




莫比乌斯函数:
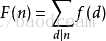
莫比乌斯两种反演:

d|n,表示n能够整除d,也就是d是n的所有因子
μ(x)是莫比乌斯函数,它是这样计算的:
(1).μ(1) = 1
(2).x = p1 * p2 * p3 ……*pk(x由k个不同的质数组成)则μ(x) = (-1)^k
(3).其他情况,μ (x) = 0
两条性质:(Φ(n)是欧拉函数)

求莫比乌斯函数值代码:
const int N = 1e6 + 5;
int mob[N], vis[N], prime[N];
int tot;//用来记录prime的个数
void Mobius(int n){ //求得莫比乌斯函数值
memset(prime,0,sizeof(prime));
memset(mob,0,sizeof(mob));
memset(vis,0,sizeof(vis));
tot = 0, mob[1] = 1;
for(int i = 2; i <=n; i ++){
if(!vis[i]){
prime[tot++] = i;
mob[i] = -1;
}
for(int j = 0; j < tot && i * prime[j] <=n ; j ++){
vis[i * prime[j]] = 1;
if(i % prime[j]) mob[i * prime[j]] = -mob[i];
else{
mob[i * prime[j]] = 0;
break;
}
}
}
}


















 3666
3666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









