




5.1. 树的概念
5.1.1. 树的基本定义
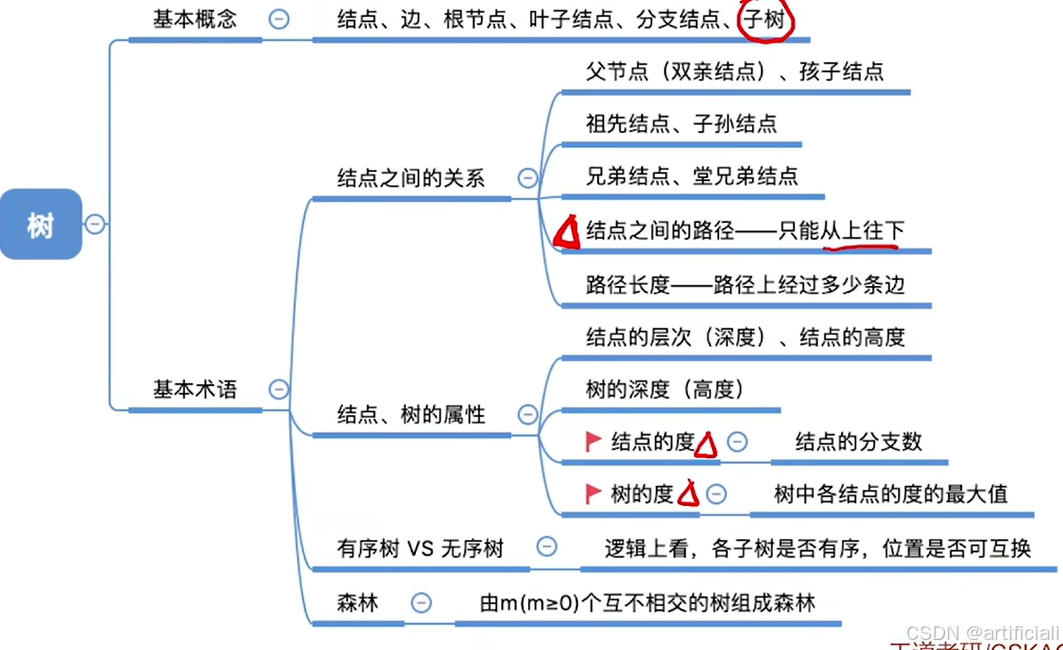
树:n(n>=0)个节点的有限集合,是一种逻辑结构,当n=0时为空树,
且非空树满足:
- 有且仅有一个特定的称为根的节点.
- 当n>1时,其余结点可分为m (m >0) 个互不相交的有限集合,其中每个集合本身又是一棵树,并且称为根结点的子树。
树是一种递归的数据结构
非空树特点:
- 有且仅有一个根节点
- 没有后继的结点称为“叶子结点”(或终端节点)
- 有后继的结点称为“分支结点” (或非终端结点),度不为0的结点
- 除了根节点外,任何一个结点都有且仅有一个前驱
- 每个结点可以有0个或多个后继
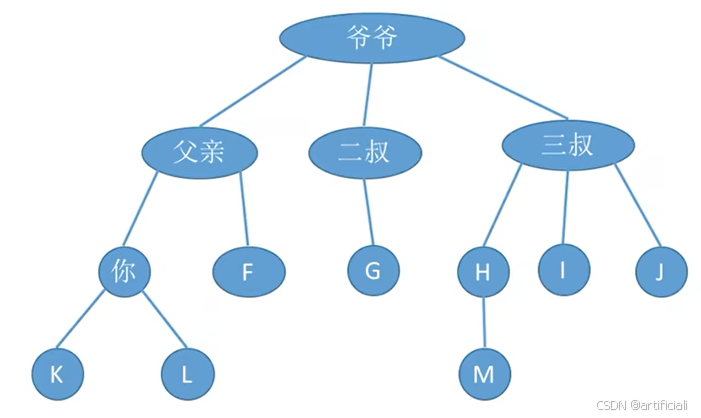
- 祖先结点:自己的之上都是祖先节点。
- 子孙结点:自己的之下都是子孙节点。
- 双亲结点 (父节点) :和自己相连的上一个就是父节点。
- 孩子结点:和自己相连的下面一个。
- 兄弟结点:我自己同一个父节点的。
- 堂兄弟结点:同一层的节点。
属性:
- 结点的层次(深度)-从上往下数
- 结点的高度一从下往上数
- 树的高度 (深度)一总共多少层
- 结点的度--有几个孩子(分支,用边理解)。父亲2,二叔1,三叔3
- 树的度一各结点的度的最大值
- 路径长度:经过边个数
- 路径:两个节点经过的节点序列
有序树和无序树
- 有序树--逻辑上看,树中结点的各子树从左至右是有次序的,不能互换
- 无序树--逻辑上看,树中结点的各子树从左至右是无次序的,可以互换
森林:是m(>=0)棵互不相交的树的集合。
25节点,15边几个树?

5.1.2. 树的常考性质
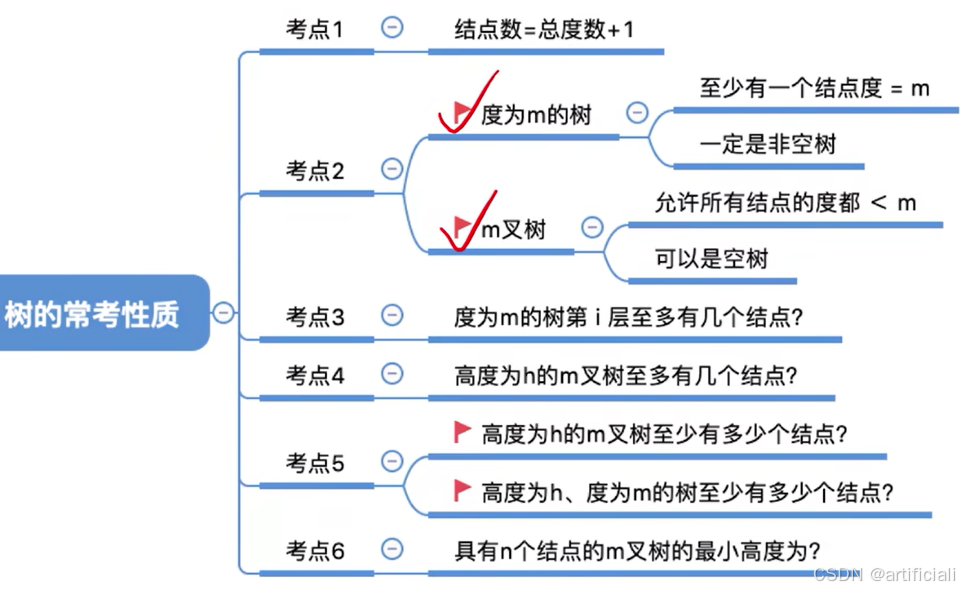
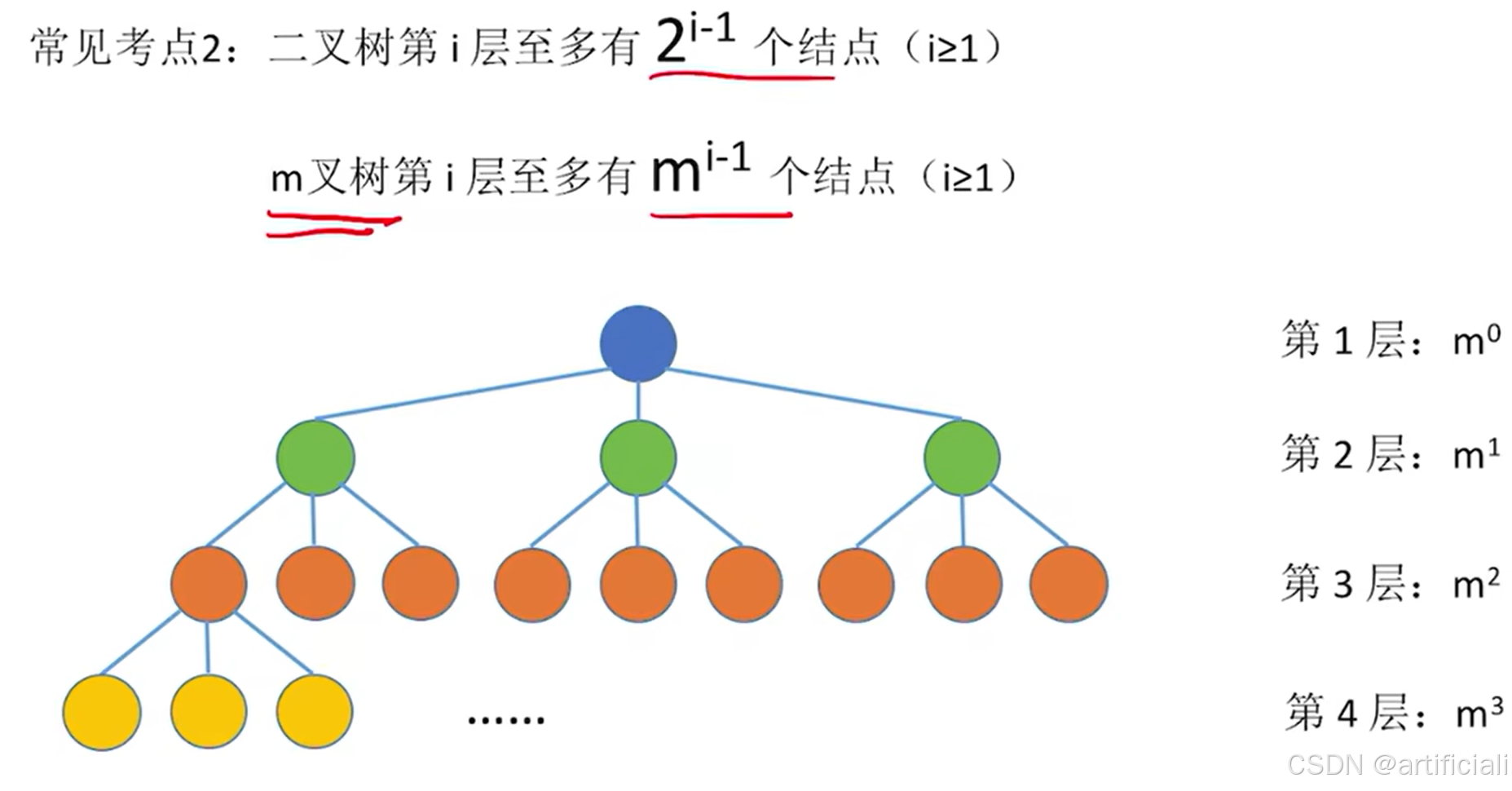
常见考点1: 树中的结点数=总度数+1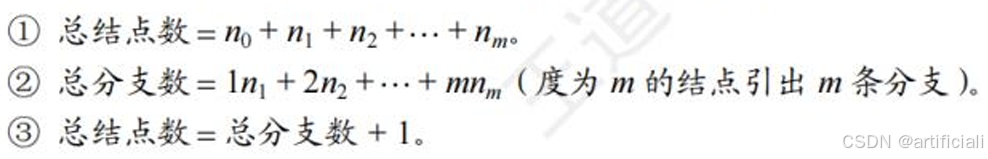
常见考点2:度为m的树、m叉树的区别:
- 树的度--各结点的度的最大值;
- m叉树--每个结点最多只能有m个孩子的树
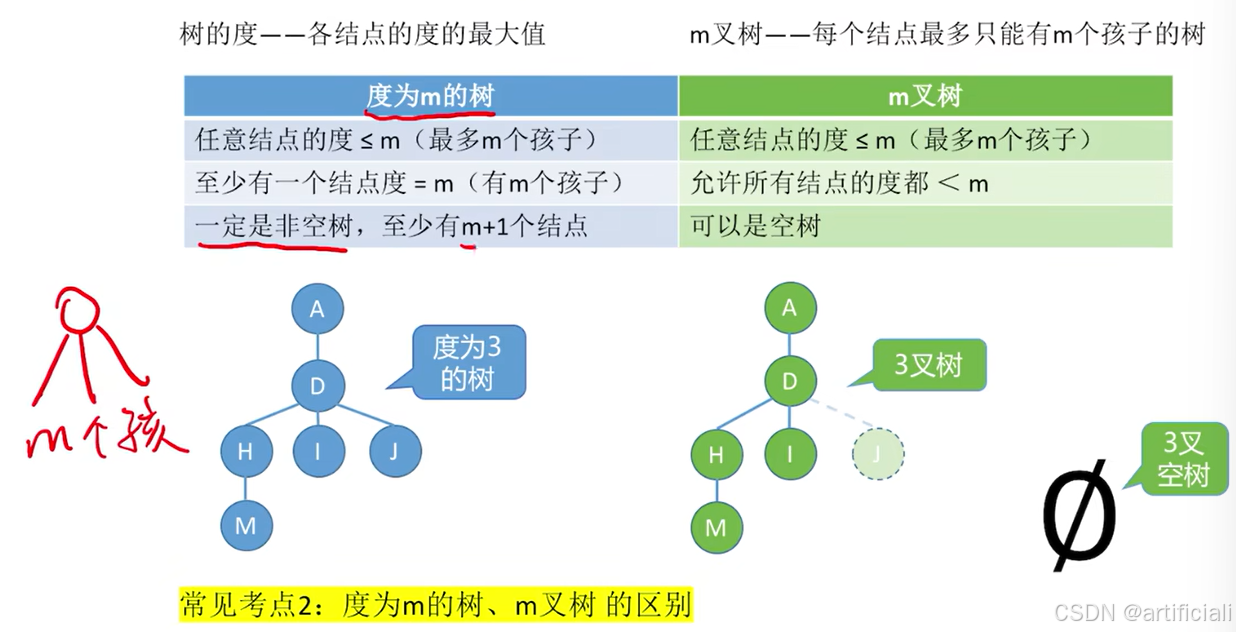

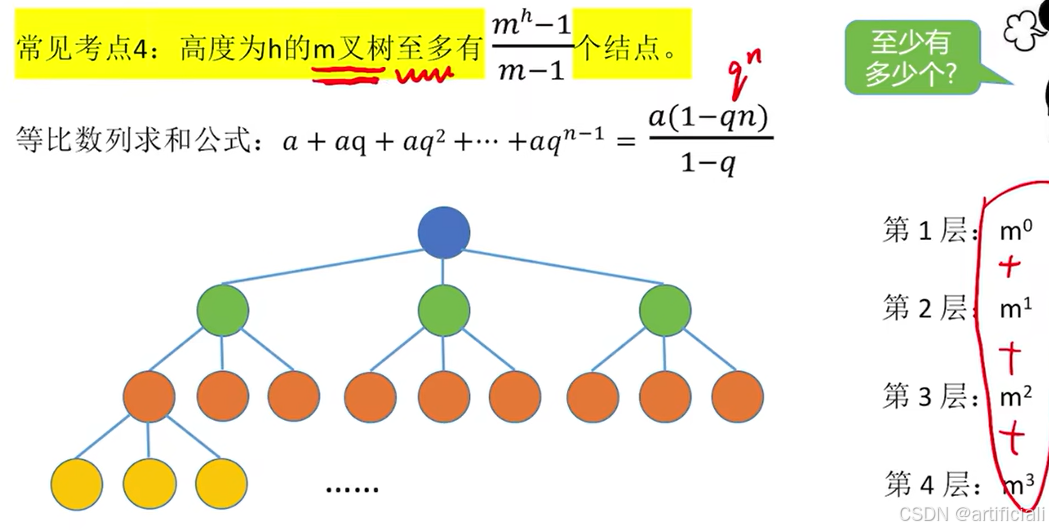
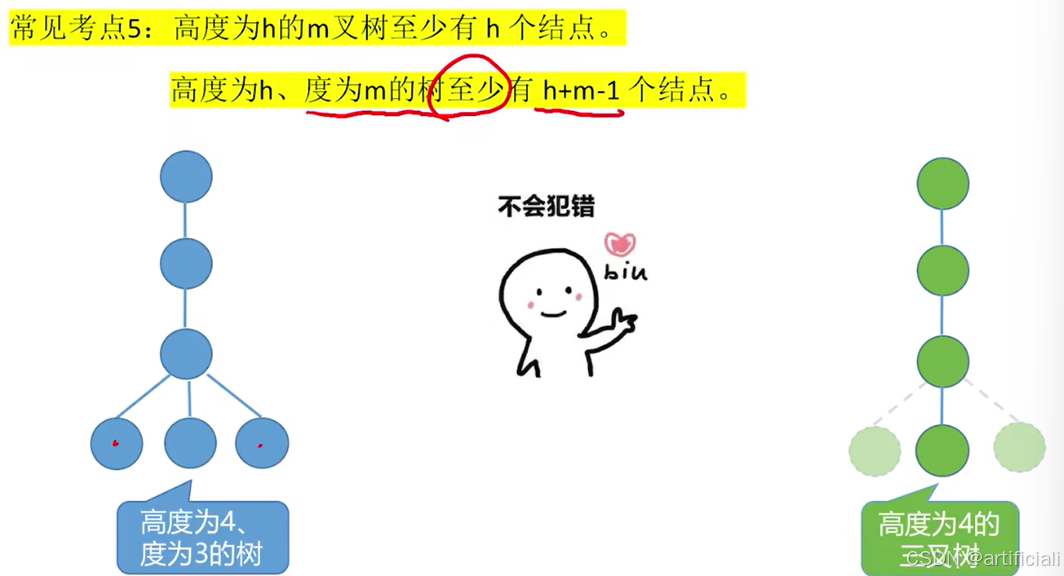
解释:就是只有一层是m个,其他层是1个,方可达到最高层。

具有n个结点的m叉树的最大高度为:n
二叉树(m=2),n=6
1
1 1
1 1 1
h-1<log2(6*(1)+1)=2... <=h
5.2. 二叉树
5.2.1. 二叉树的定义
二叉树是n (n>=0)个结点的有限集合:
- 或者为空二叉树,即n =0。
- 或者由一个根结点和两个互不相交的被称为根的左子树和右子树组成。左子树和右子树又分别是一棵二叉树。
特点:
- 每个结点至多只有两棵子树
- 左右子树不能颠倒 (二叉树是有序树)
- 二叉树可以是空集合,根可以有空的左子树和空的右子树
5.2.2. 特殊二叉树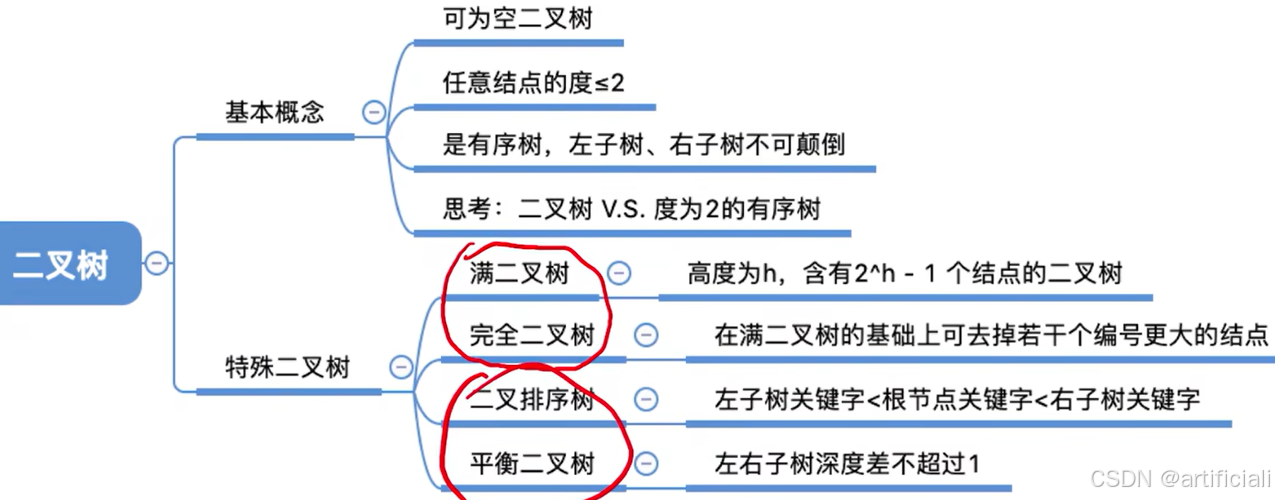
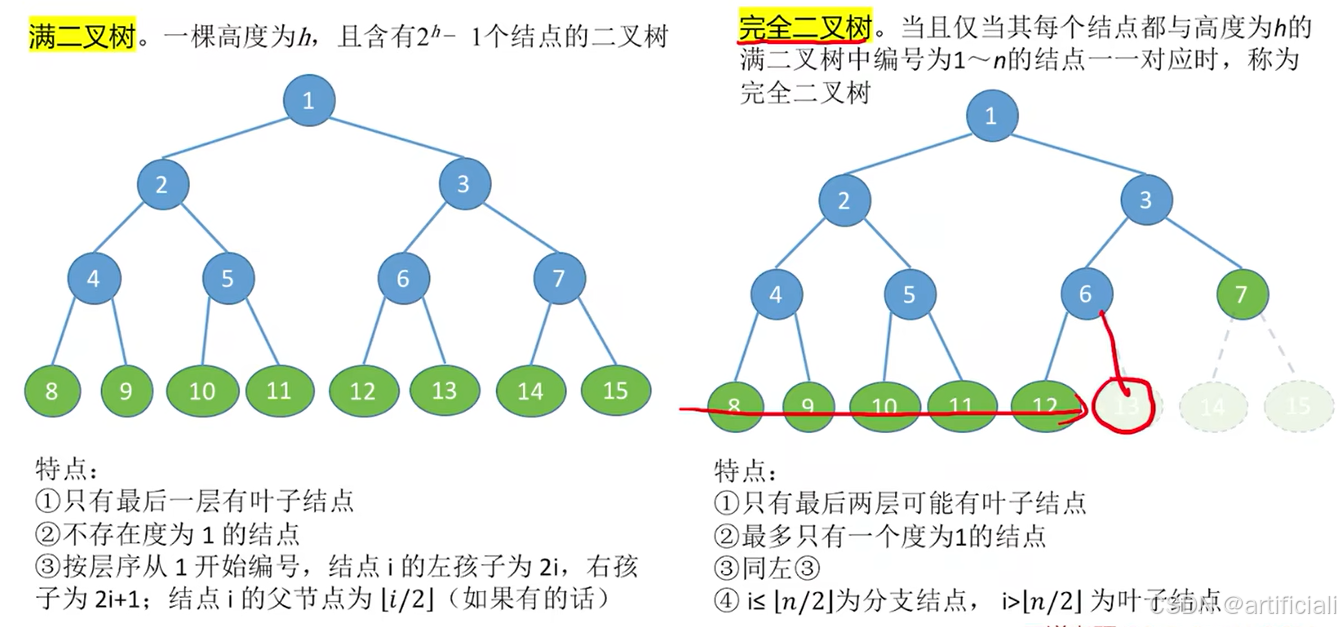
③ 按层序从 1~n 开始编号,结点 i 的左孩子为 2i,右孩子为 2i+1,结点 i 的父结点为 i/2 下取整(如果有的话)
① 只有最后两层可能有叶子结点 ② 最多只有一个度为 1 的结点 ③ 满足以下条件:k ≤ n/2下取整为父结点;i >n/2下取整为叶子结点
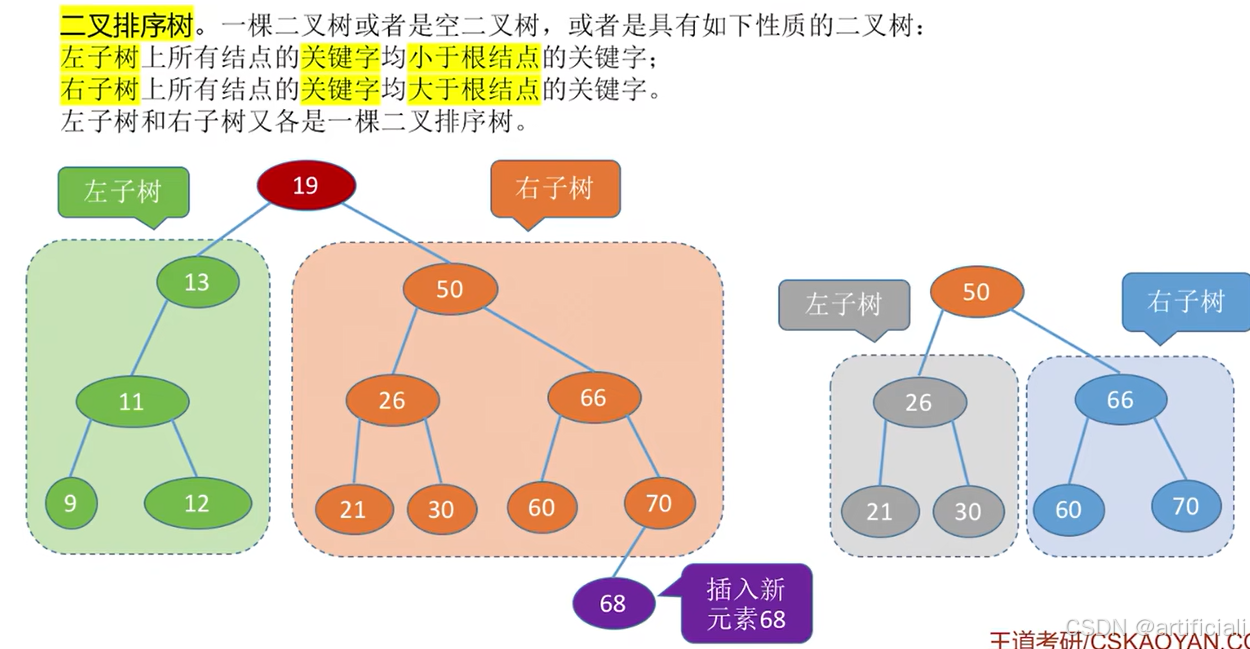
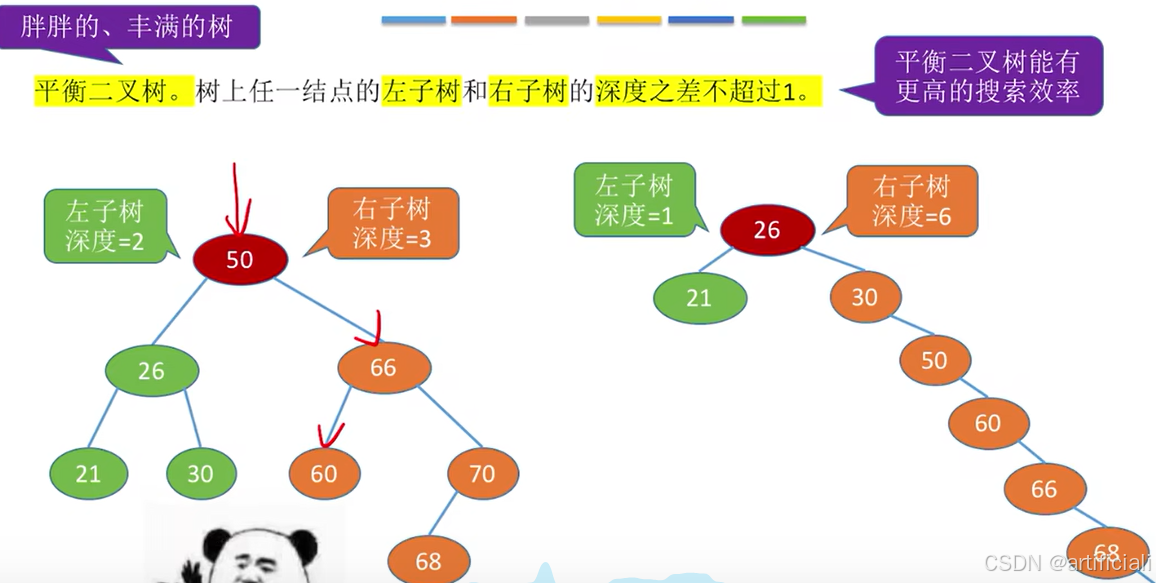
5.2.3. 二叉树的性质
叶子节点的索引范围是从 [floor(n/2)+1,n]

n0=n2+1
n0是叶子结点(度为0)、 n1 是度为1的结点数。
结点总数: n=n0+n1+n2
树中的结点数=总度数+1可知:(边数公式)
总度数为 n1+2n2(度为1的结点贡献1,度为2的结点贡献2个):n=(n1+2*n2)+1
将两式相减:(n1+2n2+1)−(n0+n1+n2)=0
化简得:n2+1−n0=0⇒n0=n2+1
层节点数
h->节点个数

完全二叉树
完全二叉树是一种特殊的二叉树,其节点按从上到下、从左到右的顺序依次编号1, 2, ..., n。以下是对其相关性质的详细解释:
性质①
-
含义:若节点i的编号小于等于n/2的下取整,则该节点是分支节点(即有至少一个孩子),否则为叶节点。最后一个分支节点的编号是n/2的下取整。
-
原因:在完全二叉树中,叶节点只能出现在最后两层。对于编号大于n/2的节点,它们不可能有孩子节点,因为孩子节点的编号会超过n。
性质②-易错点
-
含义:叶节点只可能出现在层次最大的两层上。如果删除满二叉树中最底层最右边的连续两个或以上叶节点,倒数第二层会出现叶节点。易错:完全二叉树,节点个数大的层有8个节点,最多有几个节点?23个=15+8
-
原因:完全二叉树的结构决定了叶节点集中在底层,删除部分叶节点会影响上一层的节点性质。
性质③
-
含义:若有度为1的节点(即只有一个孩子),则只能有一个,且该节点只有左孩子,无右孩子。这个度为1的节点只能是最后一个分支节点,编号为n/2的下取整。
-
原因:完全二叉树的结构要求节点从左到右依次排列,因此如果存在度为1的节点,它只能是最右边的分支节点,且只能有左孩子。
性质④
-
含义:按层序编号后,一旦出现某节点i为叶节点或只有左孩子的情况,则编号大于i的节点均为叶节点。
-
原因:完全二叉树的节点排列顺序决定了后面的节点不可能再有孩子。
性质⑤
-
含义:若n为奇数,每个分支节点都有左右孩子;若n为偶数,编号最大的分支节点(n/2)只有左孩子,其余分支节点都有左右孩子。
-
原因:奇偶性影响最后一个分支节点是否有右孩子。
性质⑥
-
含义:当i>1时,节点i的父节点编号为i/2的下取整。
-
原因:父节点的编号是子节点编号的一半。
性质⑦
-
含义:若节点i有左右孩子,则左孩子编号为2i,右孩子编号为2i+1。
-
原因:完全二叉树的编号规则决定的。
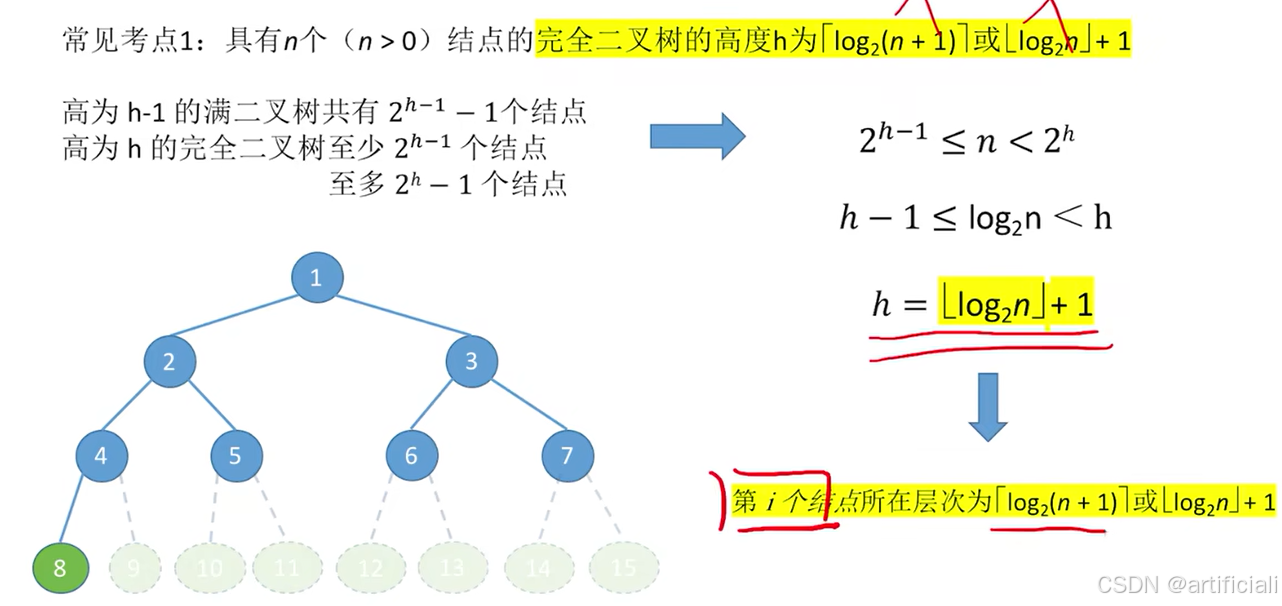
节点个数->h
- 情况1:在h层有多个节点的情况,和树一样
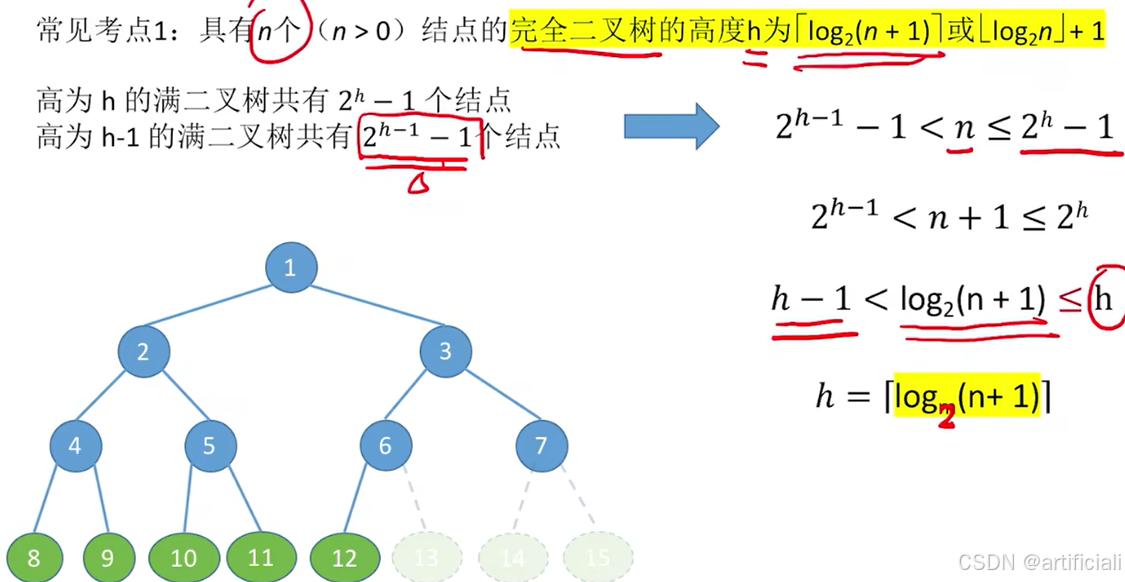
- 情况2:第h层节点个数范围,
等价于图片式子。
求n0、n1、n2
完全二叉树中,度为1的结点最多只有1个(即 n1=0或 n=1)补充:如果是满二叉树这个n1=0
由于n0=n2+1带入 n0+n2——> ![]() 必为奇数
必为奇数
结点总数为偶数的情况:若完全二叉树有2k个结点,则必有n₁=1,n₀=k,n₂=k-1。证明:

结点总数为奇数的情况:若完全二叉树有2k-1个结点,则必有n₁=0,n₀=k,n₂=k-1。证明:

5.2.4. 二叉树存储实现
二叉树的顺序存储:二叉树的顺序存储中,一定要把二叉树的结点编号与完全二叉树对应起来;

叶子节点是没有孩子的节点。在完全二叉树中,<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1488
1488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









