







 本文深入探讨了C语言中结构体的边界对齐存储原则,通过实例分析32位和64位环境下不同类型数据在结构体中的排列方式,解释了为何存储顺序不同会导致结构体大小变化。并介绍了现代编译器采用的对齐策略,即根据结构体内最大数据类型的位宽进行对齐。此外,还展示了不同结构体可以在同一程序中采用不同对齐方式的现象,进一步揭示了这种策略对于存储效率的提升。
本文深入探讨了C语言中结构体的边界对齐存储原则,通过实例分析32位和64位环境下不同类型数据在结构体中的排列方式,解释了为何存储顺序不同会导致结构体大小变化。并介绍了现代编译器采用的对齐策略,即根据结构体内最大数据类型的位宽进行对齐。此外,还展示了不同结构体可以在同一程序中采用不同对齐方式的现象,进一步揭示了这种策略对于存储效率的提升。
前言:在计算机组成原理中,数据在存储器中以边界对齐存储的方式是很常用的。
教材参考:计算机组成原理(第2版) (唐朔飞著) P306
思考:下面来看两段代码(32位C语言环境),你能说出运行的结果吗?
// 代码段1
# include <stdio.h>
typedef struct test
{
char a;
char b;
short c;
int d;
}t;
int main(){
t *x;
printf("%d",sizeof(*x));
}
// 代码段2
#include <stdio.h>
typedef struct test
{
char a;
short b;
char c;
int d;
}t;
int main(){
t *x;
printf("%d",sizeof(*x));
}
答案:结果分别是:8 、12
可以看到,代码段的不同之处在于结构体第2、3个位置分别放的是char,short和short,char,存放顺序的不同为什么会导致结构体的大小不一样呢?这就是边界对齐存储在计算机中的应用。
32位计算机按字编址,1字应为4B。因此按照边界对齐存储规则:半字地址是2整数倍,字地址是4整数倍,双字地址是8整数倍。
相应地,64位计算机按字编址,1字应为8B。因此按照边界对齐存储规则:半字地址是4整数倍,字地址是8整数倍,双字地址是16整数倍。
以此类推。
下面来看下结构体构成:char (1B)、short(2B)、int(4B)。则32位下,半字地址(short)要为2整数倍,字地址(int)要为4整数倍。
① 按第一个代码段来存储,char->char->short->int
分别是1B ( a ) -> 1B ( b ) -> 2B ( c ) -> 4B ( d ):
| 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|
| a | b | c | c |
| 0x04 | 0x05 | 0x06 | 0x07 |
| d | d | d | d |
刚好存满,不需要边界对齐,占用8个存储单元。
② 按第二个代码段来存储,char->short->char->int
分别是1B ( a ) -> 2B ( b ) -> 1B ( c ) -> 4B ( d ):
| 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|
| a | - | b | b |
| 0x04 | 0x05 | 0x06 | 0x07 |
| c | - | - | - |
| 0x08 | 0x09 | 0x0a | 0x0b |
| d | d | d | d |
可以看到,由于半字地址(short)在0x01不是2的整数倍,往后移进行对齐;由于字地址(int)在0x05不是4的整数倍,往后移进行对齐,所以占用了12个存储单元。
下面再来看一段代码。
// 代码段3
#include <stdio.h>
typedef struct test
{
char a;
short b;
int d;
char c;
}t;
int main(){
t *x;
printf("%d",sizeof(*x));
}
输出结果:12
对应的存储结构 char->short->int->char
1B ( a ) -> 2B ( b ) -> 4B ( c ) -> 1B ( d ):
| 0x00 | 0x01 | 0x02 | 0x03 |
|---|---|---|---|
| a | - | b | b |
| 0x04 | 0x05 | 0x06 | 0x07 |
| c | c | c | c |
| 0x08 | 0x09 | 0x0a | 0x0b |
| d | - | - | - |
这个结果可以说明,结构体整体长度是字(32位下1字为4B)的整数倍,尽管0x09-0x0b没有存储内容,但会填写空白进行补齐。
到这里,相信你已经理解了边界对齐的方式,下面来看看拓展的内容。
提示:以下内容是在真实的x64计算机中测试,结论并不适用于考研或其他应试类题目
实际上,无论使用x86(32位)还是x64(64位)的C编译器,默认采用下面的这种对齐方式。
结构体里面有64bit的类型那么就使用8字节对齐方式,如果最大的是32bit类型就使用4字节对齐方式,以此类推。而且当struct里面包含struct或者union的时候,被包含的struct或者union的最大基础类长度会传递给上层的struct。
验证一:边界对齐的位数 等于 结构体内字长最大数据类型的位数:
① 下列结构体最长是short,按2B(16位)对齐。
#include <stdio.h>
typedef struct test
{
short a; // 2B
short b; // 2B
short c; // 2B
}t;
int main() {
t *x;
printf("%d", sizeof(*x));
}
上述代码在x86环境运行,输出结果是6(理论上按16位是6,按32位是8),说明这个结构体按16位进行边界对齐。
② 下列结构体最长是int,按4B(32位)对齐。
#include <stdio.h>
typedef struct test
{
int a; // 4B
char b; // 1B
int c; // 4B
}t;
int main() {
t *x;
printf("%d", sizeof(*x));
}
上述代码在x86和x64环境运行,输出结果都是12(理论上按32位是12,按64位是16),说明这个结构体按32位进行边界对齐。
③ 下列结构体最长是double,按8B(64位)对齐。
#include <stdio.h>
typedef struct test
{
double a; // 8B
char b; // 1B
}t;
int main() {
t *x;
printf("%d", sizeof(*x));
}
上述代码在x86和x64环境运行,输出结果都是16(理论上按32位是12,按64位是16),说明这个结构体按64位进行边界对齐。
这可能是为了更高效的利用存储空间而采用的一种折中办法(字是变长的)。在计算机组成原理的很多设计方法中都有体现,例如Cache中的组相联映射便是直接映射和全相联映射的一种折中。
验证二:同一个C程序中,不同结构体可以按不同位长进行边界对齐:
#include <stdio.h>
typedef struct test1 // 32:20 64:24
{
double a;
char b;
int c;
char d;
}t1;
typedef struct test2 // 32:12 64:16
{
int a;
int b;
int c;
}t2;
int main() {
t1 *x;
t2 *y;
printf("%d\n", sizeof(*x));
printf("%d", sizeof(*y));
}
上面的注释标明了按32和64位进行对齐理论应该得到的数据,而结果是24和12,说明分别是按64位和32位对齐。
下面补充32位机和64位机的数据字长:
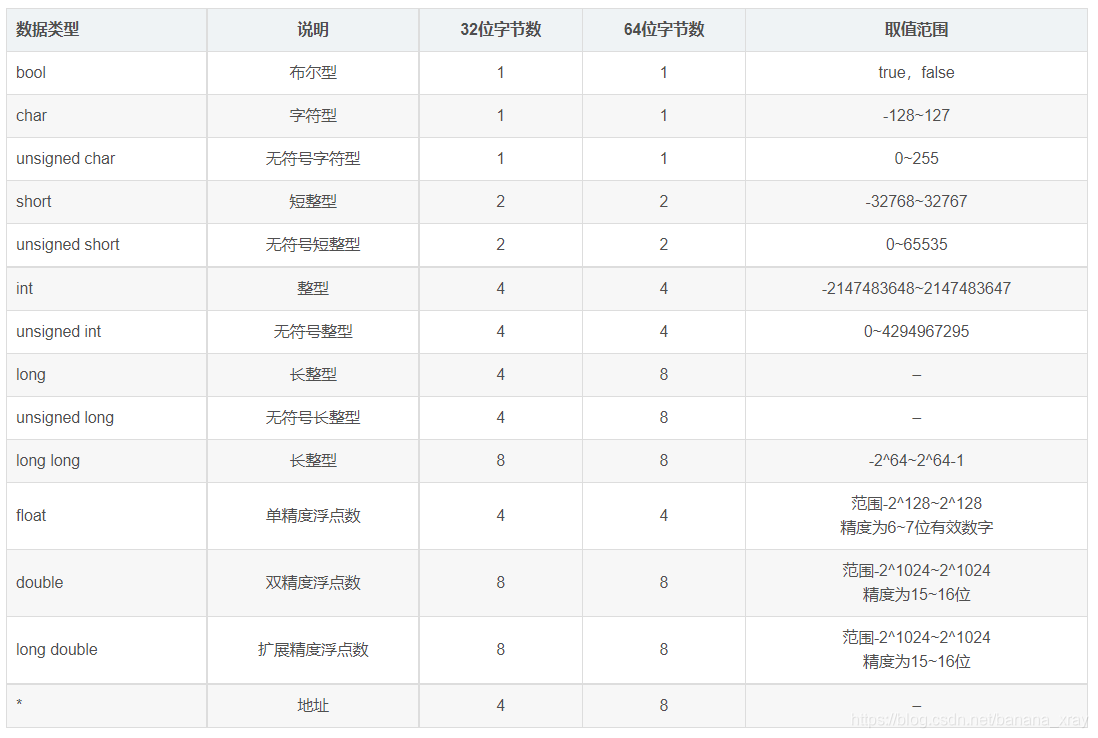
那么我们最终可以得出结论:我们现在所用的64位计算机当然是64位的,只不过为了提高效率,在某些程序片段中会以32位的特性运行。当然,如果你只是为了学习理论,只需要掌握理论的情况即可,不必对现实过多考虑。
最后,感谢你能看到这里,祝大家学业有成,成功上岸。
作者个人博客:515code.com
写于 2021/08/24 凌晨



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









