







 超级会员免费看
超级会员免费看
🔔 NVIDIA之CUDA 相关技术、疑难杂症文章合集(掌握后可自封大侠 ⓿_⓿)(记得收藏,持续更新中…)
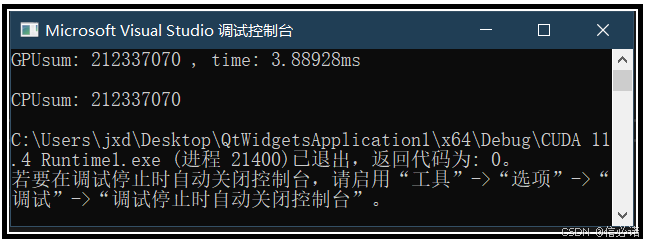
运行耗时比较
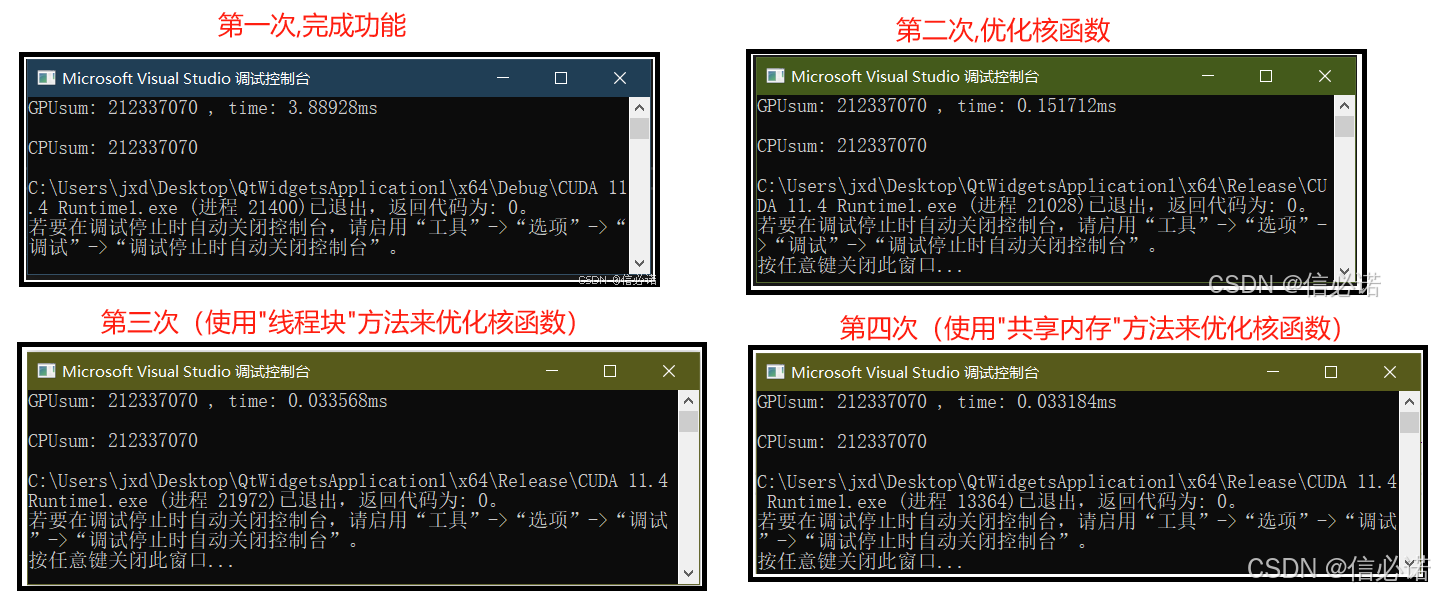
第一次(完成功能)
运行结果
完整代码
/* 利用CUDA计算1M大小数据的立方和 */
#include
运行结果
完整代码
/* 利用CUDA计算1M大小数据的立方和 */
#include  1282
2462
1282
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























