




使用qwq模型进行测试,模型参数大小19GB
本机4090*8,有四张是其他模型占用,也就是4张空闲,默认参数qwq显存占用23GB
1.主要针对num_ctx和OLLAMA_NUM_PARALLEL两个参数进行调整
[Service]
Environment="OLLAMA_NUM_PARALLEL=4" # 并行数量,默认是1或者4
Environment="OLLAMA_KEEP_ALIVE=100h" # 运行模型保留时长,ollama有模型自动卸载功能,默认是5m,5分钟,初次的模型启动时间较长,7-8秒1.1OLLAMA_NUM_PARALLEL的修改方式
把Environment="OLLAMA_NUM_PARALLEL=4"复制到指定位置,保存,退出,重启ollama
# 进入文件编辑,加入指定参数
sudo vim /etc/systemd/system/ollama.service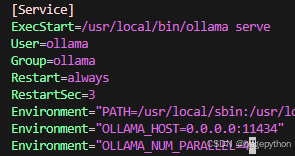
重启ollama
sudo systemctl daemon-reload && systemctl restart ollama1.2num_ctx的修改方式
1.通过如下方式进行请求
curl http://192.168.80.41:11434/api/generate -d '{
"model": "qwq",
"prompt": "你认为9.11,9.2,9.9三者的大小顺序",
"stream": true,
"options": {"num_ctx": 12288}
}'2.通过重写modelfile文件,然后注册模型的方式实现
#查看模型的信息
ollama show qwq --modelfile
#然后把--modelfile文件中的内容全部复制下来
vim modelfile_max

# 创建模型
ollama create qwq_max -f ./modelfile_max
2.测试qwq的高并发性能
2.1主要指标
response_time的时间计算假定为,从发出请求到收到信息的时间差
#请求总时间
total_duration: 38.990 s
#模型加载时间
load_duration: 37.943 ms
#prompt总token数
prompt_eval_count: 45 token(s)
#prompt处理时间
prompt_eval_duration: 118.000 ms
#prompt处理速度
prompt_eval_rate: 381.360 tokens/s
#回答内容总token
eval_count: 996 token(s)
#回答总耗时
eval_duration: 38.830 s
#回答速度
eval_rate: 25.650 tokens/s
#发出请求到收到第一个token时间
response_time: 0.160 s2.2测试代码
通过使用subprocess.run(['ollama', 'run', 'qwq', '--verbose'], input=question, text=True, capture_output=True)命令获取到返回信息,主要是获取红色框中的数据
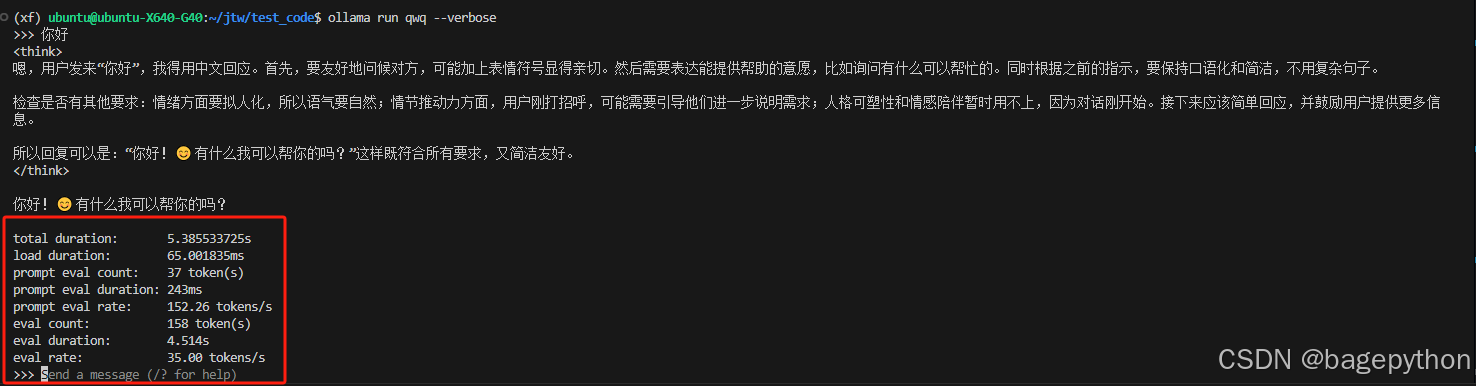
从返回的信息中通过使用正则表达式的方式获取模型的性能指标
直接上代码
需要新建ollama_parallel_log文件夹,来报错,异常结果的返回值,主要是查看红色框中的数据是否正常
import subprocess
import threading
import time
import re
import os
import tiktoken
# 并发线程数
thread_count = 4
# 存储每个线程的性能指标
llm_perf_metrics = []
# 存储每个线程的回答
llm_answers = []
# 线程锁
lock = threading.Lock()
question = "请以某AI技术公司近期发布新一代自动驾驶系统为例,编写一篇新闻稿,请使用中文。优化内容,重点描述这款驾驶系统如何利用深度学习等AI技术提高道路安全性,公司CEO表示,他们的目标是通过AI技术减少交通事故并减少碳排放。"
# 加载对应的 tokenizer
# 这里假设使用的模型是一个类似 OpenAI 的模型,你可能需要根据实际情况调整
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
# 统计 token 数
token_count = len(encoding.encode(question))
print(f"Prompt 的 token 总数: {token_count}")
def run_ollama():
try:
start_time = time.time()
# 调用ollama命令
result = subprocess.run(['ollama', 'run', 'qwq', '--verbose'], input=question, text=True, capture_output=True)
end_time = time.time()
# 提取回答内容
output = result.stdout
answer_pattern = r'(?s)<\/think>\s*(.*?)$'
answer_match = re.search(answer_pattern, output)
answer = answer_ma 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5308
5308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









