




图1: DeepSpeed ZeRO++ 简介
大型 AI 模型正在改变数字世界。基于大型语言模型 (LLM)的 Turing-NLG、ChatGPT 和 GPT-4 等生成语言模型用途广泛,能够执行摘要、代码生成和翻译等任务。 同样,DALL·E、Microsoft Designer 和 Bing Image Creator 等大型多模态生成模型可以生成艺术、建筑、视频和其他数字资产,使内容创作者、建筑师和工程师能够探索全新的创意生产力。
然而,训练这些大型模型需要在数百甚至数千个 GPU 设备上使用大量内存和计算资源。 例如,训练 Megatron-Turing NLG 530B模型需要使用超过 4,000 个 NVidia A100 GPU。 有效地利用这些资源需要一个复杂的优化系统,以将模型合理分配到各个设备的内存中,并有效地并行化这些设备上的计算。 同时,为了使深度学习社区能够轻松进行大型模型训练,这些优化必须易于使用。
DeepSpeed 的 ZeRO 优化系列为这些挑战提供了强大的解决方案,并已广泛用于大型深度学习模型例如TNLG-17B、Bloom-176B、MPT-7B、Jurrasic-1的训练中 。尽管它具有变革性的能力 ,在一些关键场景中,ZeRO 会在 GPU 之间产生大量数据传输开销,这降低了训练效率。 这种情况特别发生在以下场景中:a) 全局batch size较小,而 GPU数量多,这导致每个 GPU 上batch size较小,需要频繁通信;或者 b) 在低端集群上进行训练,其中跨节点网络带宽有限,导致高通信延迟。在这些情况下,ZeRO 的训练效率会受到限制。
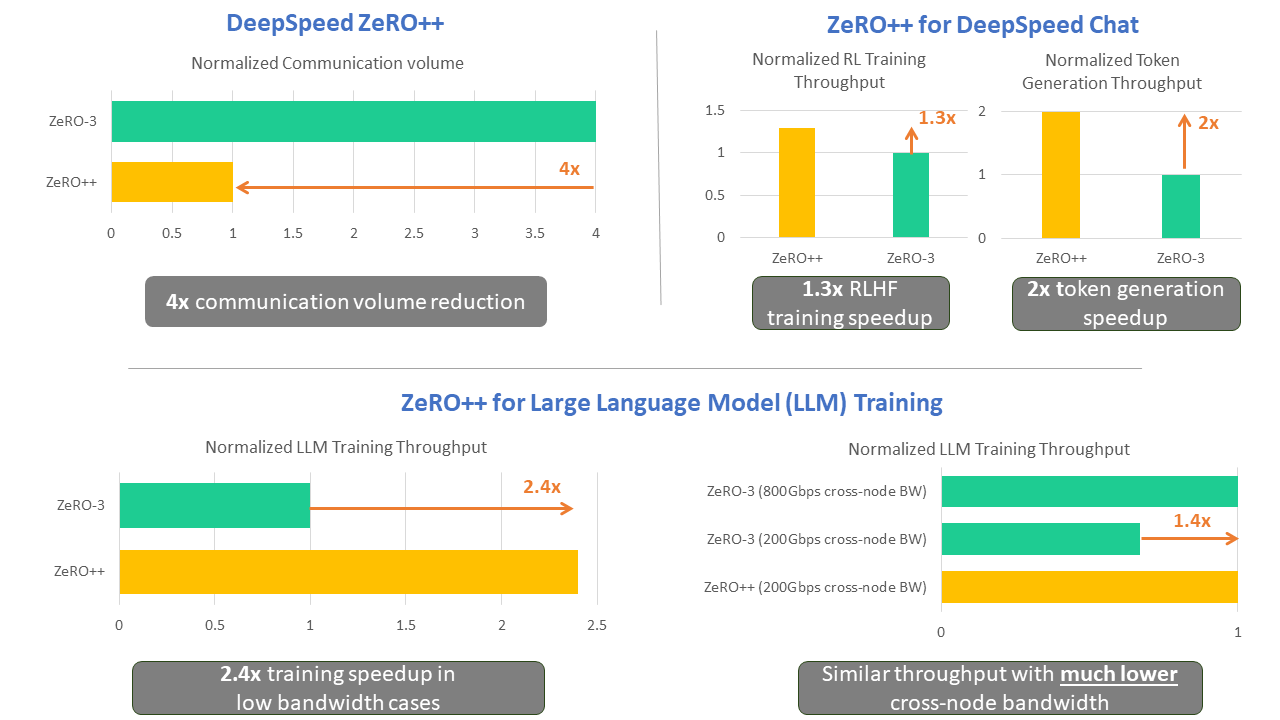
为了解决这些限制,我们发布了 ZeRO++ 。 ZeRO++相比 ZeRO将总通信量减少了 4 倍,而不会影响模型质量。 这有两个关键意义:
-
ZeRO++加速大型模型预训练和微调
- 每个GPU上 batch size较小时: 无论是在数千个 GPU 上预训练大型模型,还是在数百个甚至数十个 GPU 上对其进行微调,当每个 GPU 的batch size较小时,ZeRO++ 提供比 ZeRO 高 2.2 倍的吞吐量,直接减少训练时间和成本。
- 低带宽计算集群: ZeRO++ 使低带宽集群能够实现与带宽高 4 倍的高端集群类似的吞吐量。 因此,ZeRO++ 可以跨更广泛的集群进行高效的大型模型训练。
-
ZeRO++加速 ChatGPT 类的 RLHF训练
-
虽然 ZeRO++ 主要是为训练而设计的,但它的优化也自动适用于
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









