




RagFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation,检索增强生成)引擎。它的设计核心在于将大量复杂格式的非结构化数据(如 PDF、Word、PPT、Excel、图片、网页等)经过智能解析,转换为高质量的“知识片段”,再通过大语言模型(LLM)进行增强生成,从而实现准确、可控且有据可依的问答服务
📋 先决条件
- 安装并启动了Docker、Ollama(没有安装的可以参考之前的教程)
📖 开始部署
1. 下载RagFlow
方式1:通过git克隆的方式下载,需要安装了Git。
git clone https://github.com/infiniflow/ragflow.git
方式2:直接访问github下载.ZIP压缩包,下载后解压。
https://github.com/infiniflow/ragflow
2. 修改一些配置
打开 ragflow里docker下的.env 文件,该文件主要用于配置RagFlow的各种环境变量
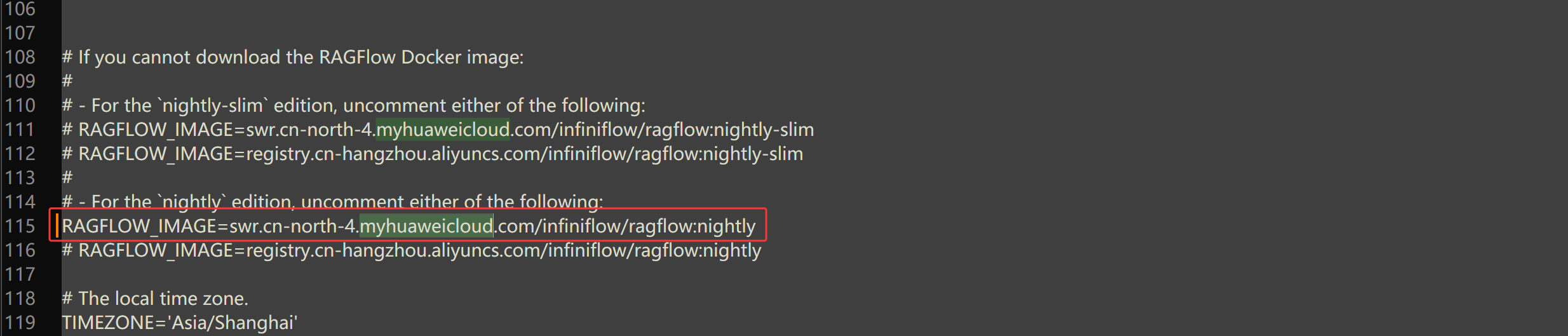
搜索 myhuaweicloud,这里有两处,将后面这一行的注释放开,修改后保存
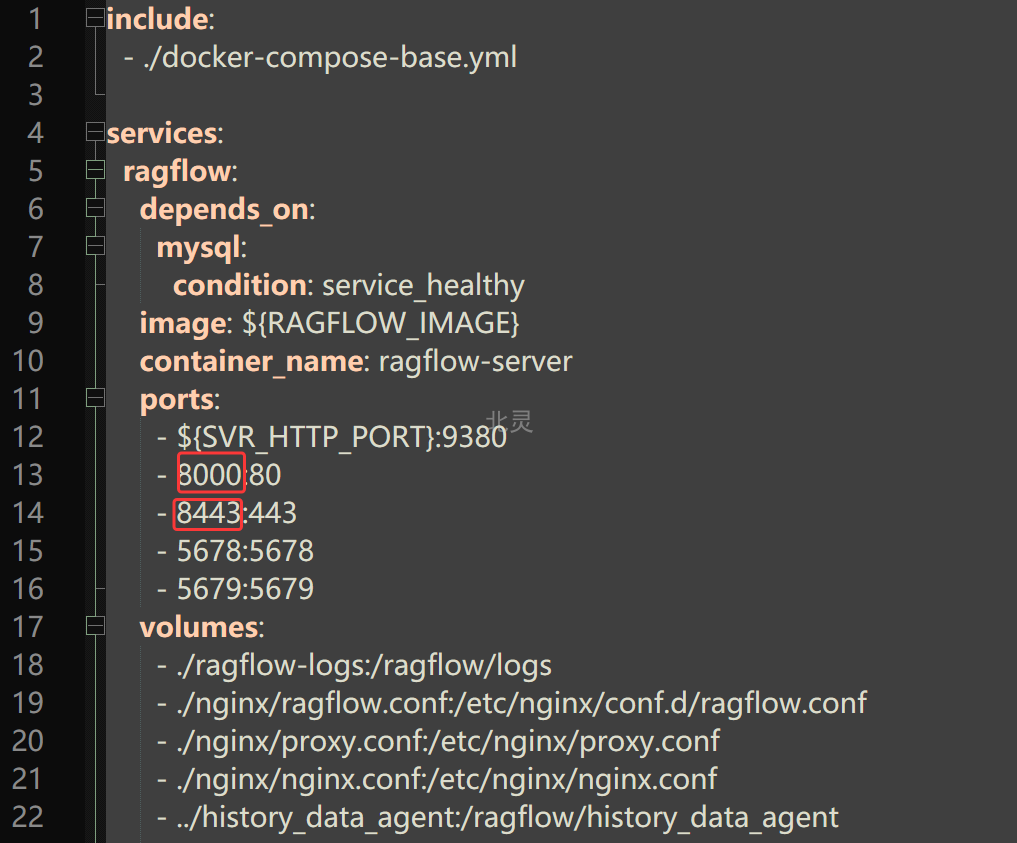
默认端口为80,为避免与其他应用端口冲突,修改端口:ragflow/docker/docker-compose.yml
将 80 修改为 8000 ,将 443 修改为8443,修改后保存
3. 使用Docker安装RagFlow
在ragflow/docker目录下,执行:
cd D:\ProgramFiles\ragflow\docker # 这里换成你自己的目录
docker compose up -d
耐心等待镜像下载,全部下载好后,容器都是运行状态则正常。

登录RagFlow
运行成功后,浏览器访问:http://localhost:8000/login
首次登录需要先点击Sign up注册账号
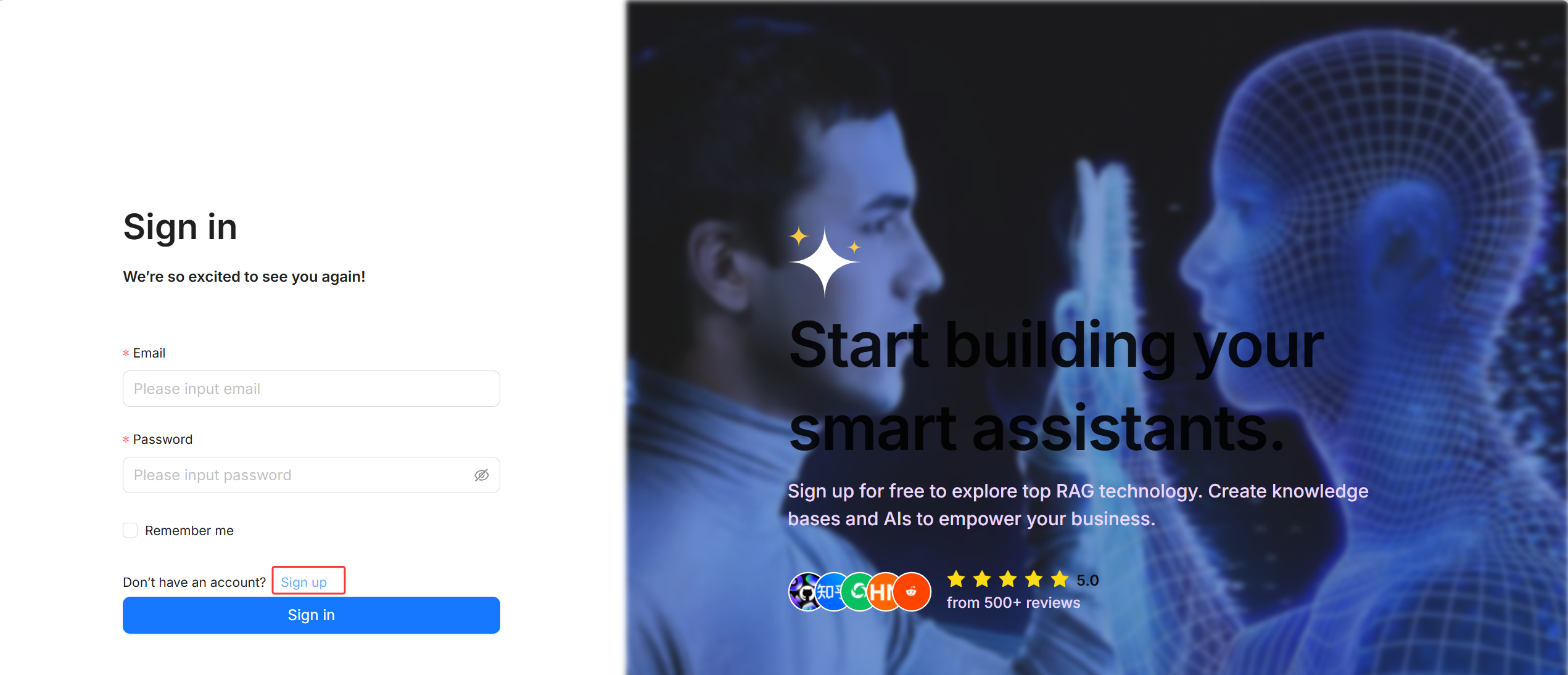
填写任意邮箱,昵称,密码,点击Continue注册,然后点Sign in 用创建的邮箱密码登录
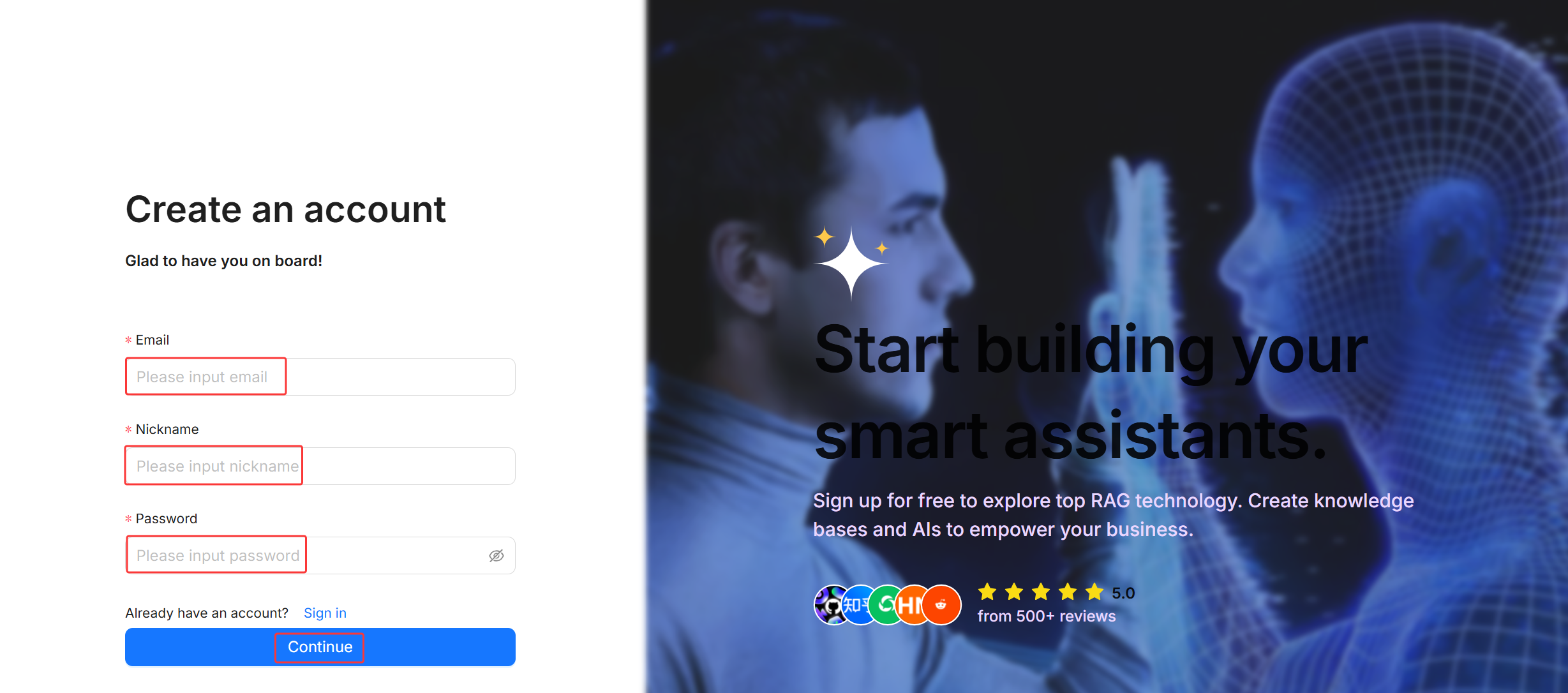
登录后页面如下,点击右上角可以设置语言
配置模型
1. 获取API Key
如果是个人学习、开发使用,可以使用硅基流动提供的或者使用自己本地部署的大模型。硅基流动提供多种大模型可供调用,包括当下流行的DeepSeek-R1,DeepSeek-V3、QwQ-32B、BGE-M3 等等
目前注册可以免费领取2000万token,用来学习基本也够了
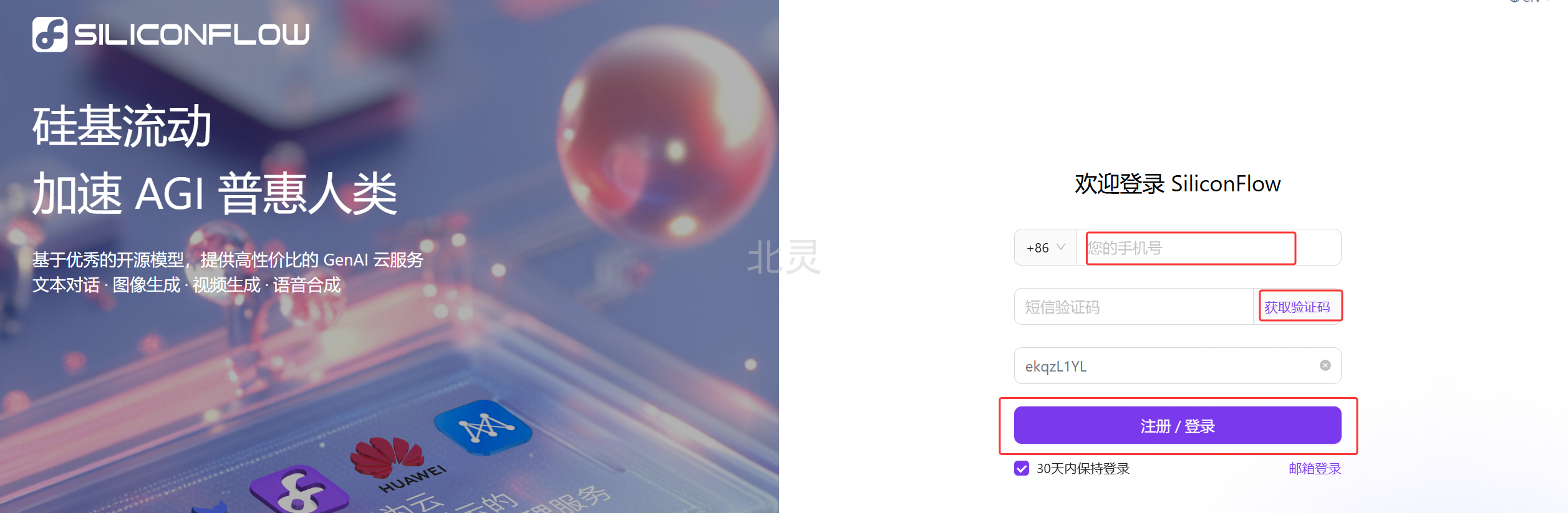
官方注册地址
输入手机号、短信验证码,登录即可,没有注册过会自动注册
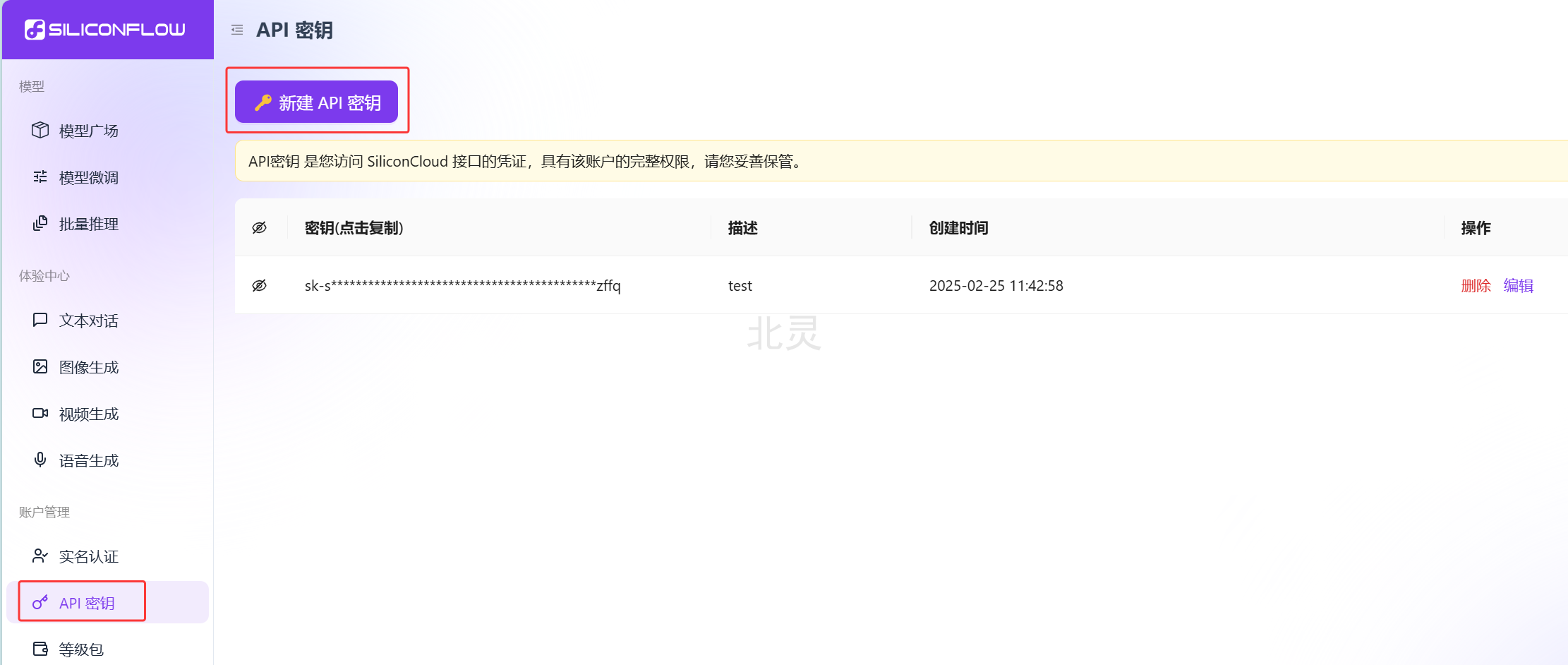
API密钥 -> 新建 API 密钥。将新建好的密钥妥善保管
2. 添加模型供应商
右上角头像 -> 模型供应商 -> 添加模型

将之前建好的 API 密钥填入,点击确定
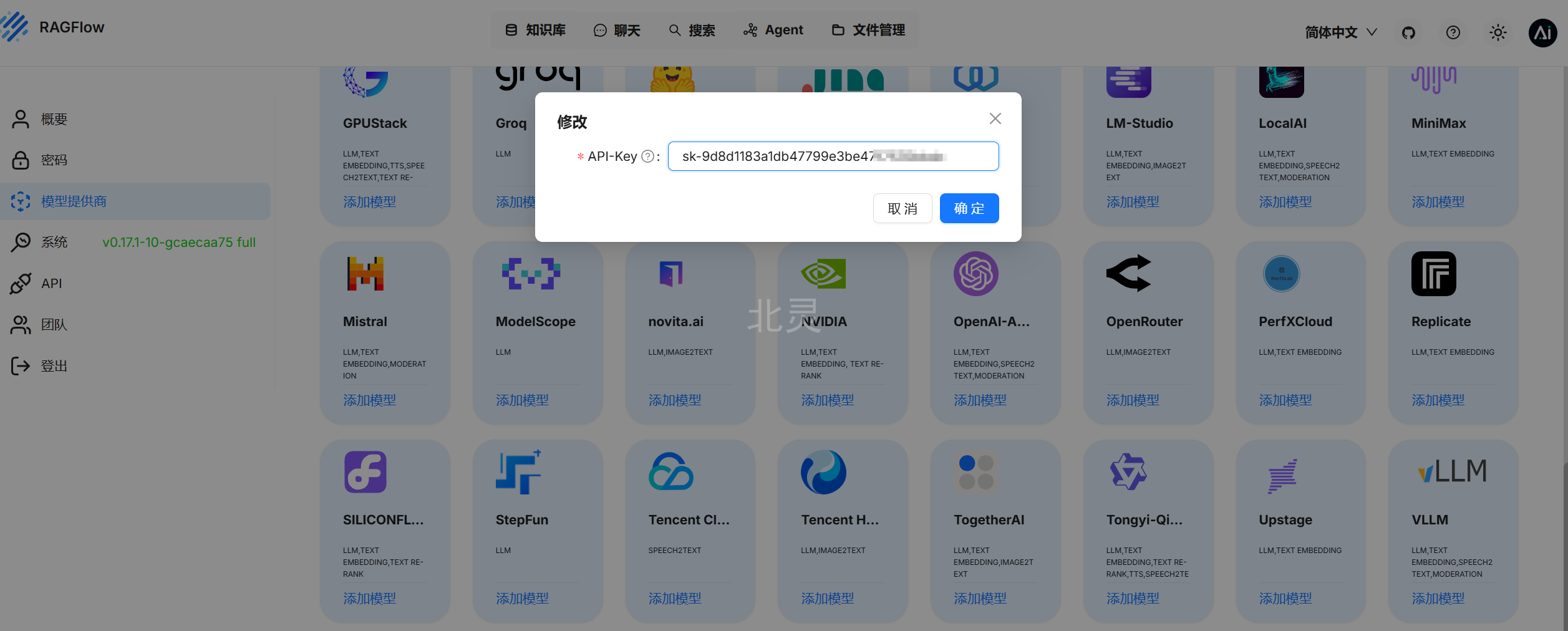
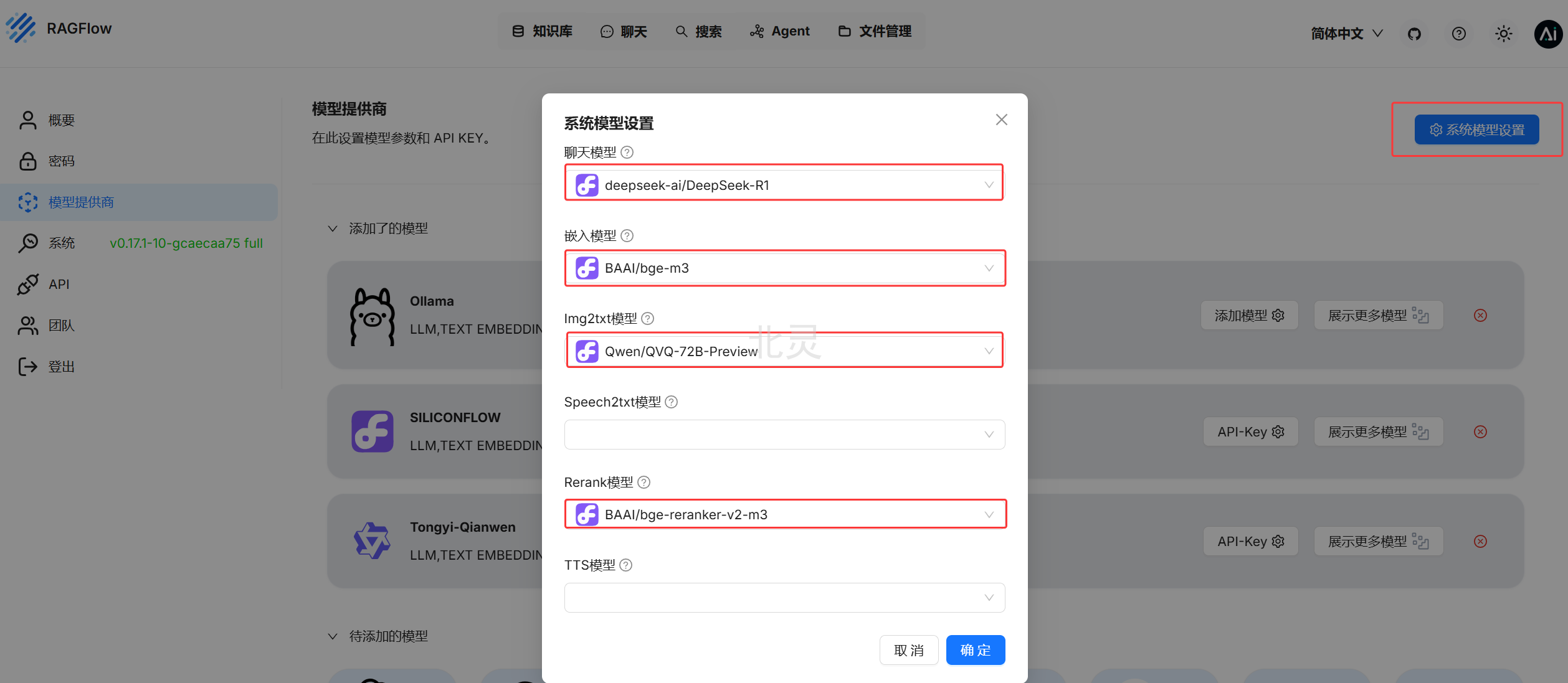
3. 系统模型设置
设置好后点击确定
添加知识库
知识库 -> 创建知识库
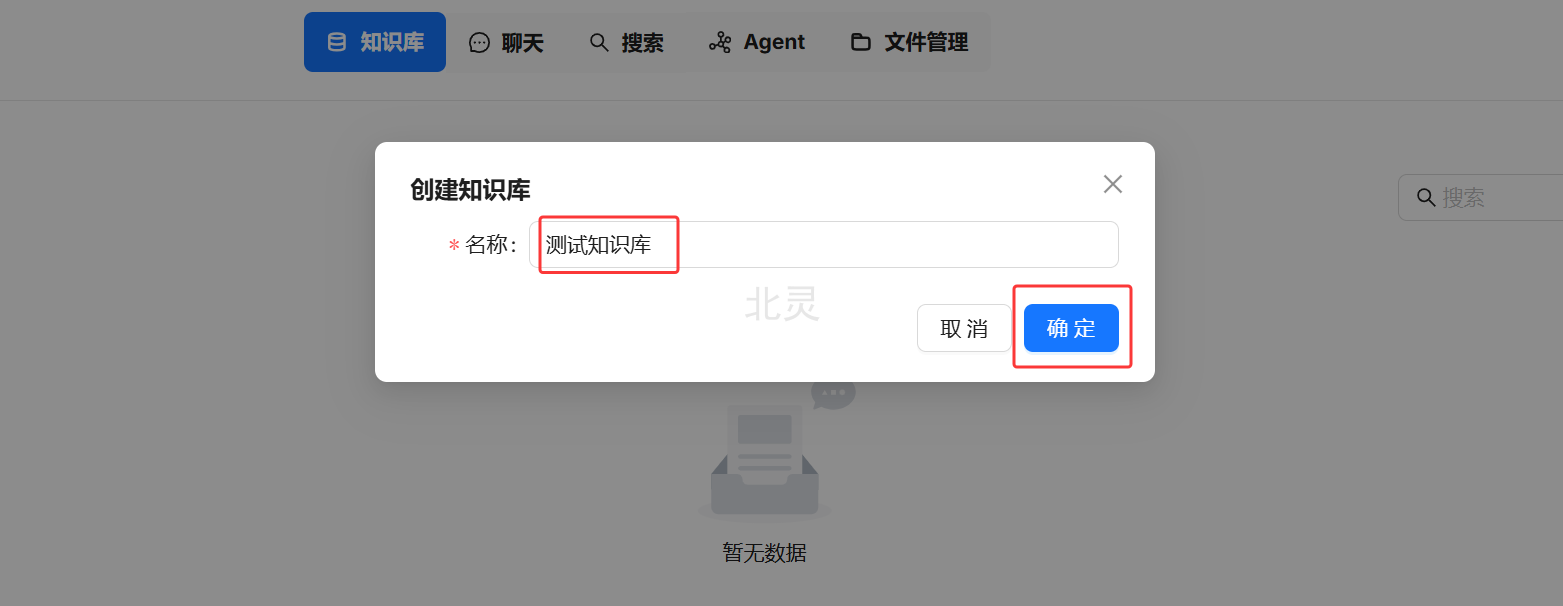
输入知识库名称,点击确定
数据集 -> 新增文件 -> 本地文件
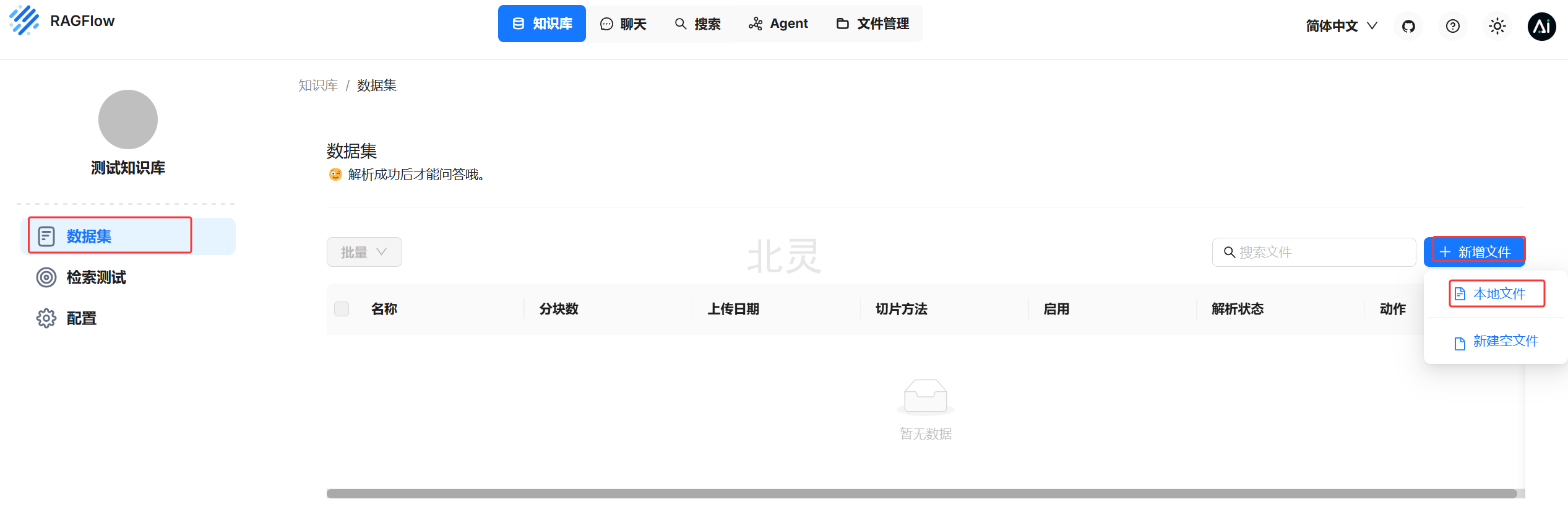
数据集需要解析后才能用于回答。可以勾选创建时解析,也可以上传后再解析,这里我们勾选创建时解析
默认是上传文件,也可以上传文件夹。点击下方区域选择要上传的文件,点击确定
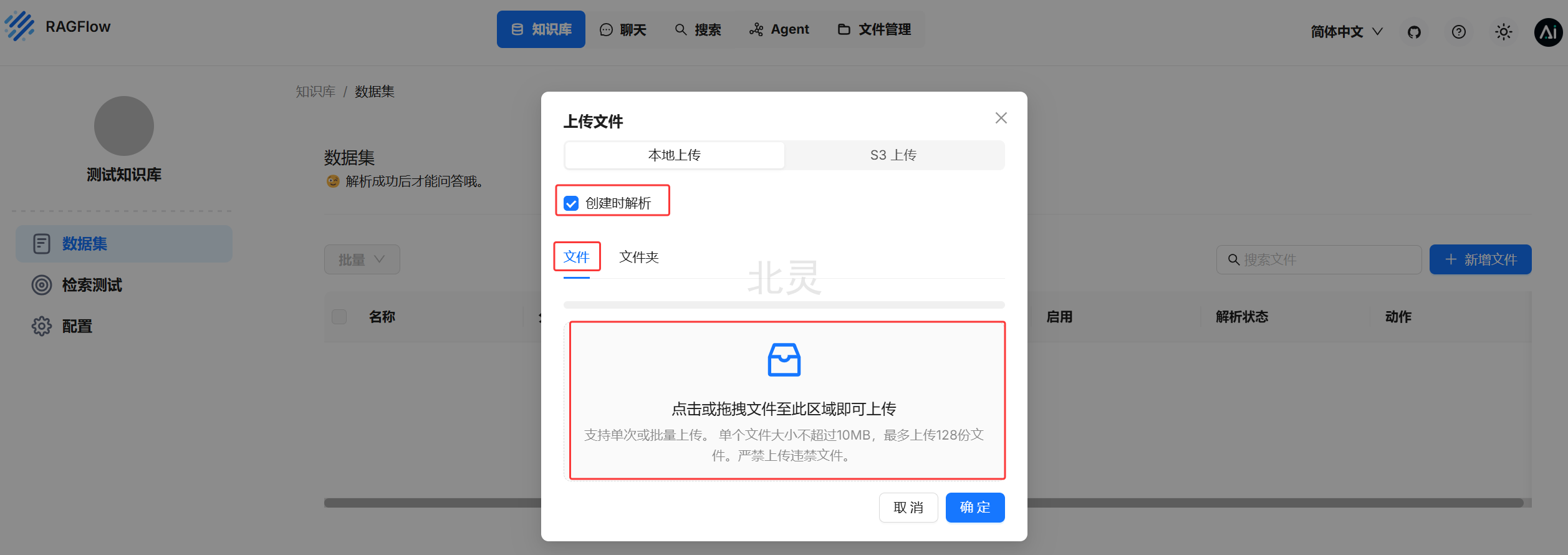
解析中,等待解析成功
测试
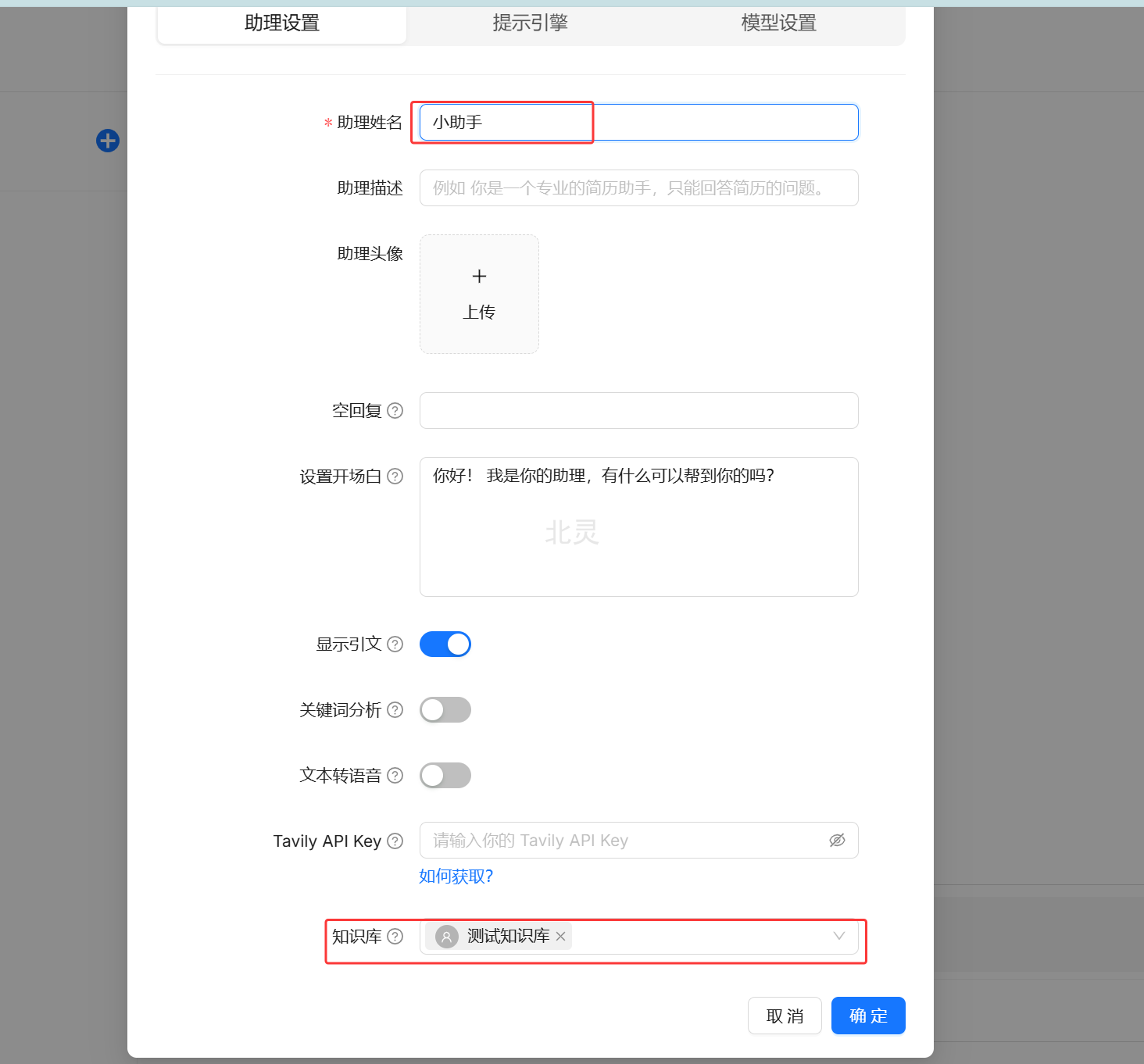
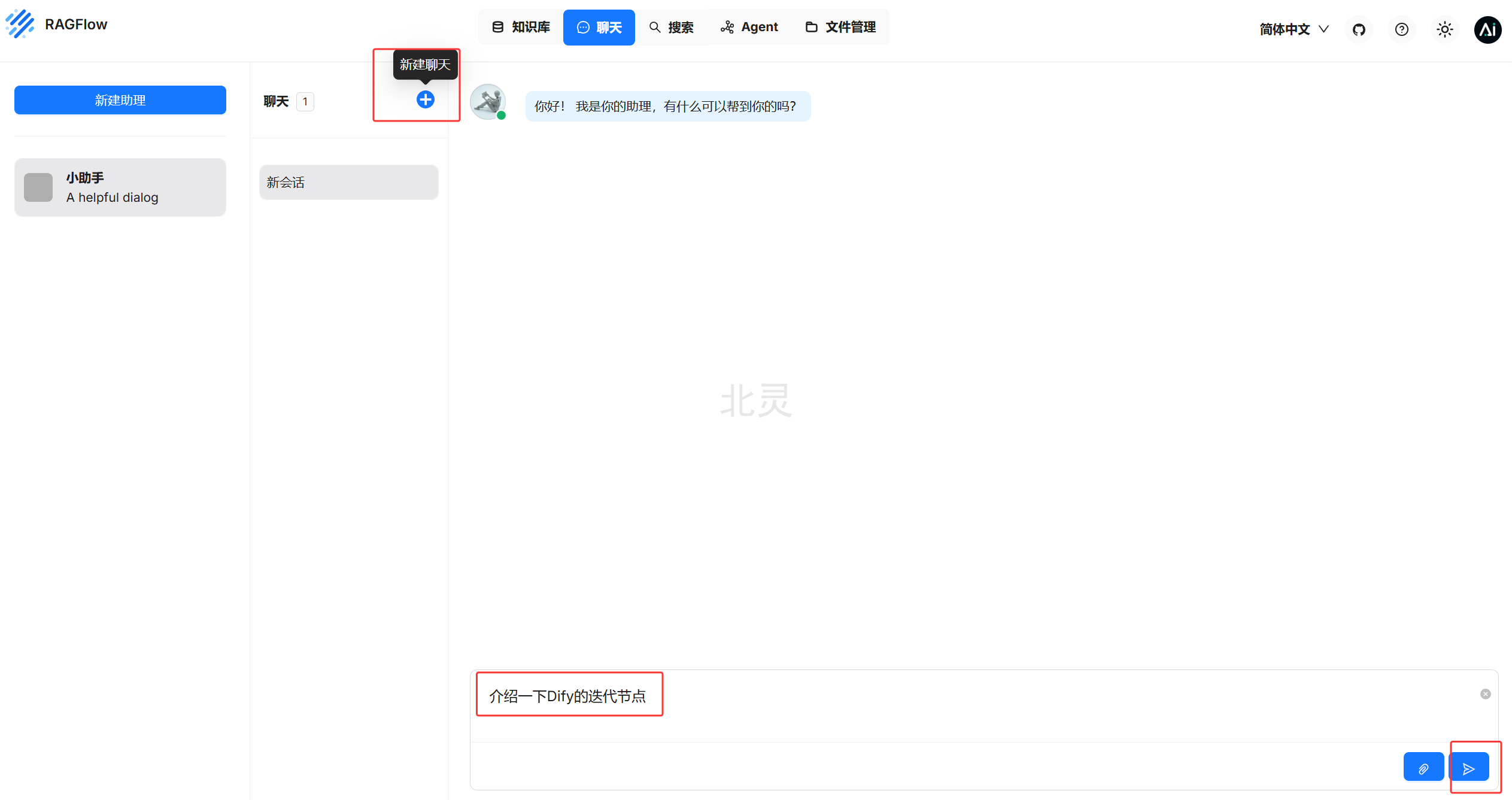
聊天 -> 新建助理

输入助理姓名、选择知识库
新建聊天,在聊天框输入问题测试知识库,可以看到引用了知识库的内容。
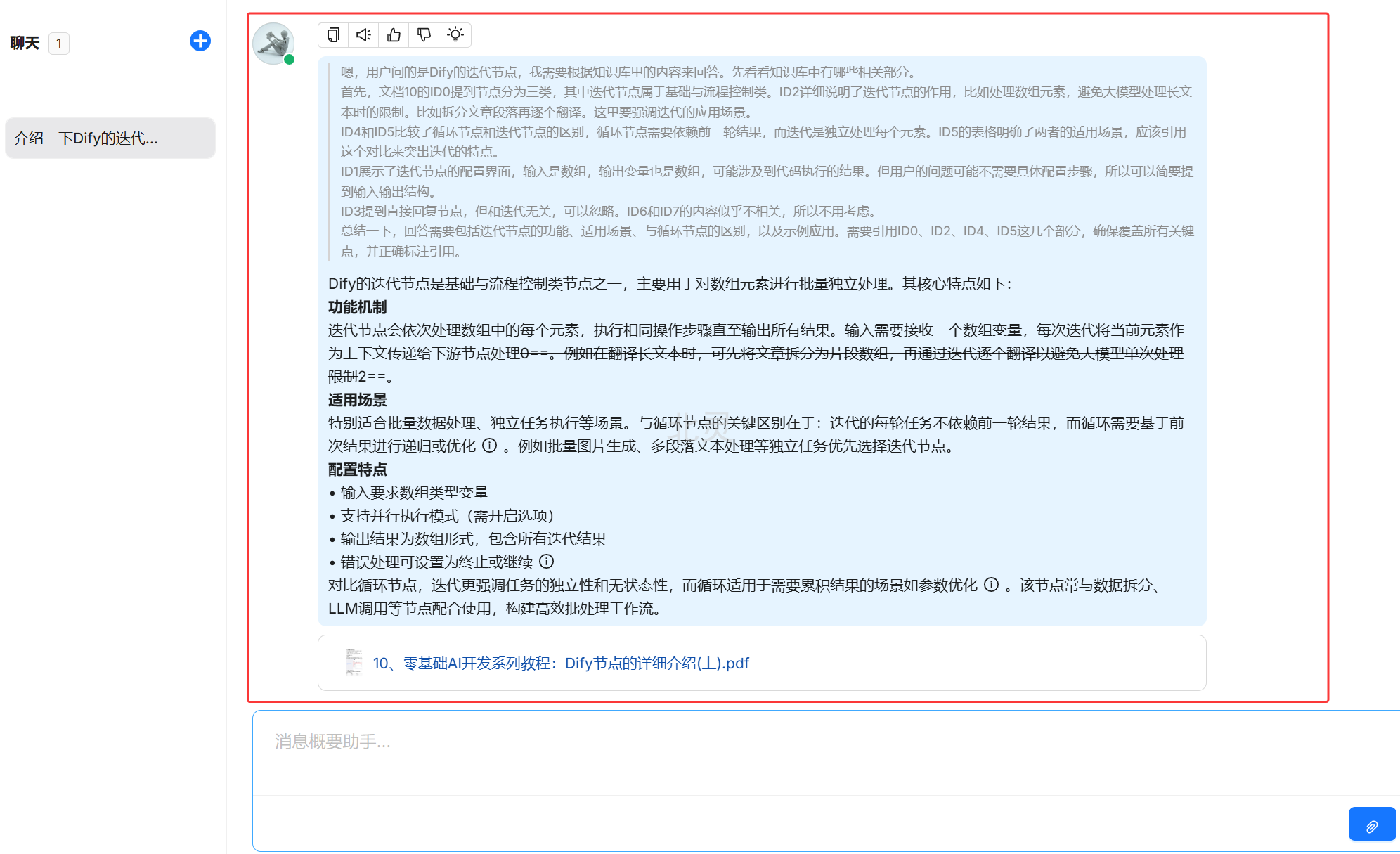
至此,RagFlow的部署就初步使用就介绍完了
🔥《零基础小白AI实战教程:手把手教你打造专属的智能体》🚀 系列教程更新中!
✅ 已更新:AI实践虚拟化平台安装
✅ 已更新:Docker Desktop 安装
✅ 已更新:Ollama安装教程
✅ 已更新:DeepSeek私有化部署
✅ 已更新:Dify私有化部署
✅ 已更新:Dify + DeepSeek搭建本地私有化知识库
✅ 已更新:Dify应用类型的选择
✅ 已更新:Dify升级指南
✅ 已更新:Dify节点的详细介绍(上)
✅ 已更新:Dify节点的详细介绍(中)
✅ 已更新:Dify节点的详细介绍(下)
✅ 已更新:RagFlow本地部署和使用
👉 搜索"北灵聊AI"获取最新更新,免费领取教程资料和源码


















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









