







 本文介绍了迁移学习的基本概念,包括迁移学习的动机和优势,并详细阐述了迁移学习的分类,如监督、半监督和无监督迁移学习。接着,讨论了迁移学习的方法,如基于样本、特征、模型和关系的迁移。此外,探讨了深度迁移学习,特别是深度神经网络在迁移学习中的应用,如Finetune和对抗学习。最后,文章总结了迁移学习在计算机视觉、自然语言处理等多个领域的应用,并指出其在强化学习领域的潜在价值。
本文介绍了迁移学习的基本概念,包括迁移学习的动机和优势,并详细阐述了迁移学习的分类,如监督、半监督和无监督迁移学习。接着,讨论了迁移学习的方法,如基于样本、特征、模型和关系的迁移。此外,探讨了深度迁移学习,特别是深度神经网络在迁移学习中的应用,如Finetune和对抗学习。最后,文章总结了迁移学习在计算机视觉、自然语言处理等多个领域的应用,并指出其在强化学习领域的潜在价值。
迁移学习通过利用数据、任务或模型之间的相似性,将在旧领域学习过的模型应用于新领域来求解新问题。生活中常用的“举一反三”、“照猫画虎”就很好地体现了迁移学习的思想。利用迁移学习的思想,可以将已有的一些训练好的模型,迁移到我们的任务中,针对具体的任务进行微调来降低学习和训练的成本,此外还可以考虑不同任务之间的相似性和差异性,采用自适应学习,对模型进行灵活的调整,以满足不同需求。
迁移学习的基本概念
迁移学习简介
迁移学习(transfer learning)就是运用已有的知识来学习新的知识,核心是找到已有知识和新知识之间的相似性,由于直接对目标域从头开始学习成本太高,我们故而转向运用已有的相关知识来辅助尽快地学习新知识。比如,已经会下中国象棋,就可以类比着来学习国际象棋;已经学会骑自行车,就可以类比着来学习骑电动车;已经学会英语,就可以类比着来学习法语;等等。世间万事万物皆有共性,如何合理地找寻它们之间的相似性和差异性,进而利用这种相似性或差异性来帮助学习新知识,是迁移学习的核心问题[1]。
为什么要进行迁移
在文献[2]中,王晋东等人将为什么要进行迁移学习的原因总结为四个方面:
大数据与少标注之间的矛盾:我们所处的大数据时代每时每刻产生着海量的数据,但是这些数据缺乏完善的数据标注,而机器学习模型的训练和更新都依赖于数据的标注,目前只有很少的数据被标注和利用,这给机器学习和深度学习的模型训练和更新带来了挑战。
大数据与弱计算之间的矛盾:海量的数据需要强计算能力的设备进行存储和计算,强计算能力通常是非常昂贵的,此外使用海量数据来训练模型是非常耗时的,这就导致了大数据与弱计算之间的矛盾。
普适化模型与个性化需求之间的矛盾:机器学习的目的是构建尽可能通用的模型来满足不同用户、不同设备、不同环境的不同需求,这就要求模型有高的泛化能力,但是实际中普世化的通用模型无法满足个性化、差异化的需求,这就导致了模型同个性化需求之间的矛盾。
特定应用的需求:现实中往往存在着一些特定的应用,比如推荐系统的冷启动问题,这就需要我们尽可能利用已有的模型或知识来求解问题。
传统机器学习的方法不能解决这些矛盾,迁移学习则为这些矛盾的解决提供了思路,迁移学习的优点通常可以被总结为以下三个方面:
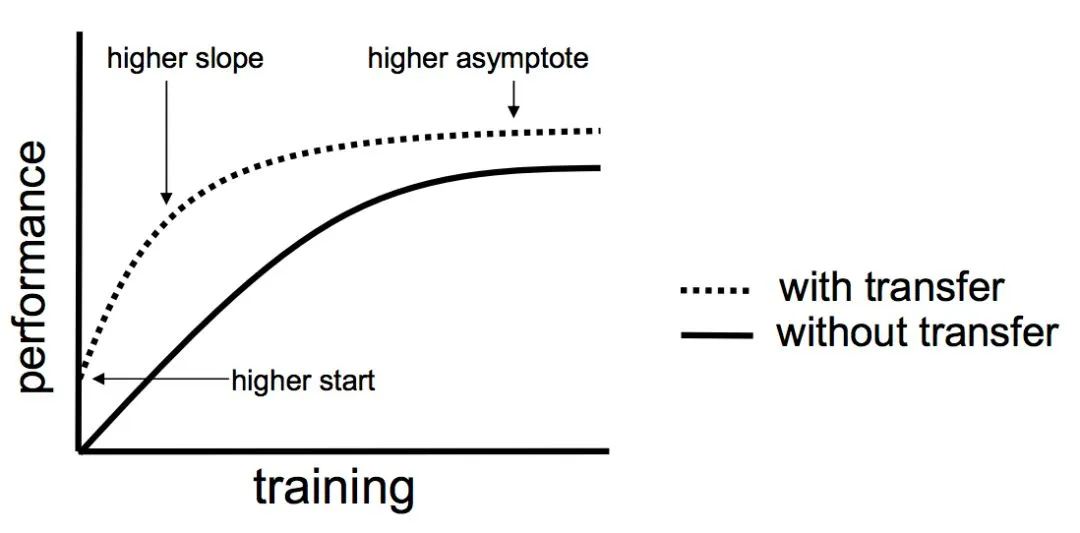
更高的起点。在微调之前,源模型的初始性能要比不使用迁移学习来的高。
更高的斜率。在训练的过程中源模型提升的速率要比不使用迁移学习来得快。
更高的渐进。训练得到的模型的收敛性能要比不使用迁移学习更好。
迁移学习与传统机器学习的区别
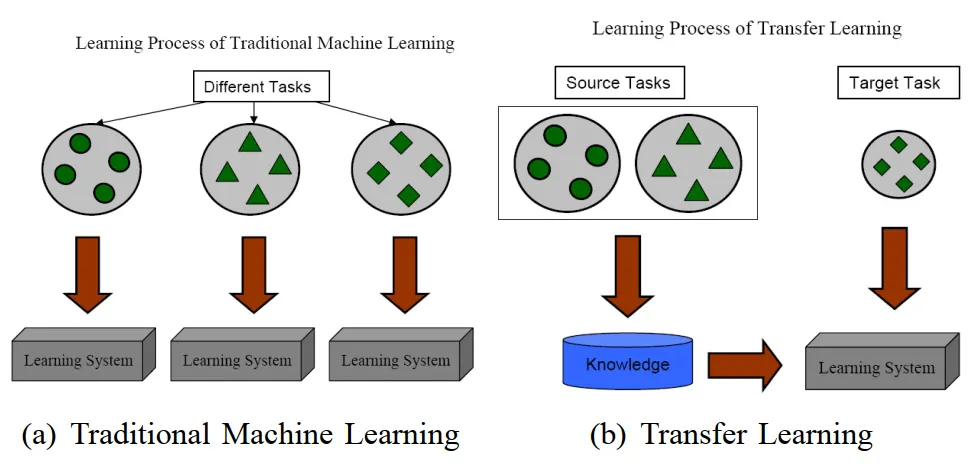
迁移学习是机器学习的一类,但是与传统机器学习又有所不同。传统迁移学习针对不同的学习任务建立不同的模型,迁移学习利用源域中的数据将知识迁移到目标与,完成模型的建立。
比较项目 |
传统机器学习 |
迁移学习 |
数据分布 |
训练和测试数据服从相同的分布 |
训练和测试数据服从不同的分布 |
数据标注 |
需要足够的数据标注来训练模型 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3129
3129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









