




 本文详细介绍使用Scrapy框架创建并运行爬虫的步骤。从建立工程到生成爬虫,再到配置与运行,逐步解析核心命令与关键配置,助您快速上手爬虫开发。
本文详细介绍使用Scrapy框架创建并运行爬虫的步骤。从建立工程到生成爬虫,再到配置与运行,逐步解析核心命令与关键配置,助您快速上手爬虫开发。
看图,输入相关的命令
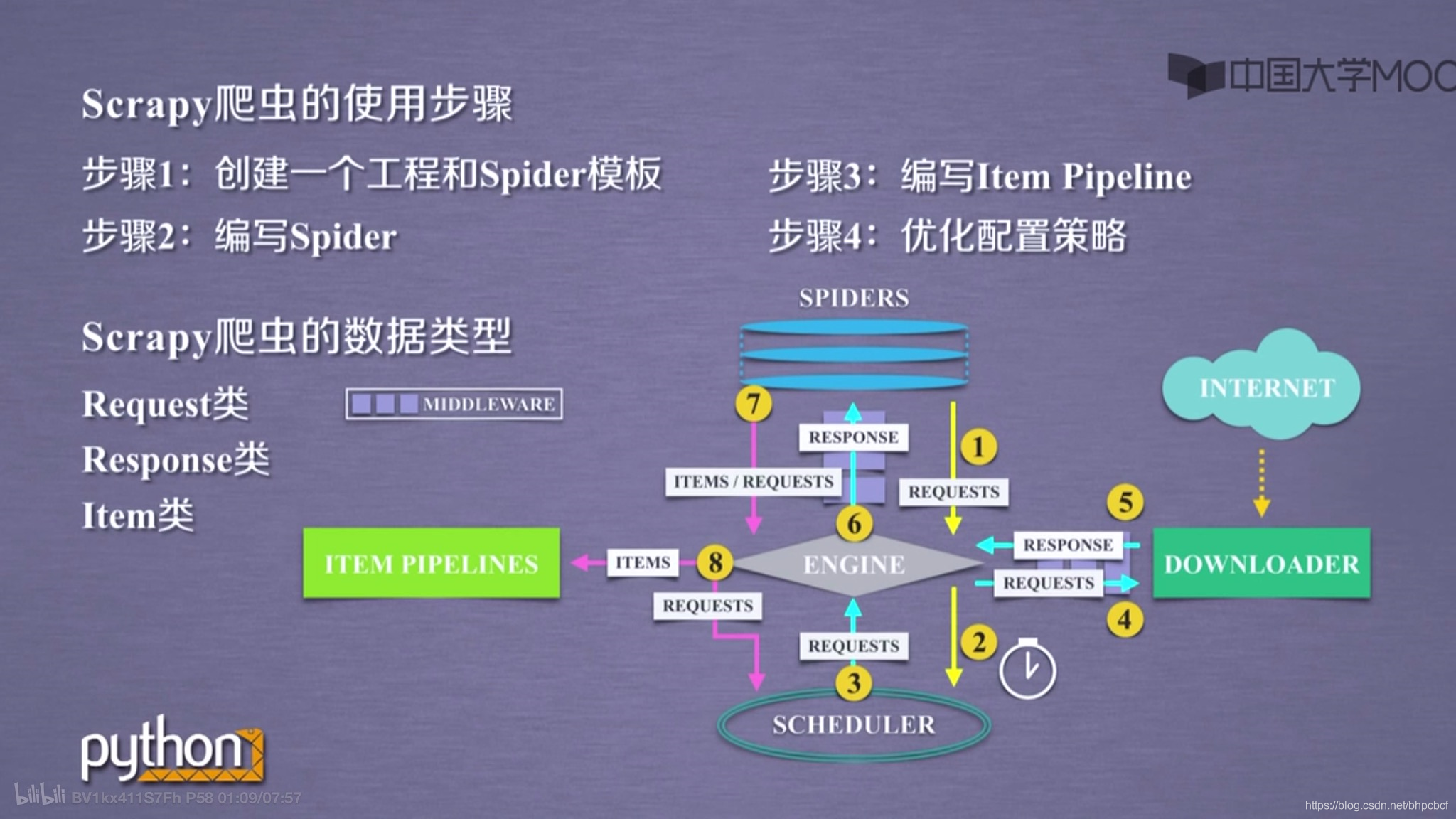
第一步.建立一个爬虫工程
输入,scrapy startproject python123demo
回车后可以看到在自己的默认路径下建立了一个目录
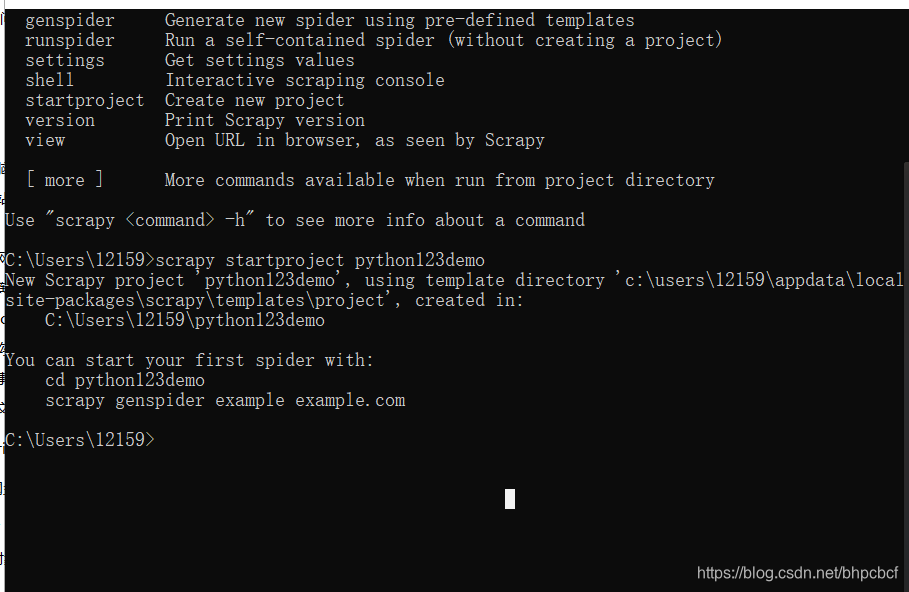
图1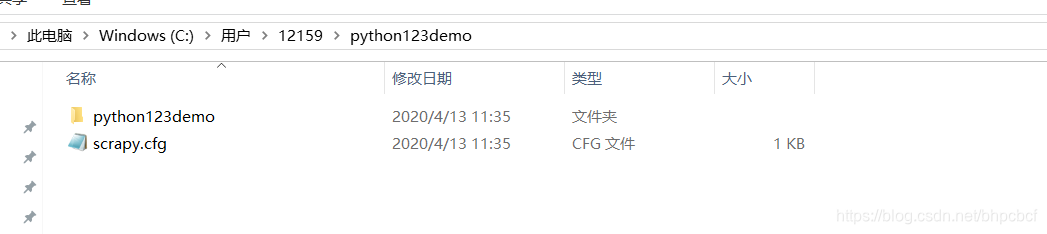
图2

-pycache_这个文件是缓存。
第2步,在工程中产生一个爬虫
scrapy gendpider demo python123.io
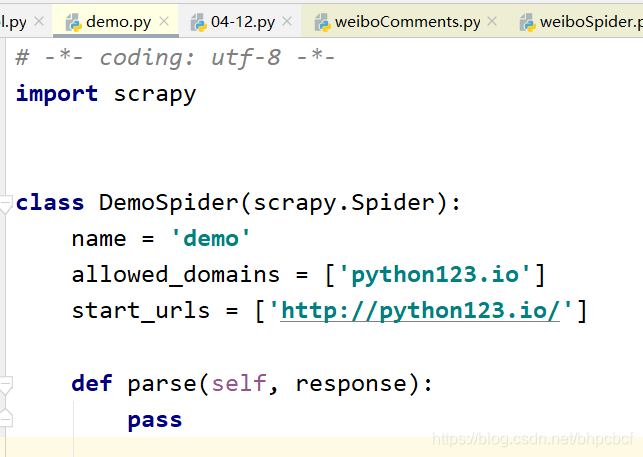
parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
第三步,配置产生的spider爬虫
修改demo文件
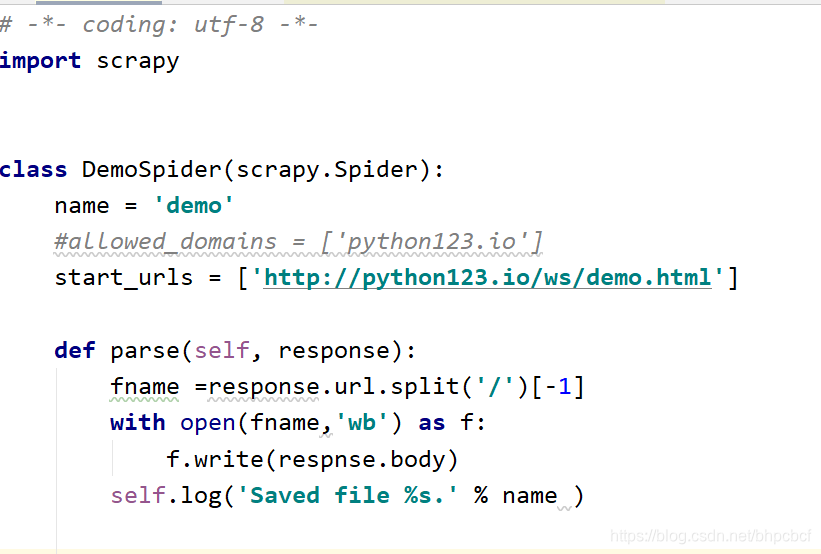
第四步,运行爬虫




















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









