 深度学习过拟合、欠拟合及正则化方法
深度学习过拟合、欠拟合及正则化方法




1.过拟合:训练集上拟合效果很好,但是测试集上拟合效果比训练集差很多
常见原因:数据量不足,模型过于复杂,正则化强度不够,这些原因都会导致模型训练更多的噪声。
2.欠拟合:模型学习能力不足,无法充分捕捉数据的复杂关系,表现为训练集和测试集上准确率都差。
解决办法:增加模型复杂度,增加特征数量,减小正则化强度,增加训练轮次或时间
3. L2正则化:L2 正则化通过在损失函数中添加权重参数的平方和来实现,目标是惩罚过大的参数值。
作用:防止过拟合,限制模型复杂度,提高模型的泛化能力,平滑权重分布
4.L1正则化:L1 正则化通过在损失函数中添加权重参数的绝对值之和来约束模型的复杂度。
L1,L2对比: L1 正则化 更适合用于产生稀疏模型,会让部分权重完全为零,适合做特征选择。 L2 正则化 更适合平滑模型的参数,避免过大参数,但不会使权重变为零,适合处理高维特征较为密集的场景。
5.Dropout:Dropout 是一种在训练过程中随机丢弃部分神经元的技术。它通过减少神经元之间的依赖来防止模型过于复杂,从而 避免过拟合。
1. 按照指定的概率把部分神经元的值设置为0;
2. 为了规避该操作带来的影响,需对非 0 的元素使用缩放因子 进行强化。
使用缩放因子 :训练阶段的期望输出值仍然是 x,与没有 Dropout 时一致
6.随机裁剪:transforms.RandomCrop(size=(224, 224)
7.随机水平裁剪:transforms.RandomHorizontalFlip(p=1) 以概论p翻转
8.调整图片颜色:transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
参数:brightness: 亮度调整的范围。
contrast: 对比度调整的范围。
saturation: 饱和度调整的范围。
hue: 色调调整的范围。 取值范围必须为 [-0.5, 0.5] (因为色相在 HSV 色彩空间中是循环的,超出范围会导致颜色异常)。
四者格式都可以 float 或 (min, max) 元组
9.归一化:标准化:将图像的像素值从原始范围(如 [0, 255] 或 [0, 1])转换为均值为 0、标准差为 1 的分布。
加速训练:标准化后的数据分布更均匀,有助于加速模型训练。
提高模型性能:标准化可以使模型更容易学习到数据的特征,提高模型的收敛性和稳定性。
10.早停:当模型训练到一定效果后提前结束训练,防止过拟合。
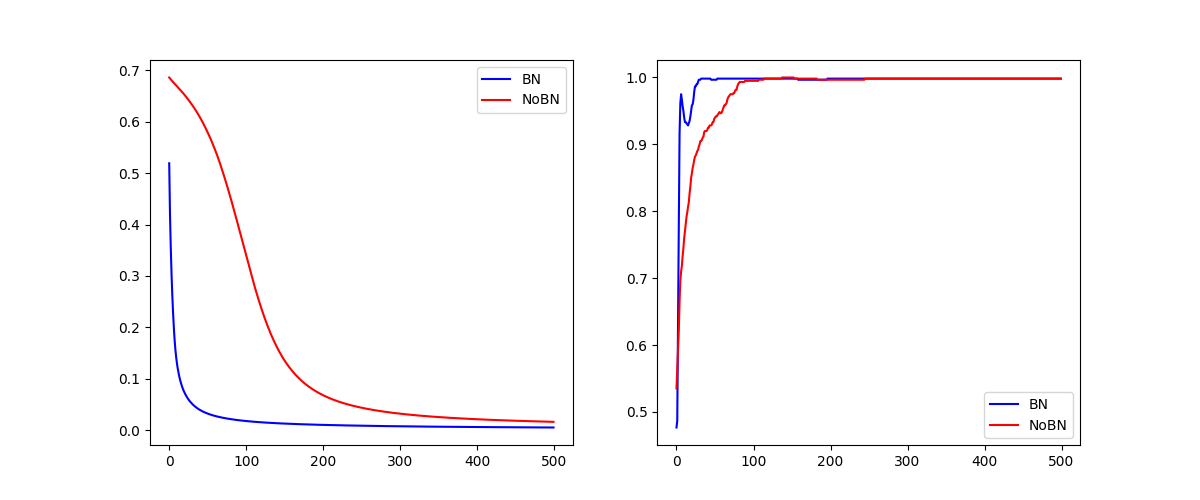
11.批量标准化:批量标准化(Batch Normalization, BN)是一种广泛使用的神经网络正则化技术,核心思想是对每一层的输入进行标 准化,然后进行缩放和平移,旨在加速训练、提高模型的稳定性和泛化能力。批量标准化通常在全连接层或卷积层之 后、激活函数之前应用。
效果区别:

















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









