



1. 在 PyTorch 中,优化器(torch.optim)在处理参数时可以对不同的参数进行单独配置。
示例:
optimizer = torch.optim.SGD([
{"params":model[0].weight,'weight_decay': wd},
{"params":model[0].bias}],
lr=lr , )
优化器接收的参数是一个字典列表([{"params": ..., "配置1": ...}, {"params": ..., "配置2": ...}]),每个字典代表一组参数及其专属配置,以及全局配置(lr=lr), 优化器会合并全局配置和组内配置,按组迭代参数并更新,这种设计提高了控制参数的灵活性。
2. 对于某些特殊的误差(如:房价预测,股票收益),绝对化的数值衡量欠妥,不符合评判标准
(以预测房价为例,
真实值 100 万,预测值 110 万 → 绝对误差 10 万;
真实值 1000 万,预测值 1100 万 → 绝对误差 100 万,
但两者的相对误差都为10%)
这时,寻找相应的相对误差衡量方式对于模型训练更为有效:
Loss = 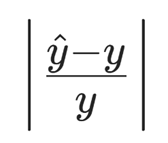
因为:
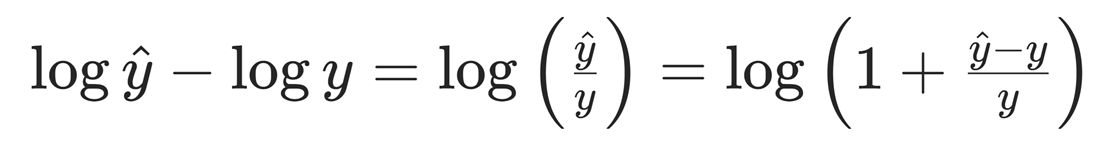
所以当Loss 很小时,取泰勒近似:
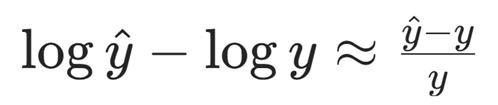
从而将Loss从差值尺度转化为对数尺度,预防了数值溢出。
3. 如果在训练模型时发生“损失曲线有时是正常指数衰减(损失稳步下降),有时呈噪声波形(损失剧烈波动)”的现象,表明模型训练时处于稳定拟合与不稳定拟合的临界处,核心原因在于训练中存在某些 “不稳定触发因素”, 微小的初始差异(如随机种子、数据批次、初始参数)就会导致训练走向两种极端。
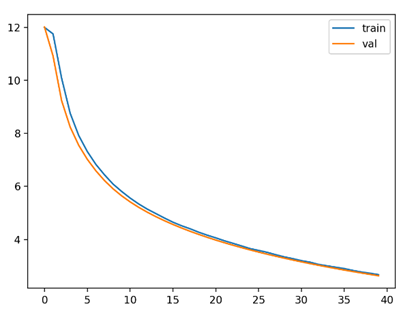
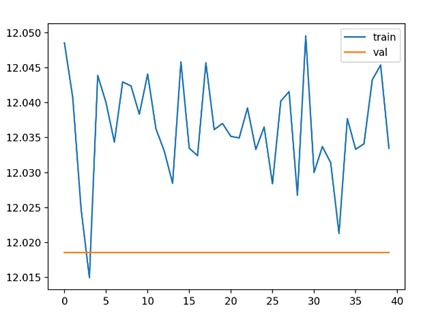
正常拟合时的损失曲线 异常拟合时的损失曲线
原因与解决方法;
1> 数据批次的分布不稳定,每次训练特征存在偏移:
增大batch_size的大小,减小数据的随机性,提高数据稳定性。
2> 学习率超过损失曲线稳定收敛的临界值:
设置更小的lr值,确保梯度下降在可控范围内。
3> 随机因素影响过大,如:固定了随机种子,过大的dropout概率:
尝试减小模型的随机性。
4> 模型存在梯度不稳定结构:
使用如torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=/*梯度所能达到的最大范数*/, norm_type=/*范数类型*/ )控制梯度
4. 在python pandas中使用pandas.get_dummies()为数据独热编码时,最好先将训练数据与验证数据合二为一,避免某一数据集存在另一个没有的特征类型,如:
颜色:
|
训练集 |
验证集 |
|
红 |
紫 |
|
蓝 |
红 |
如果已经转换,也可以使用使用pandas.DataFrame.align() 对齐,将参数join=设置为:outer #取并集 。
5. 独热编码可能导致特征维度激增(高基数类别特征会生成大量稀疏特征),增加模型学习难度,容易引发梯度波动。这时采用频率编码可以大大缩减内存开支,降低了数据的维度,使模型更容易捕捉到类别与目标变量之间的关系。
例如:
import pandas as pd
data = { 'category': ['A', 'B', 'A', 'C', 'B', 'A', 'D'] }
df = pd.DataFrame(data)
# 计算每个类别的频率
freq_map = df['category'].value_counts(normalize=True).to_dict()
# 进行频率编码
df['category_freq_encoded'] = df['category'].map(freq_map)
print(df)
# end
6. 在某些情况下需要模型仅输出正数(如:价格预测,年龄),而使用torch.clamp会中断范围外的梯度,这时在模型输出端末尾添加nn.ReLU()或nn.Softplus()可以在保证梯度存在的情况下将模型输出限制在正数。


















 2075
2075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









