



官方连接https://github.com/kvcache-ai/ktransformers/blob/main/doc/zh/DeepseekR1_V3_tutorial_zh.md
来自官方的测试结果

llama启动DeepSeek-R1-Q4_K_M 4090*2 decode token: 3.73token/s 速度太慢下面就没再测
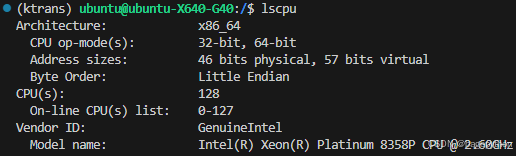
1.运行环境,理论最低需求
CPU: 32Core
内存: 382G
GPU: 14G
本次部署环境:
CPU: Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60GHz * 2 共128G
内存: 1T
GPU: 4090*1 24G
ktransformers 0.2.2rc2+cu121torch25fancy
注意:如果你的CPU是英特尔,第四代,包含了AMX指令集,推荐安装V0.3版本ktransformers
wget https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
pip install ./ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
python -m ktransformers.local_chat --model_path <your model path> --gguf_path <your gguf path> --prompt_file <your prompt txt file> --cpu_infer 65 --max_new_tokens 10002.模型下载
从modelscope下载
2.1下载权重文件
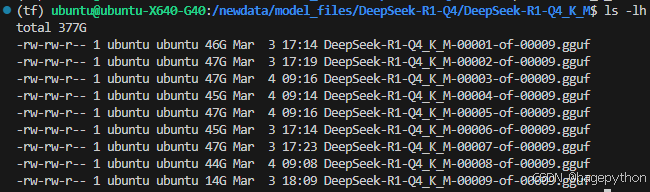
权重文件保存到/newdata/model_files/DeepSeek-R1-Q4
from modelscope import snapshot_download
# 下载权重文件
snapshot_download( repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "/newdata/model_files/DeepSeek-R1-Q4",
allow_patterns = ["*DeepSeek-R1-Q4_K_M-*"], #下载DeepSeek-R1-Q4_K_M-开头的文件
)2.2下载配置文件
配置文件保存到DeepSeek-R1-GGUF-parameter
from modelscope import snapshot_download
# 下载模型参数文件
snapshot_download(
repo_id="deepseek-ai/DeepSeek-R1",
local_dir="DeepSeek-R1-GGUF-parameter",
ignore_patterns=["*.safetensors"],#下载.safetensors之外的文件
)
3.安装ktransformers
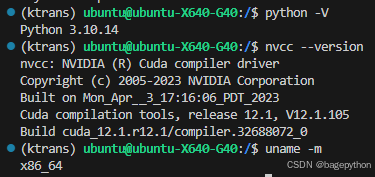
3.1前置依赖项
CUDA
LInux
Python
3.2ktransformers
git clone https://github.com/kvcache-ai/ktransformers --recursive
cd ktransformers
export USE_NUMA=1
bash install.sh4.启动服务
服务启动需要大概1分钟
ktransformers \
--model_name DeepSeek-R1-Q4_K_M \
--model_path /home/ubuntu/jtw/test_code/DeepSeek-R1-GGUF-parameter \
--gguf_path /newdata/model_files/DeepSeek-R1-Q4/DeepSeek-R1-Q4_K_M \
--host 0.0.0.0 \
--port 10002 \
--cpu_infer 65 \
--max_new_tokens 8192
--model_name 重命名
--cpu_infer 根据cpu核心数进行设置
或者通过命令 vim ~/.ktransformers/config.yaml 修改模型名字5.服务访问
5.1通过curl访问
DeepSeek-Coder-V2-Instruct是配置文件默认模型名字
curl -X POST "http://localhost:10002/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{ "model": "DeepSeek-Coder-V2-Instruct", "messages": [ { "role": "user", "content": "你是谁?" } ], "temperature": 0.7, "max_tokens": 512}'5.2通过openai访问
import openai
import time
from transformers import AutoTokenizer
client = openai.Client(
api_key="not can null",
base_url="http://192.168.80.41:10002/v1"
)
# /v1/chat/completions
def stream_chat_response(client, model, messages):
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True
)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content_chunk = chunk.choices[0].delta.content
full_content += content_chunk
print(content_chunk, end="", flush=True)
return full_content
'''
question:
1,"How many ‘r’s are in the word ‘strawberry’?(单词 “strawberry” 中有多少个字母 “r”?)"
2,"9.8 和 9.11 哪个更大?"
3,"李白的风格写一首七言绝句"
'''
# Round 1
messages = [{"role": "user", "content": "李白的风格写一首七言绝句"}]
print(f"用户提问 Round 1: {messages[0]['content']}")
print("模型回复:")
# 确保 model 名称和服务器端一致
content = stream_chat_response(client, "DeepSeek-R1-Q4_K_M", messages)
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









