



【NVIDIA NIM黑客松训练营】RAG智能对话机器人——标准智能审核助手
1. 项目背景与意义
在现代社会的高速发展中,不同行业制定了各自独特的标准与规范,这些标准既是合规的保障,也是提升项目质量的重要基础。在企业制定设计方案时,确保方案内容严格符合相关标准是一项关键任务。然而,人工核对标准与方案内容的方式不仅耗时费力,还容易出现遗漏,导致项目进程受阻甚至产生合规风险。
为了解决这一问题,本项目基于NVIDIA AI-AGENT暑期线上训练营的技术积累,研发了一款基于RAG(检索增强生成)的智能对话机器人。该机器人能够自动完成标准文档与设计方案内容的比对工作,快速定位两者间的差异,并即时向用户反馈不一致的内容。这一工具帮助用户高效完成修改,极大节省了时间成本,同时显著提高了工作效率和方案的合规性。
2. 项目亮点
1)自动化比对
借助先进的智能算法,系统实现了标准与设计方案内容的全自动比对,减少了人工操作,提升了效率。
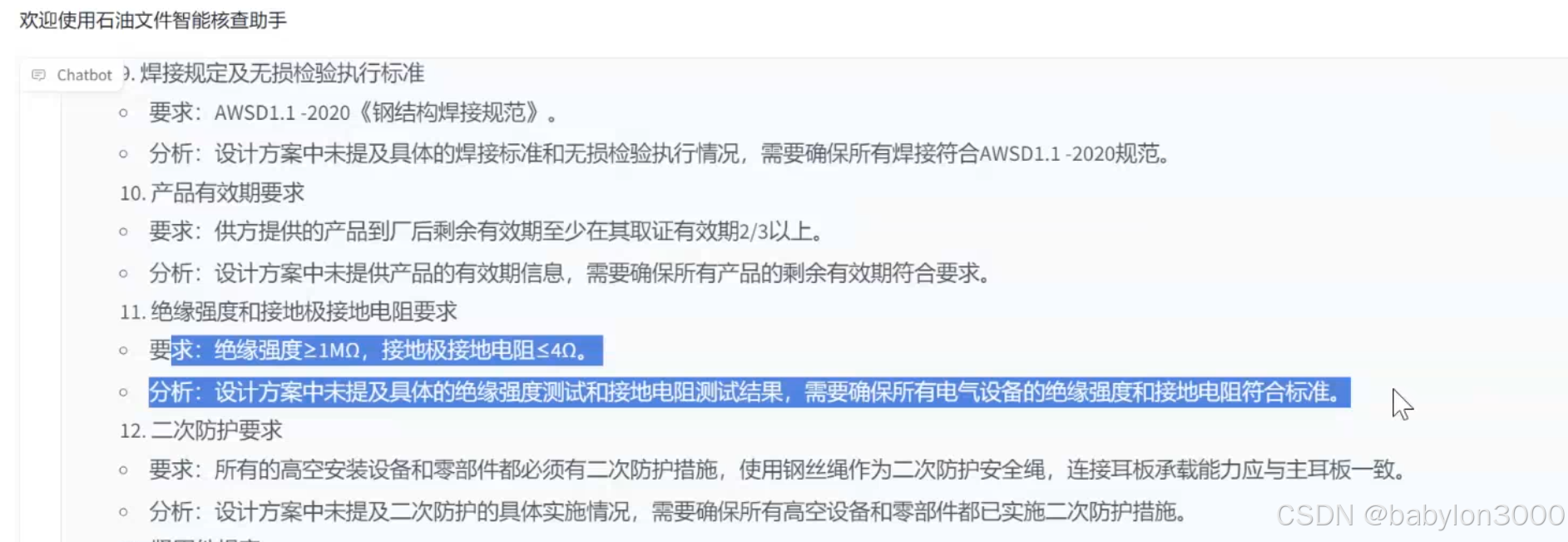
2)精准差异识别
系统能够准确定位方案中与标准不符的内容,为用户提供详细的差异分析,确保方案的全面合规。

3)即时反馈
用户可即时获得比对结果,无需等待,便于快速调整与优化设计方案。
4)多领域适用
系统支持根据行业需求定制,适用于多个领域的标准与规范处理,满足广泛的应用场景。
3. 技术方案与实施步骤
模型选择
1)大模型:ChatNVIDIA(model="01-ai/yi-large")
选择理由:Yi-Large作为01.AI系列的旗舰模型,具备卓越的代码生成、逻辑分析和数学推理能力,尤其在多语言处理上表现优异。其强大的综合性能和广泛的语言支持,使其成为处理多行业、多语言标准文档的理想选择。
2)RAG向量化模型:nvidia/nv-embed-v1
选择理由:NV-Embed模型在检索、分类、语义相似性任务中表现突出。其创新的潜在向量池化与两阶段指令调优设计,显著提升了模型在复杂语义任务中的准确性和效率,完美契合本项目的需求。
4. 数据构建过程
1)数据加载与预处理
使用文档加载工具(如PyPDFLoader、Docx2txtLoader)处理多种文档格式(如.pdf、.docx)。加载的文档内容通过递归字符分割器进行分段处理,确保文本块大小适合向量化。
2)向量化存储
将处理后的文本分块通过NV-Embed嵌入模型转化为高维语义向量,并存储于FAISS数据库中。这一过程确保了数据的高效检索与精确比对。
3)优势
向量化处理超越了传统的关键词匹配,通过语义相似度检索实现精准定位,即便在复杂文本中也能找到相关内容,从而提高审核的全面性和准确性。
5. 功能整合
1)标准文档加载与向量化存储
支持多种格式的标准文档处理,向量化后存储于FAISS数据库中,方便后续快速检索。
2)设计方案的自动化审核
系统将设计方案分解为内容块,并与标准文档的向量化数据进行语义检索,比对差异并生成详细审核报告。
3)智能对话助手
通过Gradio界面,用户可以上传标准文档与设计方案,系统自动完成审核并生成反馈,提供优化建议,帮助用户高效完善方案内容。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









