




到目前为止,我们已经看到了基本抽象的发展。 操作系统执行。我们已经看到了如何使用单个物理CPU和转换。 它进入多个虚拟cpu,从而使多个程序同时运行的幻象得以实现。我们也看到了如何创建。 对每个进程的大型私有虚拟内存的错觉;这个地址空间的抽象使每个程序能够表现得好像它有它一样。 自己的内存时,实际上操作系统是秘密的多路复用地址空间。 跨物理内存(有时,磁盘)。
在本文中,我们为单个运行过程引入了一个新的抽象:一个线程.而不是我们在程序中单个执行点的经典视图(也就是。,一个单台PC,指令被从那里获取并执行,一个多线程程序有多个执行点(即:,多台pc,每一台都是被取出和执行的。也许另一种思考方式是,每个线程都非常像一个单独的进程,除了一个不同:它们共享相同的地址空间,从而可以访问相同的数据.因此,单个线程的状态与进程的状态非常相似。它有一个程序计数器(PC),它跟踪程序从哪里获取指令。每个线程都有自己的专用寄存器组,用于计算;因此,如果在单个处理器上运行两个线程,当从运行一个(T1)切换到运行另一个(T2)时,必须进行上下文切换.线程之间的上下文切换非常类似于进程之间的上下文切换,因为必须保存T1的寄存器状态,在运行T2之前恢复T2的寄存器状态.通过进程,我们将状态保存到进程控制块(PCB);现在,我们需要一个或多个线程控制块(TCBs)来存储进程的每个线程的状态.不过,在我们在线程之间执行的上下文切换中,有一个主要的区别,与进程相比:地址空间保持不变(即:,不需要切换我们正在使用的页面表。线程和进程之间的另一个主要区别涉及堆栈。在一个经典进程的地址空间的简单模型中(我们现在可以调用单线程进程),只有一个堆栈,通常位于地址空间的底部(图26.1,左侧)。
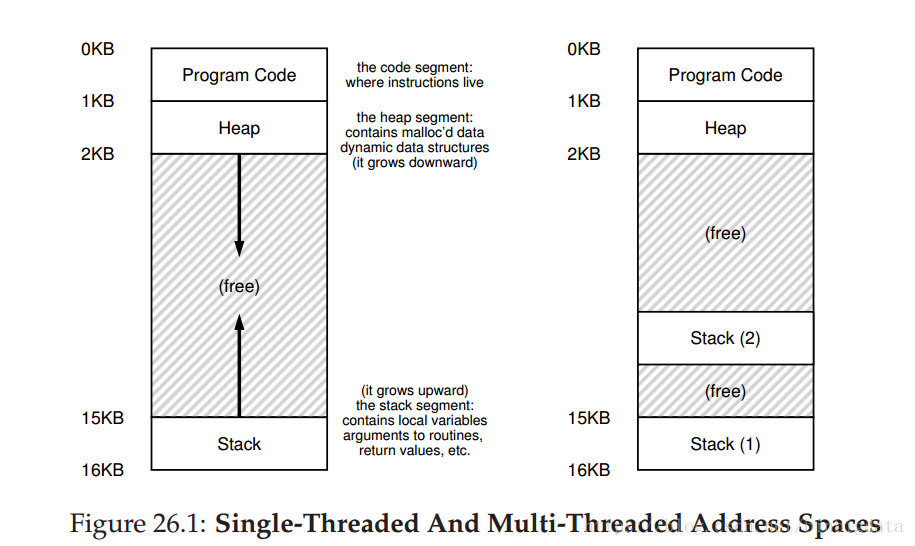
然而,在多线程进程中,每个线程都是独立运行的,当然也可以调用各种例程来执行它正在做的任何工作。与地址空间中的单个堆栈不同,每个线程都有一个堆栈。假设我们有一个多线程进程,其中有两个线程;生成的地址空间看起来不同(图26.1,右).在这个图中,您可以看到两个堆栈在整个过程的地址空间中传播。因此,任何堆栈分配的变量、参数、返回值和我们放在堆栈上的其他东西都将被放置在有时称为线程本地存储的地方,即。,相关线程的堆栈。您可能还会注意到这是如何破坏我们美丽的地址空间布局的。在此之前,栈和堆可以独立增长,只有当您在地址空间中耗尽空间时,问题才会出现。在这里,我们不再有这样美好的处境。幸运的是,这通常是可以的,因为栈通常不需要很大(在大量使用递归的程序中除外)。
26.1为什么要使用线程?
在深入讨论线程的细节和编写多线程程序可能遇到的一些问题之前,让我们先回答一个更简单的问题。为什么要使用线程呢?事实证明,使用线程至少有两个主要原因。第一个很简单:并行。假设您正在编写一个程序,该程序在非常大的数组上执行操作,例如,将两个大数组加在一起,或者按一定数量递增数组中的每个元素的值。如果只在一个处理器上运行,任务很简单:只需执行每个操作并完成。但是,如果您在一个具有多个的系统上执行这个程序。通过使用处理器执行部分工作,您就有可能大大加快这个过程。将标准单线程程序转换为在多个CPU上执行这种工作的程序的任务称为并行化,并且使用每个CPU的线程来完成这项工作是一种自然的、典型的方法,可以使程序在现代硬件上运行得更快.
第二个原因更微妙一些:为了避免由于I/O速度慢而阻塞程序的进度。假设您正在编写一个程序,该程序执行不同类型的I/O:要么等待发送或接收消息,要么等待一个显式磁盘I/O完成,甚至(隐式地)完成页面错误。与其等待,您的程序可能希望做其他事情,包括利用CPU执行计算,或者甚至发出进一步的I/O请求。使用线程是避免被卡住的一种自然方法;当你的程序中有一个线程在等待(也就是)。,阻塞等待I/O), CPU调度程序可以切换到其他线程,这些线程准备运行并执行一些有用的操作。:线程化使I/O与单个程序中的其他活动重叠,就像跨程序的多编程一样;因此,许多现代基于服务器的应用程序(web服务器、数据库管理系统等)在其实现中使用了线程。当然,在上面提到的任何一个案例中,您都可以使用多个进程而不是线程。但是,线程共享一个地址空间,因此可以很容易地共享数据,因此在构建这些类型的程序时,这是一个自然的选择。对于逻辑分离的任务来说,进程是一个更合理的选择,因为在内存中很少需要共享数据结构。
26.2示例:线程创建。
让我们来了解一些细节。假设我们想运行一个程序,它创建两个线程,每个线程都做一些独立的工作,在这种情况下打印a或B。代码如图26.2(第4页)所示。主程序创建两个线程,每个线程将运行mythread()的函数,不过有不同的参数(字符串A或B)。旦创建了一个线程,它可能会立即开始运行(取决于调度程序的变化);或者,它可能被放入一个准备好的但不运行的状态,因此还没有运行。当然,在一个多处理器上,线程甚至可以同时运行,但是我们还不必担心这种可能性。在创建了两个线程之后(我们称它们为T1和T2),主线程调用pthread join(),它等待一个特定的线程完成。它这样做两次,从而确保T1和T2在最终允许主线程再次运行之前运行和完成;当它完成时,它将打印main: end和exit。总的来说,在运行期间使用了三个线程:主线程、T1和T2。

让我们检查一下这个小程序的可能执行顺序。 在执行图中(图26.3,第5页),时间在向下的方向增加,每一列显示的是不同的线程。 主线一,或线程1,或线程2)正在运行。
但是请注意,这种排序并不是唯一可能的排序。在 事实上,给定一个指令序列,有相当一部分,取决于。 调度程序决定在给定的点运行哪个线程。例如, 一旦线程被创建,它可能会立即运行,从而导致。 如图26.4所示(第5页)。我们还可以在“A”之前看到“B”,如果,比方说,调度器。 决定先运行线程2,尽管线程1是在前面创建的; 没有理由假定首先创建的线程将首先运行。 图26.5(第5页)显示了最后的执行顺序,使用了线程2。 在线程1之前开始炫耀它的东西。正如你可能看到的,一种思考线程创建的方法是它有点像做一个函数调用;但是,系统不是先执行函数,然后返回给调用者,而是为正在调用的例程创建一个新的执行线程,并且它独立于调用方运行,可能在返回创建之前,但可能是很久以后。接下来运行的是由OS调度器决定的,尽管调度器可能实现了一些合理的算法,但是很难知道在任何给定的时刻会运行什么。正如您可能从这个示例中可以看出的,线程使生命变得复杂:它已经很难判断什么时候运行!没有并发性,计算机是很难理解的。不幸的是,由于并发性,它只会变得更糟。更糟。




26.3为什么会变得更糟:共享数据
上面我们展示的简单的线程示例在显示线程是如何创建的以及如何根据调度程序决定运行它们的不同顺序来运行它们是非常有用的。但是,它不能告诉您的是,当线程访问共享数据时,线程是如何交互的
!让我们想象一个简单的例子,其中两个线程希望更新一个全局共享变量。我们将学习的代码是图26.6(第6页)。这里有一些关于代码的注释。首先,正如史蒂文斯建议的那样, 我们用线程创建和连接例程来简单地退出失败; 对于一个简单的程序,我们至少要注意一个错误。 发生了(如果有的话),但没有做任何非常聪明的事情(例如,just)。 退出).因此,Pthread创建()简单地调用Pthread创建(),第二,我们只使用单个代码,而不是使用两个独立的函数体,而是通过一个参数(在本例中是一个字符串),这样我们就可以让每个线程在其消息之前打印不同的字母。最后,也是最重要的一点,我们现在可以看到每个worker正在尝试做的事情:向共享变量计数器添加一个数字,并在循环中执行1000万次(1e7)。因此,期望的最终结果是:2000万.现在我们编译并运行这个程序,看看它的行为。有时候,一切都是我们期待的。

不幸的是,当我们运行这个代码时,即使是在一个处理器上,我们也是如此。 不一定要得到想要的结果。有时,我们得到:

让我们再试一次,看看我们是不是疯了。毕竟,计算机不是应该像你所教的那样,产生决定性的结果吗?也许你的教授一直在骗你?(喘气)

不仅每一次运行都是错误的,而且会产生不同的结果!一个大问题仍然存在:为什么会发生这种情况?
 --反汇编语言工具
--反汇编语言工具
26.4问题的核心:不受控制的日程安排。
要理解发生这种情况的原因,我们必须理解编译器为更新计数器生成的代码序列。在这种情况下,我们希望简单地添加一个数字(1)来计数。此,这样做的代码序列可能看起来像这样(在x86中)。

本例假设变量计数器位于地址0x8049a1c。在这个三指令序列中,首先使用x86 mov指令来获取地址的内存值并将其放入寄存器eax中。然后,执行添加,将1 (0x1)添加到eax寄存器的内容中,最后,eax的内容存储在同一个地址的内存中。
让我们假设我们的两个线程之一(线程1)进入这个代码区域,因此将会增加一个计数器。它将计数器的值加载到它的寄存器eax中(让s说它从50开始)。让我们假设我们的两个线程之一(线程1)进入这个代码区域,因此将会增加一个计数器。它将计数器的值加载到它的寄存器eax中(让s说它从50开始)。因此,eax=50的线程1。然后在寄存器中添加一个;因此eax = 51。现在,不幸的事情发生了:一个定时器中断了;这样,操作系统就可以将当前运行的线程(其PC、寄存器包括eax等)保存到线程的TCB中。现在更糟糕的事情发生了:线程2被选择运行,它也进入了相同的代码段。它还执行第一个指令,获取计数器的值并将其放入其eax(请记住:运行时每个线程都有自己的私有寄存器;寄存器是由保存和恢复它们的上下文切换代码虚拟化的。
此时计数器仍然是50,因此线程2有eax=50。让我们假设线程2执行下面两个指令,将eax增加1(因此eax=51),然后将eax的内容保存到计数器中(地址0x8049a1c)。因此,全局变量计数器现在的值是51。最后,另一个上下文切换发生,线程1继续运行。回想一下,它刚刚执行了mov和add,现在即将执行最后的mov指令。还记得,eax = 51。因此,最后的mov指令执行,并将值保存到内存中;计数器又设置为51。简单地说,所发生的是这样的:递增计数器的代码已经运行了两次,但是计数器,从50开始,现在只等于51。这个程序的正确版本应该导致变量计数器等于52。

让我们看一看详细的执行跟踪,以便更好地理解这个问题。假设,在本例中,上面的代码是在内存中的地址100中加载的,就像下面的序列一样(请注意,您曾经使用过nice的类似于riscl的指令集:x86具有可变长度的指令;这个mov指令占用5个字节的内存,并且add只占3个字节。

有了这些假设,如图26.7所示。假设计数器从值50开始,并通过这个示例进行跟踪,以确保您理解发生了什么。我们在这里演示的内容称为竞态条件:结果取决于代码的计时执行。有一些坏运气。如果在执行过程中出现不及时的情况,我们就会得到错误的结果。事实上,我们每次都可能得到不同的结果;因此,我们将这个结果称为不确定的结果,而不是一个很好的确定性计算(我们习惯于从计算机中使用),它不知道输出将会是什么,并且它确实很可能在运行时是不同的。由于执行此代码的多个线程可能导致竞态条件,所以我们将此代码称为临界区。关键部分是访问共享变量(或更广泛地说,共享资源)的代码段,不能同时执行多个线程。
我们真正想要的是所谓的互斥。该属性保证如果一个线程在关键部分执行,其他线程将被阻止这样做。
实际上,所有这些术语都是由Edsger Dijkstra创造的,他是这个领域的先驱,因为这个和其他的工作而获得了图灵奖。参见他1968年关于合作顺序过程的论文[D68],对这个问题的描述非常清晰。我们将在本书的这一部分中听到关于Dijkstra的更多信息。
26.5原子性的愿望
解决这个问题的一种方法是使用更强大的指令,在一个步骤中,我们完成了我们需要做的事情,从而消除了不及时中断的可能性。例如,如果我们有一个这样的超级指令。
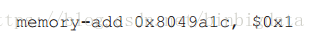
假设此指令将值添加到内存位置,并且硬件保证它以原子方式执行;执行指令时,它将按需要执行更新。不能中断中间指令,因为这正是我们从硬件接收到的保证:当中断发生时,指令要么没有运行,要么已经运行完成;没有中间状态。硬件可以是很漂亮的东西,不是。
在这种情况下,原子性意味着作为一个单位,有时我们把它看作全部或全部。我们想要的是原子地执行这三个指令序列。
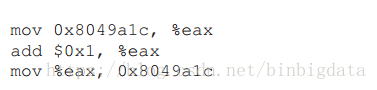
正如我们所说,如果我们有一个单一的指令来做这件事,我们就可以发出指令并完成。但一般情况下,我们不会有这样的指令。假设我们正在构建一个并发的b -树,并希望更新它;我们真的希望硬件支持B-tree指令的原子更新吗?可能不会,至少在一个正常的指令集里。因此,我们要做的是向硬件请求一些有用的指令,以便我们可以构建一个我们称为同步原语的通用集合。通过使用这些硬件同步原语,结合操作系统的一些帮助。我们将能够构建多线程代码访问关键部分同步和控制方式。因此,尽管并发执行具有挑战性,但仍然能够可靠地生成正确的结果。非常棒,不是吗。
这是我们将在本书的这一节研究的问题。这是一个奇妙而又困难的问题,应该让你的心灵受到伤害。如果它没有,那你就不明白!继续工作,直到你的头受伤;然后你就会知道你正朝着正确的方向前进。在这一点上,休息一下;我们不希望你的头太疼。
另一个问题:等待另一个
本章设置了并发的问题,就好像线程之间只发生了一种交互,即访问共享变量和支持关键部分的原子性。事实证明,出现了另一种常见的交互,其中一个线程必须等待另一个线程在它继续之前完成一些操作。例如,当一个进程执行磁盘I/O并被放入睡眠时,这种交互就产生了。当I/O完成时,进程需要从休眠状态中唤醒,这样它才能继续。:因此,在接下来的章节中,我们将不仅学习如何构建支持同步原语来支持原子性,还将研究支持这种类型的睡眠/唤醒交互的机制,这种交互在多线程程序中很常见。如果这现在没有意义,那没关系!当你读到条件变量这一章的时候,它就足够了。如果它没有,那么它就没那么好了,你应该再读一遍那一章,直到它有意义为止。
26.7概要:为什么在OS类中。

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









