无依赖的指令。
3. 数据级并行(Data-Level Parallelism, DLP)
- 并行粒度:中等,以“数据元素”为基本单位,针对“同一条指令对多个数据元素”的并行处理。
- 核心思想:当程序需要对一组数据(如数组)执行相同操作时,通过硬件支持让单条指令同时处理多个数据元素,避免重复执行指令。
- 实现技术:
- 向量处理器:通过向量寄存器和向量运算单元,一次指令处理整个向量(如对一个128元素的数组执行加法,只需一条向量加法指令)。
- SIMD(单指令多数据)指令集:如x86的SSE、AVX,ARM的NEON,通过扩展寄存器位宽(如256位寄存器),让单条指令同时处理8个32位整数或4个64位浮点数。
- 实例:AVX2指令集中的
vaddps指令,可同时对4个64位浮点数执行加法,相比标量指令(一次处理1个),效率提升4倍。
4. 线程级并行(Thread-Level Parallelism, TLP)
- 并行粒度:较粗,以“线程”为基本单位,关注多个线程的并行执行(线程是程序执行的基本单元,包含独立的指令流和数据)。
- 核心思想:在单个处理器芯片内集成多个核心(多核处理器),每个核心可独立执行一个线程,通过线程的并行提升整体性能。
- 实现技术:
- 多核处理器:每个核心是一个独立的处理单元(包含ALU、寄存器、缓存等),可并行执行不同线程。
- 超线程技术(Simultaneous Multi-Threading, SMT):在单个核心内通过共享功能单元,同时运行多个线程(如Intel的HT技术,一个核心模拟两个逻辑核心),隐藏线程的等待时间。
- 实例:4核处理器可同时执行4个线程;支持超线程的4核处理器(8线程),可同时处理8个线程(每个核心运行2个线程)。
总结:微观并行程度的粒度对比
| 并行类型 | 粒度(从细到粗) | 核心特点 | 典型硬件支持 |
|---|---|---|---|
| 位级并行(BLP) | 位 | 扩展数据位宽,并行处理多位 | 宽位宽ALU、寄存器 |
| 指令级并行(ILP) | 指令 | 多条指令重叠/同时执行 | 流水线、超标量、乱序执行 |
| 数据级并行(DLP) | 数据元素 | 单指令处理多个数据元素 | 向量处理器、SIMD指令集 |
| 线程级并行(TLP) | 线程 | 多个线程独立并行执行 | 多核处理器、超线程技术 |
从微观上看,并行程度的提升本质是通过减小并行单元的粒度(如从线程到指令再到位),或扩大单操作的处理范围(如从单个数据到多个数据),充分利用硬件资源提高效率。
从微观(指令级或数据级)并行性的角度,按并行程度从低到高可分为以下四类:
1. 字串位串(WSBS)
- 定义:每次仅处理一位数据(位串),且指令严格串行执行。
- 特征:
- 无并行性,逐位操作。
- 早期串行计算机(如位串行处理器)的典型模式。
- 示例:4位加法逐位进位计算,每次处理1位。
2. 字串位并(WSBP)
- 定义:一次处理一个数据字(如32位整数),但字内各位并行处理(位并),指令仍串行。
- 特征:
- 位级并行:ALU同时处理所有位(如32位加法器一次完成运算)。
- 指令级串行:每条指令顺序执行,无指令重叠。
- 示例:传统单核CPU的标量运算(如
ADD R1, R2对32位寄存器并行计算)。
3. 字并位串(WPBS)
- 定义:多个数据字(字并)同时处理,但每个字内部按位串行(位串)。
- 特征:
- 数据级并行:SIMD(单指令多数据)的变体,如早期向量处理器。
- 位串行:每个数据字的运算仍为串行位操作。
- 示例:8个8位数据并行处理,但每个8位数据内部逐位计算(罕见,多为历史设计)。
4. 字并位并(WPBP)
- 定义:多个数据字并行处理(字并),且每个字内各位并行运算(位并)。
- 特征:
- 最高并行度:结合SIMD(数据并行)和位级并行。
- 现代架构:GPU的SIMD单元(如32个线程同时执行32位浮点加法)。
- 示例:NVIDIA GPU的warp(32线程)执行
FP32加法,所有位和数据通道并行。
分类总结表
| 类型 | 位处理 | 字处理 | 典型场景 |
|---|---|---|---|
| WSBS | 串行 | 串行 | 位串行处理器 |
| WSBP | 并行 | 串行 | 单核标量CPU |
| WPBS | 串行 | 并行 | 历史向量机(位串行设计) |
| WPBP | 并行 | 并行 | 现代GPU/SIMD架构 |
关键区分点
- 位并行:字内各位是否同时处理(如32位加法器 vs 逐位计算)。
- 字并行:多个数据字是否同时处理(如SIMD的4个32位整数 vs 单指令单数据)。
这一分类由Flynn(1972)在原有SIMD/MIMD基础上细化,适用于微观架构的并行性分析。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











