







师从江北
问题的提出
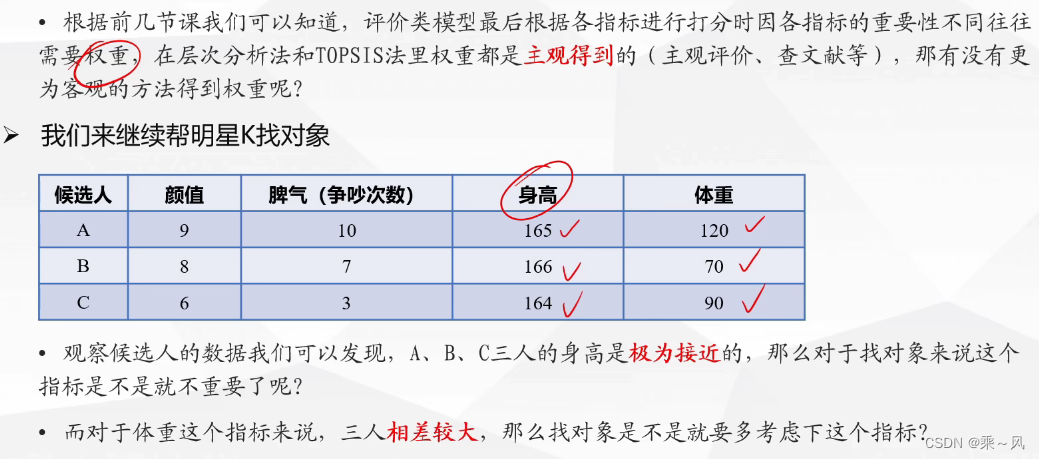
基本概念和步骤

原始矩阵正向化
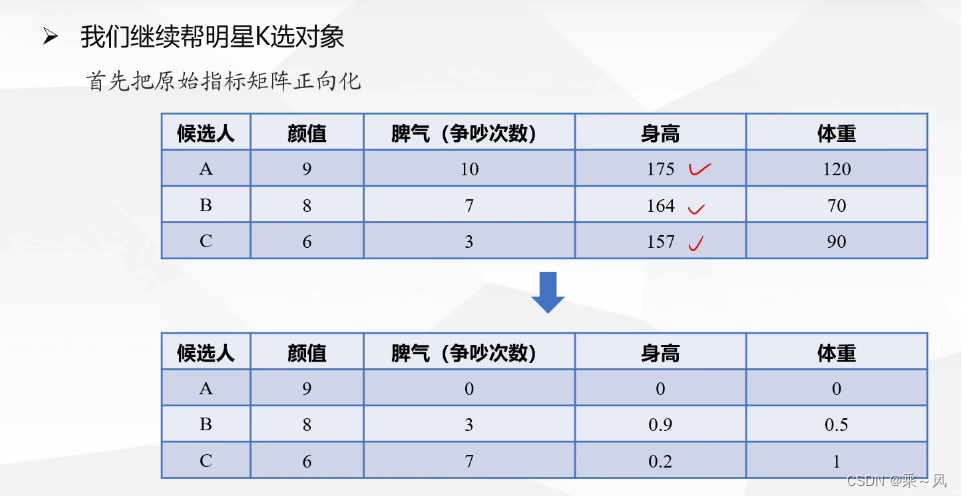
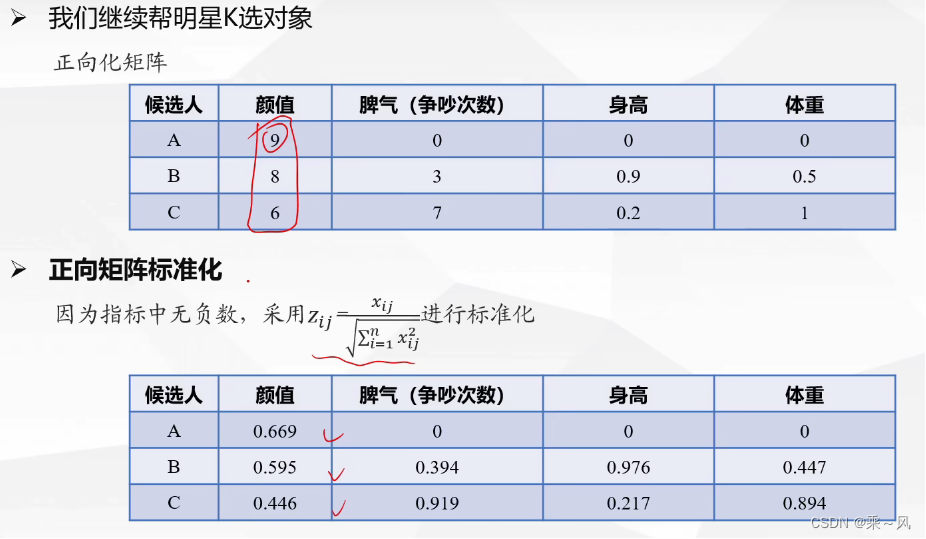
正向矩阵标准化
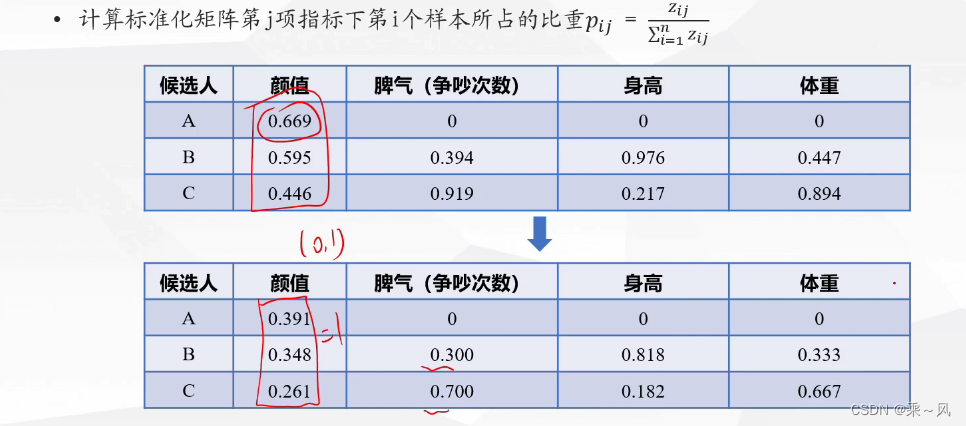
计算概率矩阵P
计算熵权

总结
矩阵正向化->正向矩阵标准化->计算概率矩阵->计算熵权
代码实现
import numpy as np
#自定义一个对数函数mylog,用于处理输入数组中的零元素
def mylog(p):
n=len(p) #获取输入向量P的长度
lnp=np.zeros(n) #创建一个长度为n,元素都为0的新数组lnp
for i in range(n): #对向量P的每一个元素进行循环
if p[i]==0:
lnp[i]=0 #则在lnp中对应的位置也设置为0,因为log(0)是未定义的,这里我们规定为0
else:
lnp[i]=np.log(p[i]) #如果p[i]不为0,则计算其自然对数并赋值给lnp的对应位置
return lnp #返回计算后的对数数组
#定义一个指标矩阵
X=np.array([[9,0,0,0],[8,3,0.9,0.5],[6,7,0.2,1]])
#对矩阵X进行标准化处理,得到标准化矩阵Z
Z=X/np.sqrt(np.sum(X*X,axis=0))
print("标准化矩阵Z= ")
print(Z) #打印标准化矩阵Z
#计算熵权所需变量和矩阵初始化
n,m=Z.shape #获取标准化矩阵Z的行数和列数
D=np.zeros(m) #初始化一个长度为m的数组D,用于保存每个指标的信息效用值
#计算每个指标的信息效用值
for i in range(m): #遍历Z的每一列
x=Z[:,i] #获取Z的第i列,即第i个指标的所有数据
p=x/np.sum(x) #对第i个指标的数据进行归一化处理,得到概率分布p
#使用自定义的mylog函数计算p的对数,需要注意的是,如果p中含有0,直接使用np.log会得到-inf,这里使用自定义函数避免这个问题
e=-np.sum(p*mylog(p))/np.log(n) #根据熵的定义计算第i个指标的信息熵e
D[i]=1-e #根据信息效用值的定义计算D[i]
#根据信息效用值计算各指标的权重
W=D/np.sum(D) #将信息效用值D归一化,得到各指标的权重W
print("权重 W =")
print(W) #打印得到的权重数组W若有侵权,请联系作者



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











