




 本文深入解析Scrapy框架的运行流程,涵盖Scrapy引擎、调度器、下载器等关键组件,以及Spider、ItemPipeline和中间件的工作原理。通过理解各部分如何协作,帮助读者掌握Scrapy的使用技巧。
本文深入解析Scrapy框架的运行流程,涵盖Scrapy引擎、调度器、下载器等关键组件,以及Spider、ItemPipeline和中间件的工作原理。通过理解各部分如何协作,帮助读者掌握Scrapy的使用技巧。
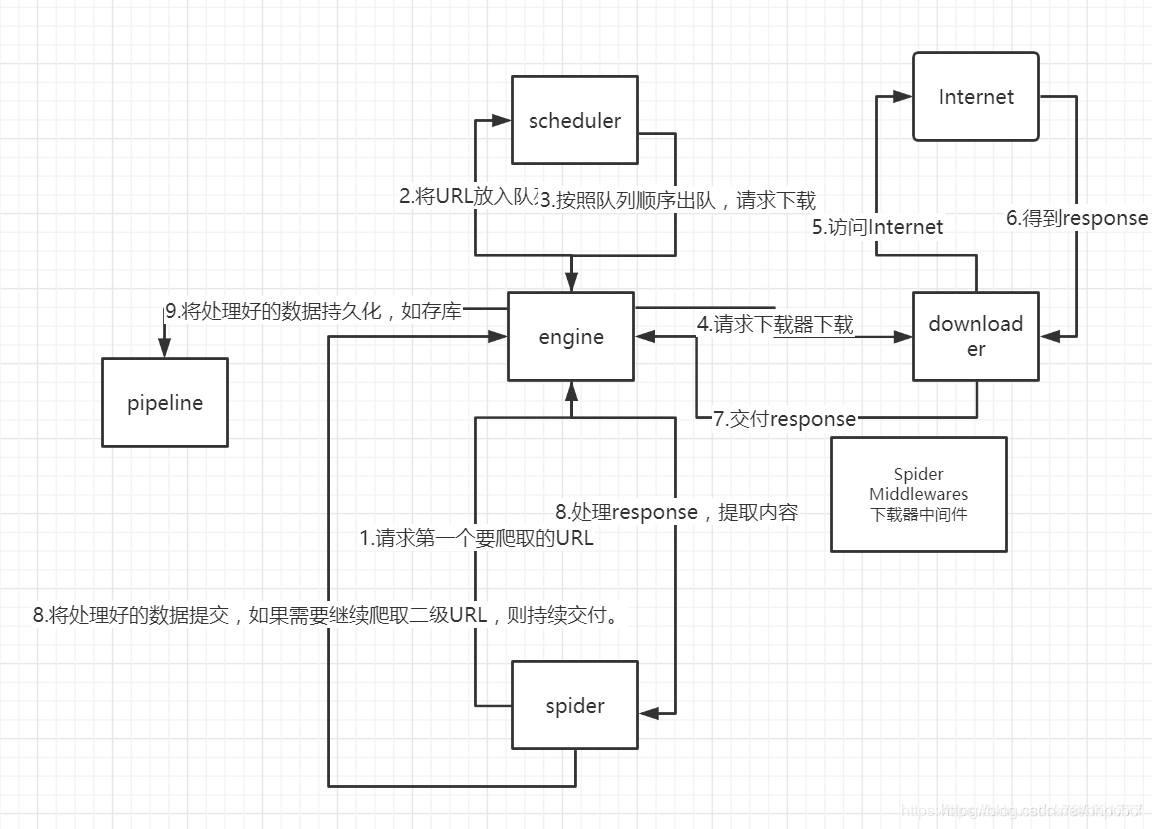
各个模块的介绍:
Scrapy Engine(Scrapy引擎)
核心,负责控制数据流在系统中所有的组件中流动,
并在相应的动作发生时触发事件。
Scheduler(调度器)
从引擎接受 request 并让其入队,以便之后引擎请求
它们时提供给引擎。
Downloader(下载器)
获取页面数据并提供给引擎,而后提供给Spider。
Spiders(蜘蛛…)
编写用于分析由下载器返回的response,并提取出item
和额外跟进的URL的类。
Item Pipeline(项目管道)
负责处理处理被Spider提取出来的item。常见的处理有:
清理、验证和持久化。
Download Middlewares(下载器中间件)
引擎与下载器间的特定钩子,处理下载器传递给引擎的Response。
Spider Middlewares(Spider中间件)
引擎与Spider间的特定钩子,处理Spider输入(下载器的Response)和
输出(发送给items给Item Pipeline,以及发送Request给调度器)
————————————————
版权声明:本文为优快云博主「coder-pig」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/coder_pig/article/details/78933436
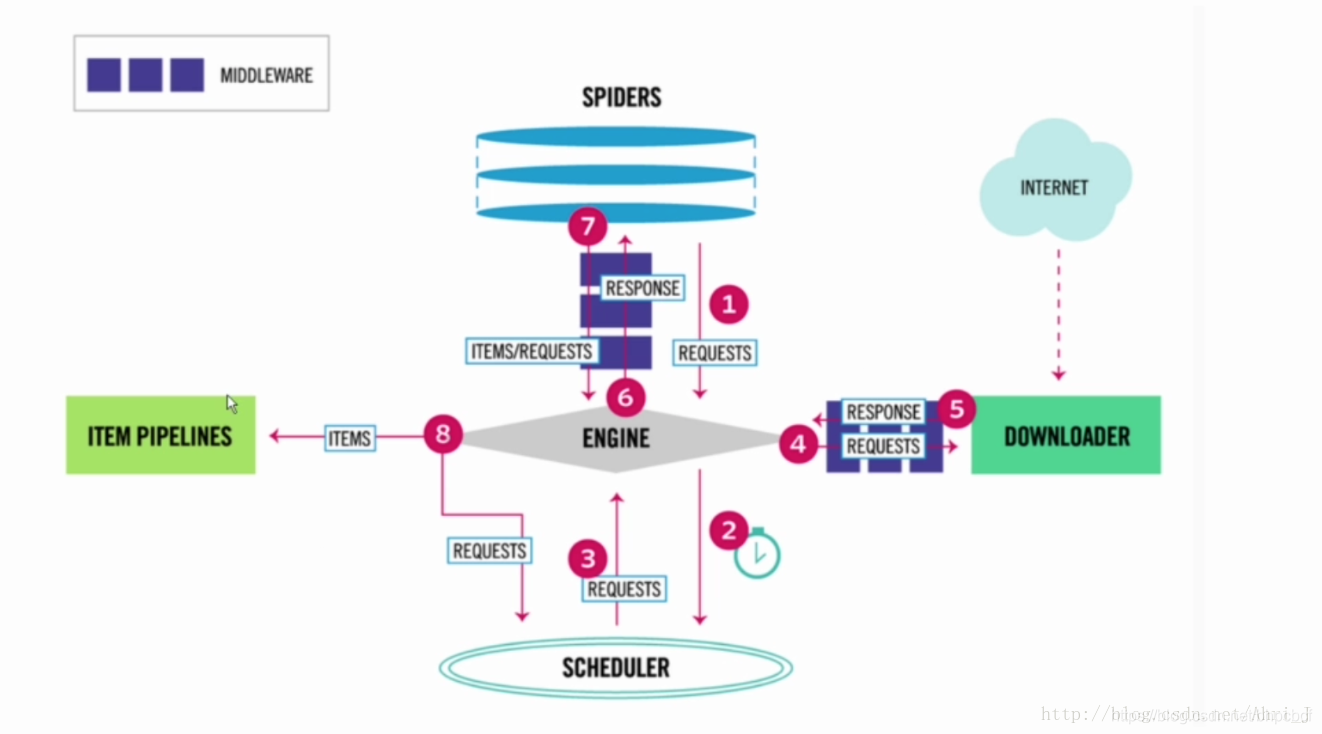
1.Spider 爬虫部分发送请求,通过 spidermiddleware 中间层处理后发送给 ENGINE 引擎模块
2.引擎模块将请求发送给 SCHEDULER 模块进行调度
3.SCHEDULER 模块将可以执行的请求调度给引擎模块
4.引擎模块将请求发送给 DOWNLOADER 下载模块进行下载,期间会经过 download middleware 进行处理
5.下载模块将爬取好的网页响应经过 downloadermiddleware 中间层处理后传递给引擎模块
6.引擎模块将响应传递给 Spider 爬虫模块
7.在爬虫模块我们自定义解析方式对响应解析完成后生成 Item 对象或者新的 Request对象,经过 spiddermiddleware 发送给引擎模块
8.如果是 Item 对象传递给 item 和 pipeline 来进行对应的处理; 如果是 Request 对象则继续调度下载,重复之前的步骤。
上面就是整个 Scrapy 的执行流程了,了解了大致的流程后,后面就是对各个流程中的知识点进行学习了,包括网页的解析,请求响应的中间层处理,item 与 pipeline 对数据的处理以及可能遇到的问题以及解决方案,将在后面的文章中逐个讲解,梳理内容,巩固所学,也希望对需要的同学有所帮助。
————————————————
版权声明:本文为优快云博主「AhriJ邹同学」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/Ahri_J/article/details/71703001
信息提取:
1.beautiful soup
2.re
3.XPath selector
4.xlml
5.css selector

















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









