




 本文深入解析DomainSeparationNetworks(DSN),一种用于DomainAdaptation的深度学习方法。介绍其理论基础、模型结构、Loss函数定义及训练流程。通过对源码的详细剖析,揭示了如何利用DSN实现跨域数据的高效处理。
本文深入解析DomainSeparationNetworks(DSN),一种用于DomainAdaptation的深度学习方法。介绍其理论基础、模型结构、Loss函数定义及训练流程。通过对源码的详细剖析,揭示了如何利用DSN实现跨域数据的高效处理。
Domain Separation Networks
介绍
这篇论文介绍了一个Domain Adaptation方法,文章地址,文章源码地址,接下来将结合文章中的方法对源码进行剖析。
理论方法
源码基于TensorFlow进行构建,测试使用的数据集为Source domain:MNIST,Target domain:MNIST-m。
采用的深度学习方法
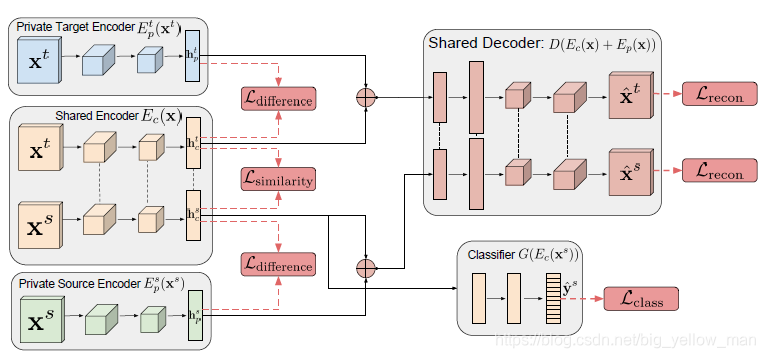
Loss 函数定义
训练阶段的目标为最小化函数
L
L
L
L
=
L
t
a
s
k
+
α
L
r
e
c
o
n
+
β
L
d
i
f
f
e
r
e
n
c
e
+
γ
L
s
i
m
i
l
a
r
i
t
y
L = L_{task} +\alpha L_{recon} + \beta L_{difference} +\gamma L_{similarity}
L=Ltask+αLrecon+βLdifference+γLsimilarity
训练与评估流程
- 训练几个encoder,最小化loss函数,保存checkpoint
- 评估时从checkpoint中读取source domian 的 shared encoder参数进行评估
源码剖析
模型创建
在dsn.py中,对实验所需的模型和autoencoder进行创建。
def create_model(source_images, source_labels, domain_selection_mask,
target_images, target_labels, similarity_loss, params,
basic_tower_name):
"""Creates a DSN model.
Args:
source_images: images from the source domain, a tensor of size
[batch_size, height, width, channels]
source_labels: a dictionary with the name, tensor pairs. 'classes' is one-
hot for the number of classes.
domain_selection_mask: a boolean tensor of size [batch_size, ] which denotes
the labeled images that belong to the source domain.
target_images: images from the target domain, a tensor of size
[batch_size, height width, channels].
target_labels: a dictionary with the name, tensor pairs.
similarity_loss: The type of method to use for encouraging
the codes from the shared encoder to be similar.
params: A dictionary of parameters. Expecting 'weight_decay',
'layers_to_regularize', 'use_separation', 'domain_separation_startpoint',
'alpha_weight', 'beta_weight', 'gamma_weight', 'recon_loss_name',
'decoder_name', 'encoder_name'
basic_tower_name: the name of the tower to use for the shared encoder.
Raises:
ValueError: if the arch is not one of the available architectures.
"""
network = getattr(models, basic_tower_name)
num_classes = source_labels['classes'].get_shape().as_list()[1]
# Make sure we are using the appropriate number of classes.
network = partial(network, num_classes=num_classes)
# Add the classification/pose estimation loss to the source domain.
source_endpoints = add_task_loss(source_images, source_labels, network,
params)
if similarity_loss == 'none':
# No domain adaptation, we can stop here.
return
with tf.variable_scope('towers', reuse=True):
target_logits, target_endpoints = network(
target_images, weight_decay=params['weight_decay'], prefix='target')
# Plot target accuracy of the train set.
target_accuracy = utils.accuracy(
tf.argmax(target_logits, 1), tf.argmax(target_labels['classes'], 1))
if 'quaternions' in target_labels:
target_quaternion_loss = losses.log_quaternion_loss(
target_labels['quaternions'], target_endpoints['quaternion_pred'],
params)
tf.summary.scalar('eval/Target quaternions', target_quaternion_loss)
tf.summary.scalar('eval/Target accuracy', target_accuracy)
source_shared = source_endpoints[params['layers_to_regularize']]
target_shared = target_endpoints[params['layers_to_regularize']]
# When using the semisupervised model we include labeled target data in the
# source classifier. We do not want to include these target domain when
# we use the similarity loss.
indices = tf.range(0, source_shared.get_shape().as_list()[0])
indices = tf.boolean_mask(indices, domain_selection_mask)
add_similarity_loss(similarity_loss,
tf.gather(source_shared, indices),
tf.gather(target_shared, indices), params)
if params['use_separation']:
add_autoencoders(
source_images,
source_shared,
target_images,
target_shared,
params=params,)
mu = dsn_loss_coefficient(params)
# The layer to concatenate the networks at.
concat_layer = params['layers_to_regularize']
# The coefficient for modulating the private/shared difference loss.
difference_loss_weight = params['beta_weight'] * mu
# The reconstruction weight.
recon_loss_weight = params['alpha_weight'] * mu
# The reconstruction loss to use.
recon_loss_name = params['recon_loss_name']
# The decoder/encoder to use.
decoder_name = params['decoder_name']
encoder_name = params['encoder_name']
_, height, width, _ = source_data.get_shape().as_list()
code_size = source_shared.get_shape().as_list()[-1]
weight_decay = params['weight_decay']
encoder_fn = getattr(models, encoder_name)
# Target Auto-encoding.
with tf.variable_scope('source_encoder'):
source_endpoints = encoder_fn(
source_data, code_size, weight_decay=weight_decay)
with tf.variable_scope('target_encoder'):
target_endpoints = encoder_fn(
target_data, code_size, weight_decay=weight_decay)
decoder_fn = getattr(models, decoder_name)
decoder = partial(
decoder_fn,
height=height,
width=width,
channels=source_data.get_shape().as_list()[-1],
weight_decay=weight_decay)
# Source Auto-encoding.
source_private = source_endpoints[concat_layer]
target_private = target_endpoints[concat_layer]
with tf.variable_scope('decoder'):
source_recons = decoder(concat_operation(source_shared, source_private))
with tf.variable_scope('decoder', reuse=True):
source_private_recons = decoder(
concat_operation(tf.zeros_like(source_private), source_private))
source_shared_recons = decoder(
concat_operation(source_shared, tf.zeros_like(source_shared)))
with tf.variable_scope('decoder', reuse=True):
target_recons = decoder(concat_operation(target_shared, target_private))
target_shared_recons = decoder(
concat_operation(target_shared, tf.zeros_like(target_shared)))
target_private_recons = decoder(
concat_operation(tf.zeros_like(target_private), target_private))
losses.difference_loss(
source_private,
source_shared,
weight=difference_loss_weight,
name='Source')
losses.difference_loss(
target_private,
target_shared,
weight=difference_loss_weight,
name='Target')
add_reconstruction_loss(recon_loss_name, source_data, source_recons,
recon_loss_weight, 'source')
add_reconstruction_loss(recon_loss_name, target_data, target_recons,
recon_loss_weight, 'target')
# Add summaries
source_reconstructions = tf.concat(
axis=2,
values=map(normalize_images, [
source_data, source_recons, source_shared_recons,
source_private_recons
]))
target_reconstructions = tf.concat(
axis=2,
values=map(normalize_images, [
target_data, target_recons, target_shared_recons,
target_private_recons
]))
tf.summary.image(
'Source Images:Recons:RGB',
source_reconstructions[:, :, :, :3],
max_outputs=10)
tf.summary.image(
'Target Images:Recons:RGB',
target_reconstructions[:, :, :, :3],
max_outputs=10)
if source_reconstructions.get_shape().as_list()[3] == 4:
tf.summary.image(
'Source Images:Recons:Depth',
source_reconstructions[:, :, :, 3:4],
max_outputs=10)
tf.summary.image(
'Target Images:Recons:Depth',
target_reconstructions[:, :, :, 3:4],
max_outputs=10)
Loss函数组成
loss-task
使用softmax_cross_entropy构建的loss-task。
def add_task_loss(source_images, source_labels, basic_tower, params):
"""Adds a classification and/or pose estimation loss to the model.
Args:
source_images: images from the source domain, a tensor of size
[batch_size, height, width, channels]
source_labels: labels from the source domain, a tensor of size [batch_size].
or a tuple of (quaternions, class_labels)
basic_tower: a function that creates the single tower of the model.
params: A dictionary of parameters. Expecting 'weight_decay', 'pose_weight'.
Returns:
The source endpoints.
Raises:
RuntimeError: if basic tower does not support pose estimation.
"""
with tf.variable_scope('towers'):
source_logits, source_endpoints = basic_tower(
source_images, weight_decay=params['weight_decay'], prefix='Source')
if 'quaternions' in source_labels: # We have pose estimation as well
if 'quaternion_pred' not in source_endpoints:
raise RuntimeError('Please use a model for estimation e.g. pose_mini')
loss = losses.log_quaternion_loss(source_labels['quaternions'],
source_endpoints['quaternion_pred'],
params)
assert_op = tf.Assert(tf.is_finite(loss), [loss])
with tf.control_dependencies([assert_op]):
quaternion_loss = loss
tf.summary.histogram('log_quaternion_loss_hist', quaternion_loss)
slim.losses.add_loss(quaternion_loss * params['pose_weight'])
tf.summary.scalar('losses/quaternion_loss', quaternion_loss)
classification_loss = tf.losses.softmax_cross_entropy(
source_labels['classes'], source_logits)
tf.summary.scalar('losses/classification_loss', classification_loss)
return source_endpoints
loss-recon
采用mean_squared_error方法构建loss-recon
def add_reconstruction_loss(recon_loss_name, images, recons, weight, domain):
"""Adds a reconstruction loss.
Args:
recon_loss_name: The name of the reconstruction loss.
images: A `Tensor` of size [batch_size, height, width, 3].
recons: A `Tensor` whose size matches `images`.
weight: A scalar coefficient for the loss.
domain: The name of the domain being reconstructed.
Raises:
ValueError: If `recon_loss_name` is not recognized.
"""
if recon_loss_name == 'sum_of_pairwise_squares':
loss_fn = tf.contrib.losses.mean_pairwise_squared_error
elif recon_loss_name == 'sum_of_squares':
loss_fn = tf.contrib.losses.mean_squared_error
else:
raise ValueError('recon_loss_name value [%s] not recognized.' %
recon_loss_name)
loss = loss_fn(recons, images, weight)
assert_op = tf.Assert(tf.is_finite(loss), [loss])
with tf.control_dependencies([assert_op]):
tf.summary.scalar('losses/%s Recon Loss' % domain, loss)
loss-difference
使用矩阵的F范数计算,通过每个域的私有和共享表达之间的软子空间正交性约束来定义的该loss(We define the loss via a soft subspace orthogonality constraint between the private and shared representation of each domain.)
def difference_loss(private_samples, shared_samples, weight=1.0, name=''):
"""Adds the difference loss between the private and shared representations.
Args:
private_samples: a tensor of shape [num_samples, num_features].
shared_samples: a tensor of shape [num_samples, num_features].
weight: the weight of the incoherence loss.
name: the name of the tf summary.
"""
private_samples -= tf.reduce_mean(private_samples, 0)
shared_samples -= tf.reduce_mean(shared_samples, 0)
private_samples = tf.nn.l2_normalize(private_samples, 1)
shared_samples = tf.nn.l2_normalize(shared_samples, 1)
correlation_matrix = tf.matmul(
private_samples, shared_samples, transpose_a=True)
cost = tf.reduce_mean(tf.square(correlation_matrix)) * weight
cost = tf.where(cost > 0, cost, 0, name='value')
tf.summary.scalar('losses/Difference Loss {}'.format(name),
cost)
assert_op = tf.Assert(tf.is_finite(cost), [cost])
with tf.control_dependencies([assert_op]):
tf.losses.add_loss(cost)
loss-similarity
该loss项用于训练模型产生分类器无法可靠地预测编码表示的领域的表达(The domain adversarial similarity loss is used to train a model to produce representations such that a classifier cannot reliably predict the domain of the encoded representation.)
def add_similarity_loss(method_name,
source_samples,
target_samples,
params,
scope=None):
"""Adds a loss encouraging the shared encoding from each domain to be similar.
Args:
method_name: the name of the encoding similarity method to use. Valid
options include `dann_loss', `mmd_loss' or `correlation_loss'.
source_samples: a tensor of shape [num_samples, num_features].
target_samples: a tensor of shape [num_samples, num_features].
params: a dictionary of parameters. Expecting 'gamma_weight'.
scope: optional name scope for summary tags.
Raises:
ValueError: if `method_name` is not recognized.
"""
weight = dsn_loss_coefficient(params) * params['gamma_weight']
method = getattr(losses, method_name)
method(source_samples, target_samples, weight, scope)
文中采用的方法为loss-dann,主要对比了loss-mmd,loss-dann如下:
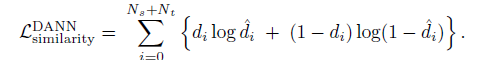
def dann_loss(source_samples, target_samples, weight, scope=None):
"""Adds the domain adversarial (DANN) loss.
Args:
source_samples: a tensor of shape [num_samples, num_features].
target_samples: a tensor of shape [num_samples, num_features].
weight: the weight of the loss.
scope: optional name scope for summary tags.
Returns:
a scalar tensor representing the correlation loss value.
"""
with tf.variable_scope('dann'):
batch_size = tf.shape(source_samples)[0]
samples = tf.concat(axis=0, values=[source_samples, target_samples])
samples = slim.flatten(samples)
domain_selection_mask = tf.concat(
axis=0, values=[tf.zeros((batch_size, 1)), tf.ones((batch_size, 1))])
# Perform the gradient reversal and be careful with the shape.
grl = grl_ops.gradient_reversal(samples)
grl = tf.reshape(grl, (-1, samples.get_shape().as_list()[1]))
grl = slim.fully_connected(grl, 100, scope='fc1')
logits = slim.fully_connected(grl, 1, activation_fn=None, scope='fc2')
domain_predictions = tf.sigmoid(logits)
domain_loss = tf.losses.log_loss(
domain_selection_mask, domain_predictions, weights=weight)
domain_accuracy = utils.accuracy(
tf.round(domain_predictions), domain_selection_mask)
assert_op = tf.Assert(tf.is_finite(domain_loss), [domain_loss])
with tf.control_dependencies([assert_op]):
tag_loss = 'losses/domain_loss'
tag_accuracy = 'losses/domain_accuracy'
if scope:
tag_loss = scope + tag_loss
tag_accuracy = scope + tag_accuracy
tf.summary.scalar(tag_loss, domain_loss)
tf.summary.scalar(tag_accuracy, domain_accuracy)
return domain_loss
在使用MMD loss的时候,只需要替换
L
s
i
m
i
l
a
r
i
t
y
L_{similarity}
Lsimilarity位置即可,loss-mmd如下,其中源码实验中使用的核函数是高斯核函数,但是论文中使用的是径向基RBF kernel(radial basis kernel),MMD loss是一个基于核函数计算两个sample的距离函数(The Maximum Mean Discrepancy (MMD) loss is a kernel-based distance function between pairs of samples.)
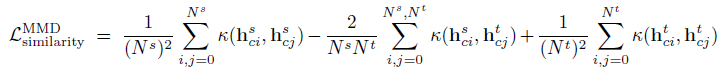
def mmd_loss(source_samples, target_samples, weight, scope=None):
"""Adds a similarity loss term, the MMD between two representations.
This Maximum Mean Discrepancy (MMD) loss is calculated with a number of
different Gaussian kernels.
Args:
source_samples: a tensor of shape [num_samples, num_features].
target_samples: a tensor of shape [num_samples, num_features].
weight: the weight of the MMD loss.
scope: optional name scope for summary tags.
Returns:
a scalar tensor representing the MMD loss value.
"""
sigmas = [
1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 5, 10, 15, 20, 25, 30, 35, 100,
1e3, 1e4, 1e5, 1e6
]
gaussian_kernel = partial(
utils.gaussian_kernel_matrix, sigmas=tf.constant(sigmas))
loss_value = maximum_mean_discrepancy(
source_samples, target_samples, kernel=gaussian_kernel)
loss_value = tf.maximum(1e-4, loss_value) * weight
assert_op = tf.Assert(tf.is_finite(loss_value), [loss_value])
with tf.control_dependencies([assert_op]):
tag = 'MMD Loss'
if scope:
tag = scope + tag
tf.summary.scalar(tag, loss_value)
tf.losses.add_loss(loss_value)
return loss_value
def maximum_mean_discrepancy(x, y, kernel=utils.gaussian_kernel_matrix):
r"""Computes the Maximum Mean Discrepancy (MMD) of two samples: x and y.
Maximum Mean Discrepancy (MMD) is a distance-measure between the samples of
the distributions of x and y. Here we use the kernel two sample estimate
using the empirical mean of the two distributions.
MMD^2(P, Q) = || \E{\phi(x)} - \E{\phi(y)} ||^2
= \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) },
where K = <\phi(x), \phi(y)>,
is the desired kernel function, in this case a radial basis kernel.
Args:
x: a tensor of shape [num_samples, num_features]
y: a tensor of shape [num_samples, num_features]
kernel: a function which computes the kernel in MMD. Defaults to the
GaussianKernelMatrix.
Returns:
a scalar denoting the squared maximum mean discrepancy loss.
"""
with tf.name_scope('MaximumMeanDiscrepancy'):
# \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) }
cost = tf.reduce_mean(kernel(x, x))
cost += tf.reduce_mean(kernel(y, y))
cost -= 2 * tf.reduce_mean(kernel(x, y))
# We do not allow the loss to become negative.
cost = tf.where(cost > 0, cost, 0, name='value')
return cost
add_autoencoders
其中encoder和decoder的结构类似于Lenet。
def add_autoencoders(source_data, source_shared, target_data, target_shared,
params):
"""Adds the encoders/decoders for our domain separation model w/ incoherence.
Args:
source_data: images from the source domain, a tensor of size
[batch_size, height, width, channels]
source_shared: a tensor with first dimension batch_size
target_data: images from the target domain, a tensor of size
[batch_size, height, width, channels]
target_shared: a tensor with first dimension batch_size
params: A dictionary of parameters. Expecting 'layers_to_regularize',
'beta_weight', 'alpha_weight', 'recon_loss_name', 'decoder_name',
'encoder_name', 'weight_decay'
"""
def normalize_images(images):
images -= tf.reduce_min(images)
return images / tf.reduce_max(images)
def concat_operation(shared_repr, private_repr):
return shared_repr + private_repr
mu = dsn_loss_coefficient(params)
# The layer to concatenate the networks at.
concat_layer = params['layers_to_regularize']
# The coefficient for modulating the private/shared difference loss.
difference_loss_weight = params['beta_weight'] * mu
# The reconstruction weight.
recon_loss_weight = params['alpha_weight'] * mu
# The reconstruction loss to use.
recon_loss_name = params['recon_loss_name']
# The decoder/encoder to use.
decoder_name = params['decoder_name']
encoder_name = params['encoder_name']
_, height, width, _ = source_data.get_shape().as_list()
code_size = source_shared.get_shape().as_list()[-1]
weight_decay = params['weight_decay']
encoder_fn = getattr(models, encoder_name)
# Target Auto-encoding.
with tf.variable_scope('source_encoder'):
source_endpoints = encoder_fn(
source_data, code_size, weight_decay=weight_decay)
with tf.variable_scope('target_encoder'):
target_endpoints = encoder_fn(
target_data, code_size, weight_decay=weight_decay)
decoder_fn = getattr(models, decoder_name)
decoder = partial(
decoder_fn,
height=height,
width=width,
channels=source_data.get_shape().as_list()[-1],
weight_decay=weight_decay)
# Source Auto-encoding.
source_private = source_endpoints[concat_layer]
target_private = target_endpoints[concat_layer]
with tf.variable_scope('decoder'):
source_recons = decoder(concat_operation(source_shared, source_private))
with tf.variable_scope('decoder', reuse=True):
source_private_recons = decoder(
concat_operation(tf.zeros_like(source_private), source_private))
source_shared_recons = decoder(
concat_operation(source_shared, tf.zeros_like(source_shared)))
with tf.variable_scope('decoder', reuse=True):
target_recons = decoder(concat_operation(target_shared, target_private))
target_shared_recons = decoder(
concat_operation(target_shared, tf.zeros_like(target_shared)))
target_private_recons = decoder(
concat_operation(tf.zeros_like(target_private), target_private))
losses.difference_loss(
source_private,
source_shared,
weight=difference_loss_weight,
name='Source')
losses.difference_loss(
target_private,
target_shared,
weight=difference_loss_weight,
name='Target')
add_reconstruction_loss(recon_loss_name, source_data, source_recons,
recon_loss_weight, 'source')
add_reconstruction_loss(recon_loss_name, target_data, target_recons,
recon_loss_weight, 'target')
decoder
def small_decoder(codes,
height,
width,
channels,
batch_norm_params=None,
weight_decay=0.0):
"""Decodes the codes to a fixed output size.
Args:
codes: a tensor of size [batch_size, code_size].
height: the height of the output images.
width: the width of the output images.
channels: the number of the output channels.
batch_norm_params: a dictionary that maps batch norm parameter names to
values.
weight_decay: the value for the weight decay coefficient.
Returns:
recons: the reconstruction tensor of shape [batch_size, height, width, 3].
"""
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
net = slim.fully_connected(codes, 300, scope='fc1')
batch_size = net.get_shape().as_list()[0]
net = tf.reshape(net, [batch_size, 10, 10, 3])
net = slim.conv2d(net, 16, [3, 3], scope='conv1_1')
net = slim.conv2d(net, 16, [3, 3], scope='conv1_2')
output_size = [height, width]
net = tf.image.resize_nearest_neighbor(net, output_size)
with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]):
net = slim.conv2d(net, 16, scope='conv2_1')
net = slim.conv2d(net, channels, activation_fn=None, scope='conv2_2')
return net
encoder
def default_encoder(images, code_size, batch_norm_params=None,
weight_decay=0.0):
"""Encodes the given images to codes of the given size.
Args:
images: a tensor of size [batch_size, height, width, 1].
code_size: the number of hidden units in the code layer of the classifier.
batch_norm_params: a dictionary that maps batch norm parameter names to
values.
weight_decay: the value for the weight decay coefficient.
Returns:
end_points: the code of the input.
"""
end_points = {}
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay),
activation_fn=tf.nn.relu,
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.conv2d], kernel_size=[5, 5], padding='SAME'):
net = slim.conv2d(images, 32, scope='conv1')
net = slim.max_pool2d(net, [2, 2], 2, scope='pool1')
net = slim.conv2d(net, 64, scope='conv2')
net = slim.max_pool2d(net, [2, 2], 2, scope='pool2')
net = slim.flatten(net)
end_points['flatten'] = net
net = slim.fully_connected(net, code_size, scope='fc1')
end_points['fc3'] = net
return end_points
shared encoder
basic_tower_name代表作为shared encoder的tower名字。
def dann_mnist(images,
weight_decay=0.0,
prefix='model',
num_classes=10,
**kwargs):
"""Creates a convolution MNIST model.
Note that this model implements the architecture for MNIST proposed in:
Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN),
JMLR 2015
Args:
images: the MNIST digits, a tensor of size [batch_size, 28, 28, 1].
weight_decay: the value for the weight decay coefficient.
prefix: name of the model to use when prefixing tags.
num_classes: the number of output classes to use.
**kwargs: Placeholder for keyword arguments used by other shared encoders.
Returns:
the output logits, a tensor of size [batch_size, num_classes].
a dictionary with key/values the layer names and tensors.
"""
end_points = {}
with slim.arg_scope(
[slim.conv2d, slim.fully_connected],
weights_regularizer=slim.l2_regularizer(weight_decay),
activation_fn=tf.nn.relu,):
with slim.arg_scope([slim.conv2d], padding='SAME'):
end_points['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1')
end_points['pool1'] = slim.max_pool2d(
end_points['conv1'], [2, 2], 2, scope='pool1')
end_points['conv2'] = slim.conv2d(
end_points['pool1'], 48, [5, 5], scope='conv2')
end_points['pool2'] = slim.max_pool2d(
end_points['conv2'], [2, 2], 2, scope='pool2')
end_points['fc3'] = slim.fully_connected(
slim.flatten(end_points['pool2']), 100, scope='fc3')
end_points['fc4'] = slim.fully_connected(
slim.flatten(end_points['fc3']), 100, scope='fc4')
logits = slim.fully_connected(
end_points['fc4'], num_classes, activation_fn=None, scope='fc5')
return logits, end_points


















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









