




摘要:本文整理自 Flink Forward 2020 全球在线会议中文精华版,由 Apache Flink PMC 伍翀(云邪)分享,社区志愿者陈婧敏(清樾)整理。旨在帮助大家更好地理解 Flink SQL 引擎的工作原理。文章主要分为以下四部分:
- Flink SQL Architecture
- How Flink SQL Works?
- Flink SQL Optimizations
- Summary and Futures
Tips:点击下方链接可查看作者分享的原版视频~
https://ververica.cn/developers/flink-forward-virtual-conference/
Apache Flink 社区在最近的两个版本(1.9 & 1.10 )中为面向未来的统一流批处理在架构层面做了很多优化,其中一个重大改造是引入了 Blink Planner,开始支持 SQL & Table API 使用不同的 SQL Planner 进行编译(Planner 的插件化)。
本文首先会介绍推动这些优化背后的思考,展示统一的架构如何更好地处理流式和批式查询,其次将深入剖析 Flink SQL 的编译及优化过程,包括:
- Flink SQL 利用 Apache Calcite 将 SQL 翻译为关系代数表达式,使用表达式折叠(Expression Reduce),下推优化(Predicate / Projection Pushdown )等优化技术生成物理执行计划(Physical Plan),利用 Codegen 技术生成高效执行代码。
- Flink SQL 使用高效的二进制数据存储结构 BinaryRow 加速计算性能;使用 Mini-batch 攒批提高吞吐,降低两层聚合时由 Retraction 引起的数据抖动;聚合场景下数据倾斜处理和 Top-N 排序的优化原理。
## Flink SQL 架构 & Blink Planner(1.9+ )
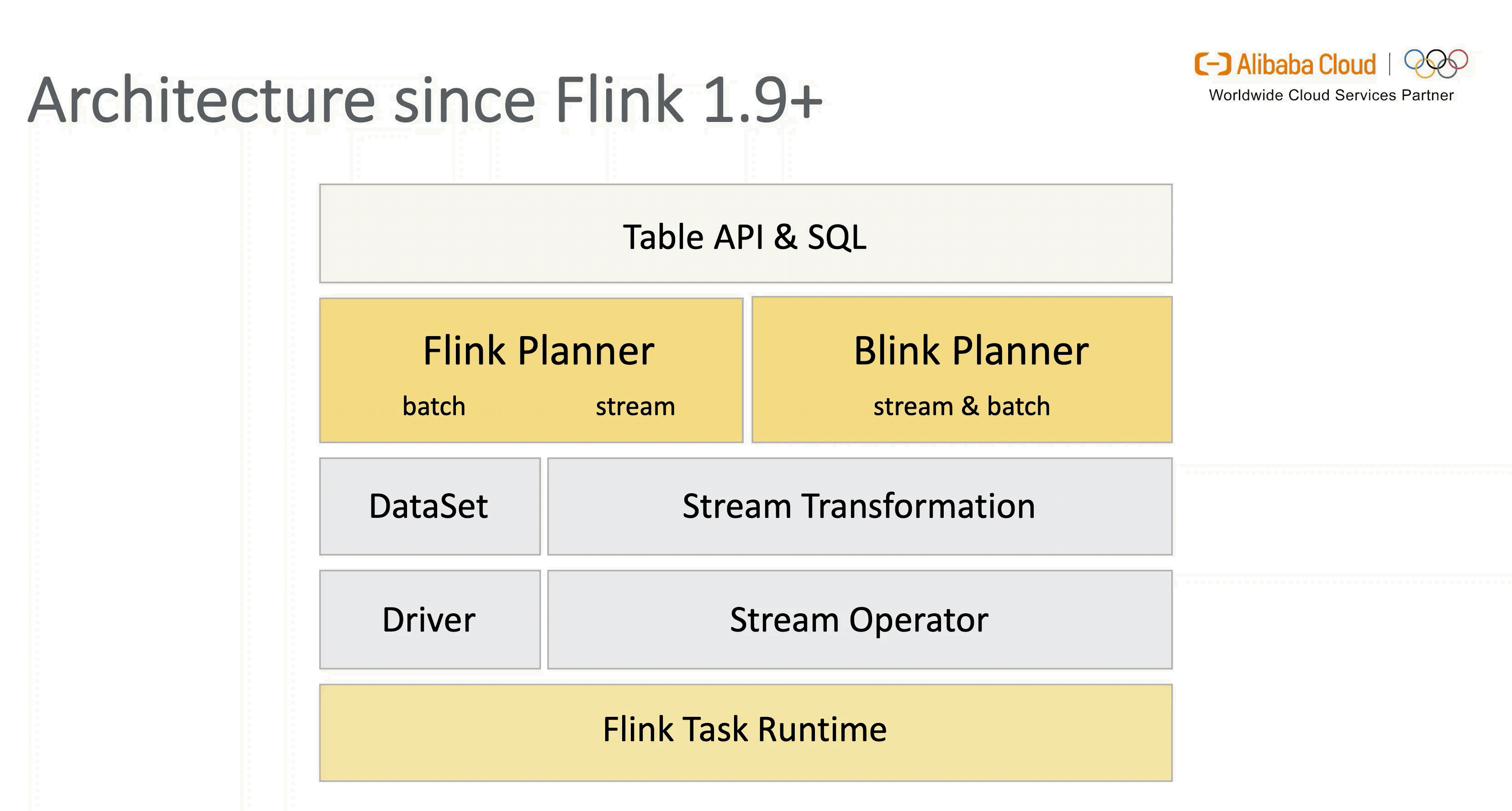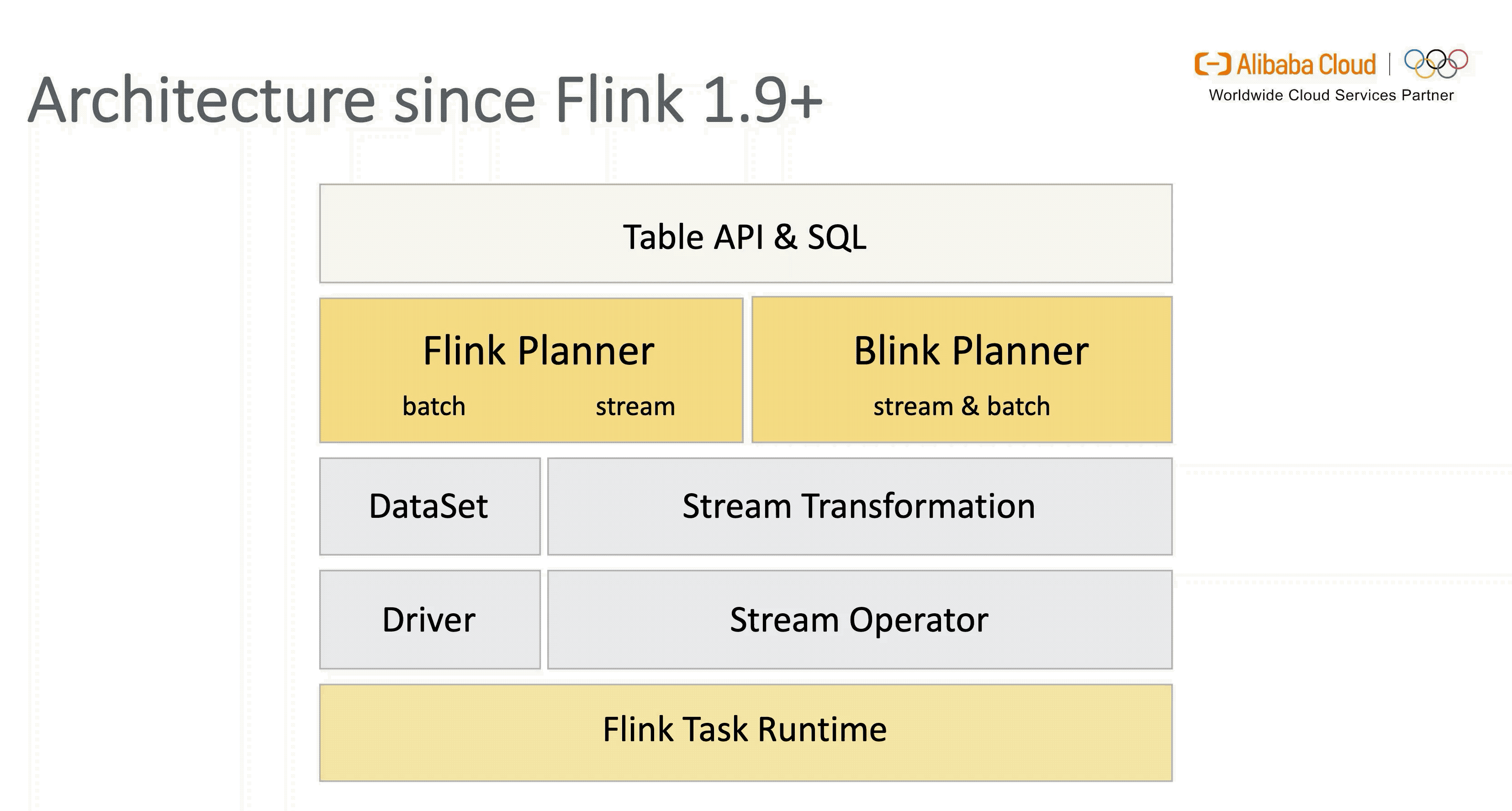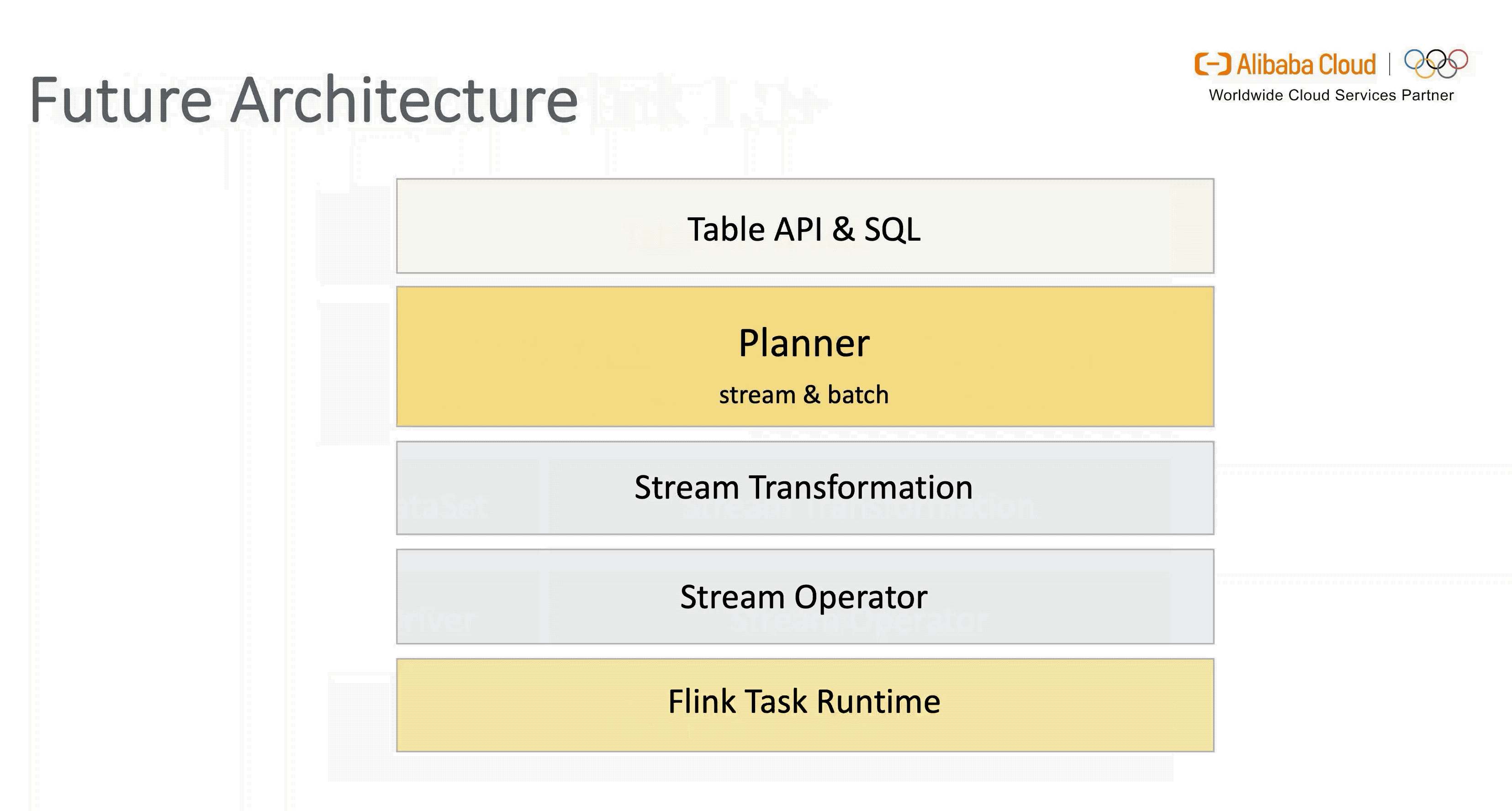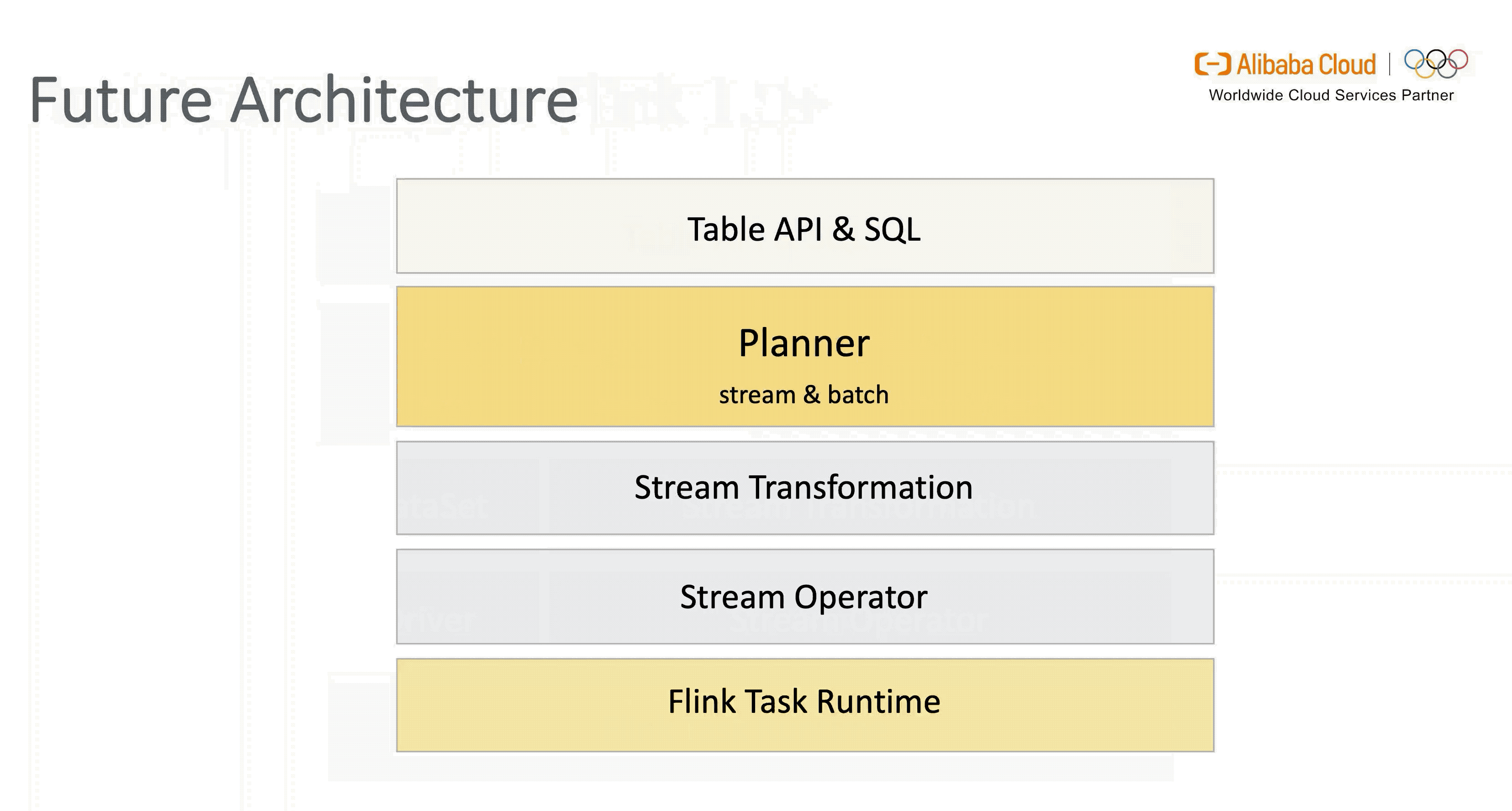
1.1 Old Planner 的限制
要想了解 Flink SQL 在1.9 版本引入新架构的动机,我们首先看下 1.9 版本之前的架构设计。
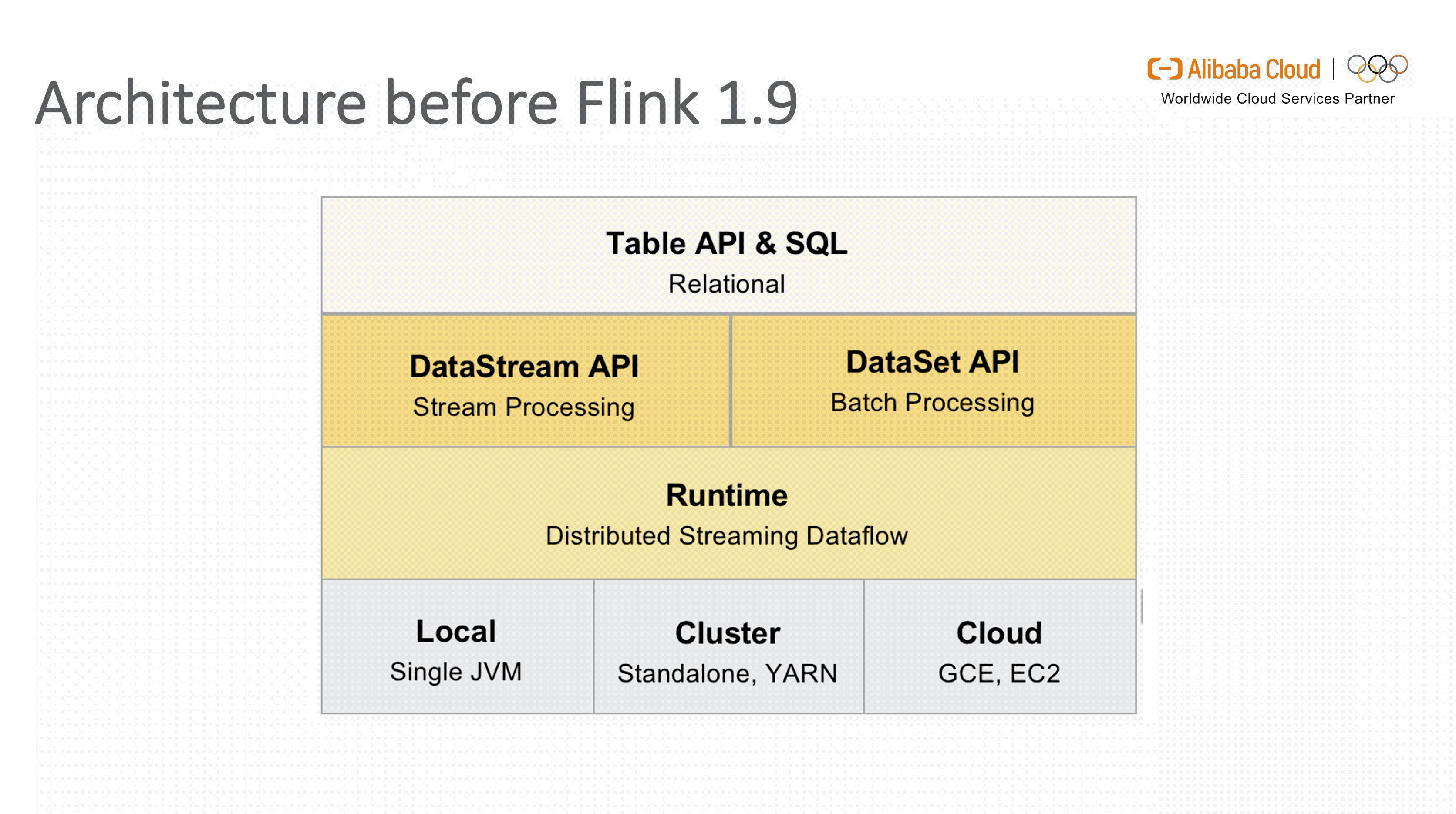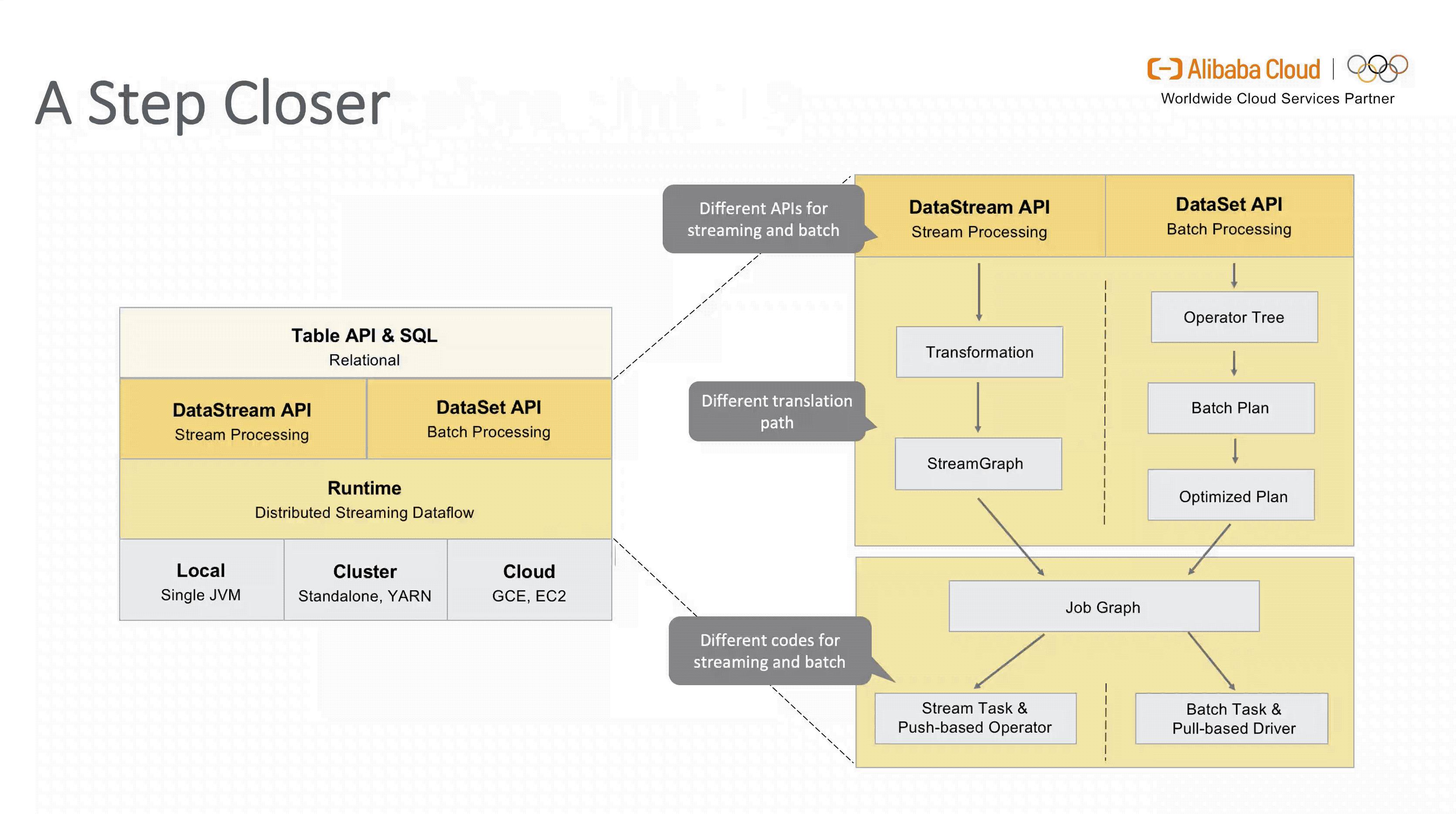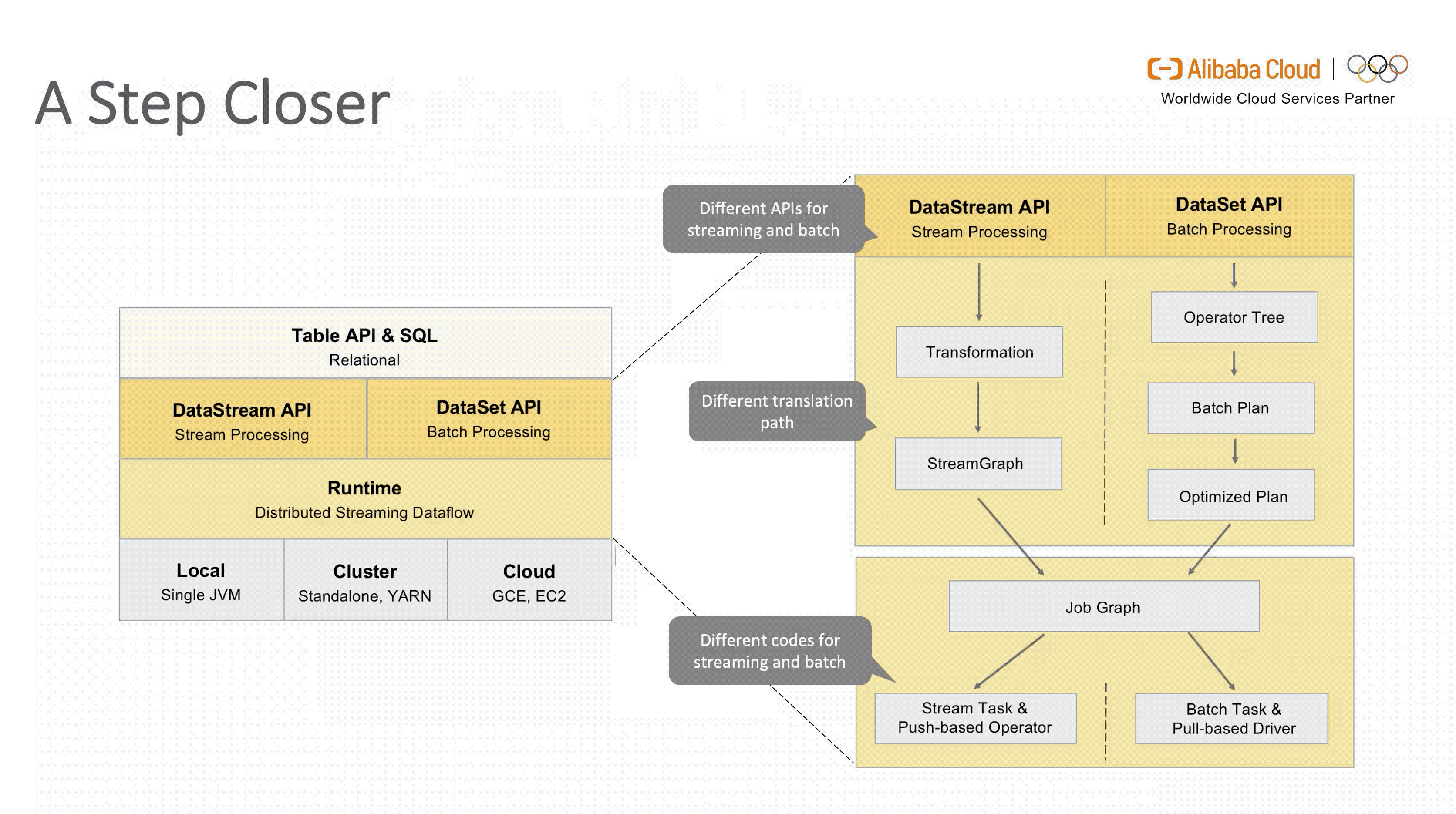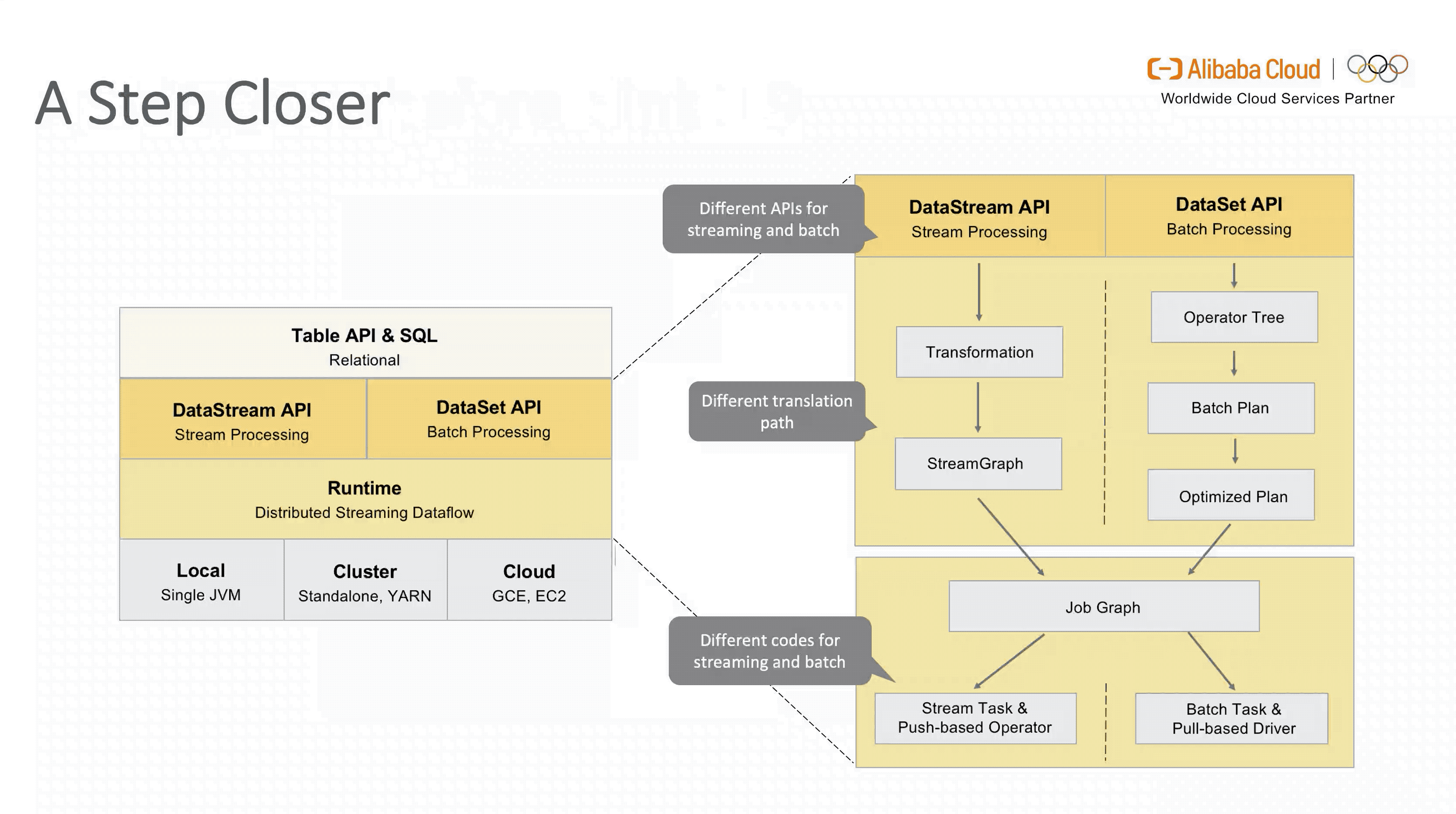
从图中可以看出,虽然面向用户的 Table API & SQL 是统一的,但是流式和批式任务在翻译层分别对应了 DataStreamAPI 和 DataSetAPI,在 Runtime 层面也要根据不同的 API 获取执行计划,两层的设计使得整个架构能够复用的模块有限,不易扩展。
1.2 统一的 Blink Planner
Flink 在设计之初就遵循“批是流的特例”的理念,在架构上做到流批统一是大势所趋。在社区和阿里巴巴的共同努力下,1.9 版本引入了新的 Blink Planner,将批 SQL 处理作为流 SQL 处理的特例,尽量对通用的处理和优化逻辑进行抽象和复用,通过 Flink 内部的 Stream Transformation API 实现流 & 批的统一处理,替代原 Flink Planner 将流 & 批区分处理的方式。
此外,新架构通过灵活的插件化方式兼容老版本 Planner,用户可自行选择。不过在 1.11 版本 Blink Planner 会代替 Old Planner 成为默认的 Planner 来支持流 & 批进一步融合统一( Old Planner 将在之后逐步退出历史舞台)。
Flink SQL 工作流
Flink SQL 引擎的工作流总结如图所示。
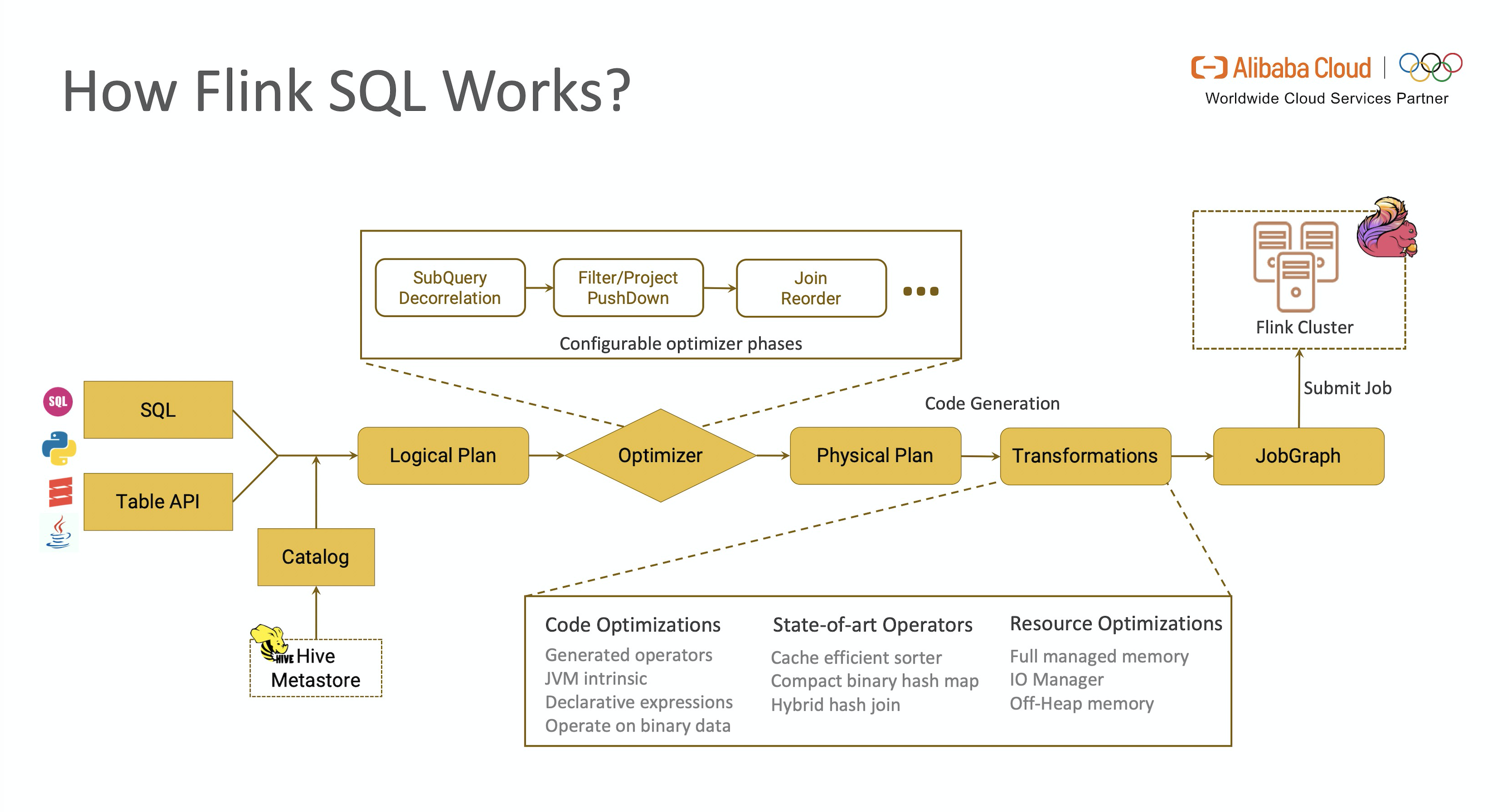
从图中可以看出,一段查询 SQL / 使用TableAPI 编写的程序(以下简称 TableAPI 代码)从输入到编译为可执行的 JobGraph 主要经历如下几个阶段
- 将 SQL文本 / TableAPI 代码转化为逻辑执行计划(Logical Plan)
- Logical Plan 通过优化器优化为物理执行计划(Physical Plan)
- 通过代码生成技术生成 Transformations 后进一步编译为可执行的 JobGraph 提交运行
本节将重点对 Flink SQL 优化器的常用优化方法和 CodeGen 生成 Transformations 进行介绍。
2.1 Logical Planning
Flink SQL 引擎使用 Apache Calcite SQL Parser 将 SQL 文本解析为词法树,SQL Validator 获取 Catalog 中元数据的信息进行语法分析和验证,转化为关系代数表达式(RelNode),再由 Optimizer 将关系代数表达式转换为初始状态的逻辑执行计划。
备注:TableAPI 代码使用 TableAPI Validator 对接 Catalog 后生成逻辑执行计划。
E.g.1 考虑如下表达 JOIN
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2265
2265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









