



前言
RAG 全称 Retrieval-Augmented Generation,翻译成中文是检索增强生成。这一年多,在大模型应用领域,RAG频繁地出现。为什么它这么热?需要怎么理解看待RAG?
1、为什么需要RAG
虽然大模型有丰富的知识和理解生成能力,但它的信息量并不够,比如企业的私域信息,它并不知道,有些最新的信息出现在训练完成之后,它也不掌握。如果要针对这些信息提问,就需要把相关的信息也一并交给它,让它结合内容回答。有点命题作文的意思。
前排提示,文末有大模型AGI-优快云独家资料包哦!
这里边有些场景比较简单,比如针对论文,可以把问题和论文一起送给大模型,然后大模型根据论文的内容,把问题的答案输出出来,比较完整。
但实际上,私域的信息量非常大,远超过一次能够提交给模型的内容,这时候,就需要一种技术,把跟问题相关的内容准确的提取出来,送给模型。可以说,内容提取的质量,直接决定大模型的回答质量。
2、向量搜索
向量搜索(Vector Search)也叫矢量搜索。它是用机器学习的方法来捕获非结构化数据(包括文本和图像)的含义和上下文,并将其转换为数字化表示形式。向量搜索常用于语义搜索,通过利用相似最近邻 (ANN) 算法来找到相似数据。与传统的关键字搜索相比,向量搜索产生的结果相关度更高,执行速度也更快。
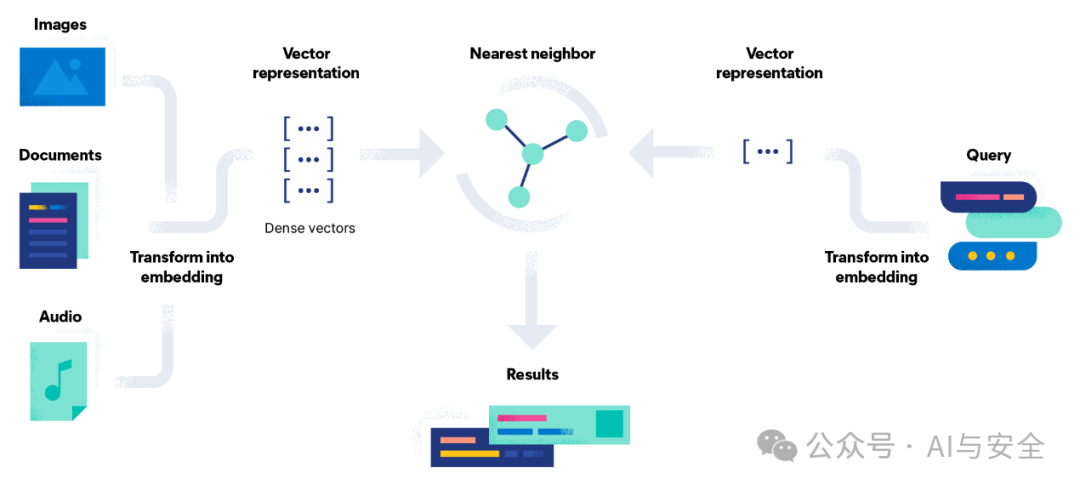
简单地说,向量搜索有两个关键动作,一个是向量化,就是把一段文本,或图形音频等,通过某种编码格式,变成一个矩阵,这个编码动作,叫Embedding(嵌入)。第二个是搜索,一般用相似最近邻(ANN)算法,来找到距离最近的结果。这个距离最近的结果,就是含义最相近的结果。向量搜索也叫语义搜索。
以上动作,理解过程并记住名字就可以了。为什么距离最近含义就相似,让数学家和算法专家去搞吧,一般人整不明白这个,知道怎么回事就行了。
注:Embedding非常复杂,它不是一个简单的算法,而是用专门的Embedding模型。
下图就是一个比较简单的过程。
3、基于向量搜索的RAG架构
以下是一个最简单的向量搜索RAG架构示意图:
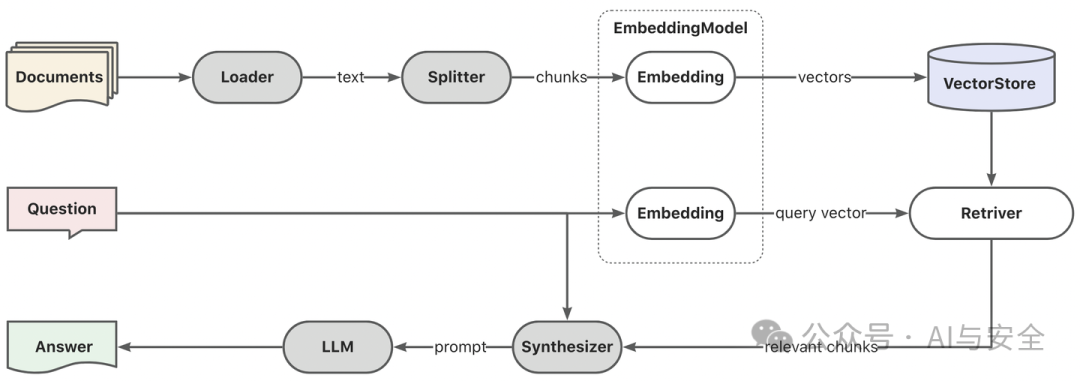
该架构关键有两个:
- 预处理文档。将文档的文本抽取出来(最初的大模型只能处理文本,所以只抽文本),分段,然后针对每一段作embedding存入向量数据库。
- 查询时,先把问题作Embedding,然后在向量数据库里把和问题最相关的内容(一般取Top K)取出来,将这些内容和原始问题结合,生成新的Prompt送给大模型,由大模型生成答案。
下面这个图更详细,包括了搜索的结果和重新生成prompt的例子
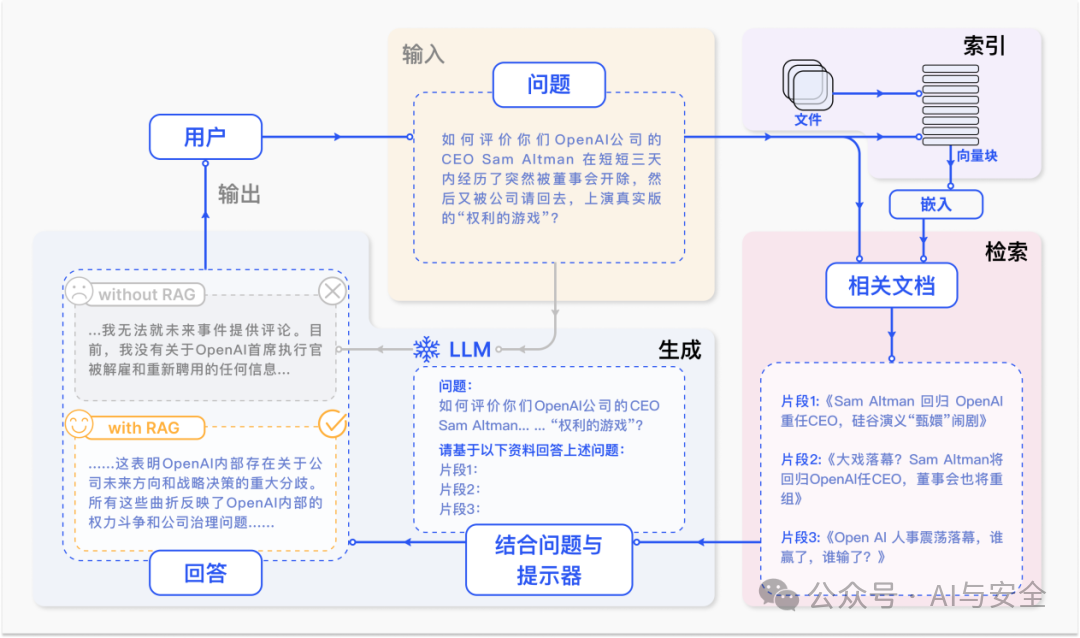
RAG方案,解决了大模型数据不足的问题,而处理数据是个核心需求,所以,备受重视。
实际发展中,针对文档的处理一直在进化。最初的分段(chunks)简单粗暴,就是把文本按长度截取,有些带格式的文档,比如word,pdf,分栏的时候,直接物理抽取,有时候内容就不伦不类,当然,基于这样的分段,大模型的回答也会比较乱。后来,针对各种文档抽取,图形结合的能力不断进步,效果也进步迅速。
4、图搜索RAG
向量搜索的方法一直在进步,但问题也一直在。虽然向量搜索技术能找到相似度很好的,但它无法进一步地理解私有数据中各个有效信息的关系,从而构成自己的知识网络,因此难以提供综合性的见解,也无法全面理解多个私有文献甚至单个文档的全部内容,因此往往无法回答抽象或总结性问题,自然也无法给大模型提供足够好的信息。
当前解决这些问题的办法,是知识图谱。
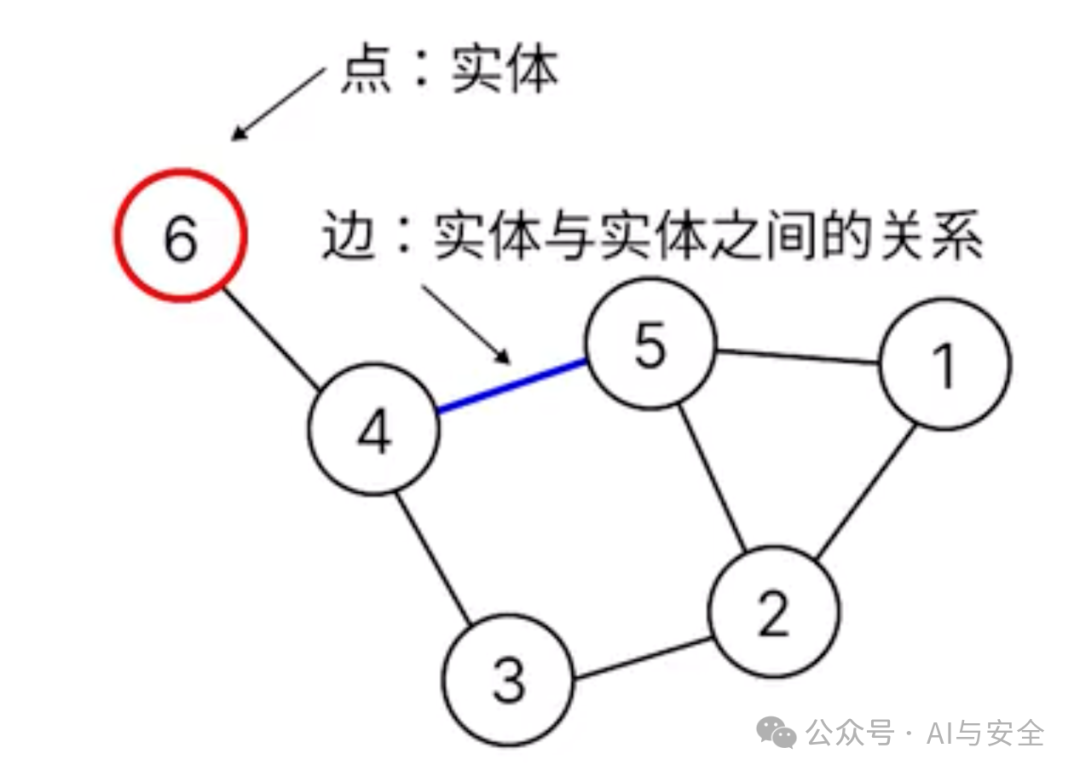
知识图谱:是结构化的语义知识库,用于描述物理世界中的概念及其相互关系。
知识图谱通过对错综复杂的文档的数据进行有效的加工、处理、整合,转化为简单、清晰的“实体,关系,实体”的三元组,最后聚合大量知识,从而实现知识的快速响应和推理。
原理表达是这样的:
一个具体的例子:
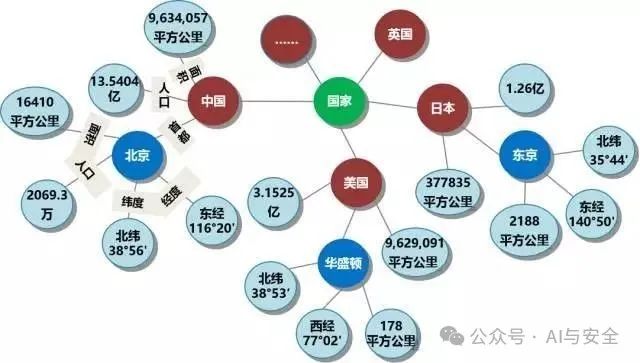
知识图谱已经发展了一些年,如何用于RAG?
微软最近开源了一个新的基于知识图谱构建的 RAG 系统——GraphRAG。Graphrag 框架旨在利用大型语言模型从非结构化文本中提取结构化数据,进而构建具有标签的知识图谱,以支持数据集问题生成、摘要问答等多种应用场景。GraphRAG 的一大特色是利用图机器学习算法针对数据集进行语义聚合和层次化分析。(详见论文1)
它的主要过程是这样的:
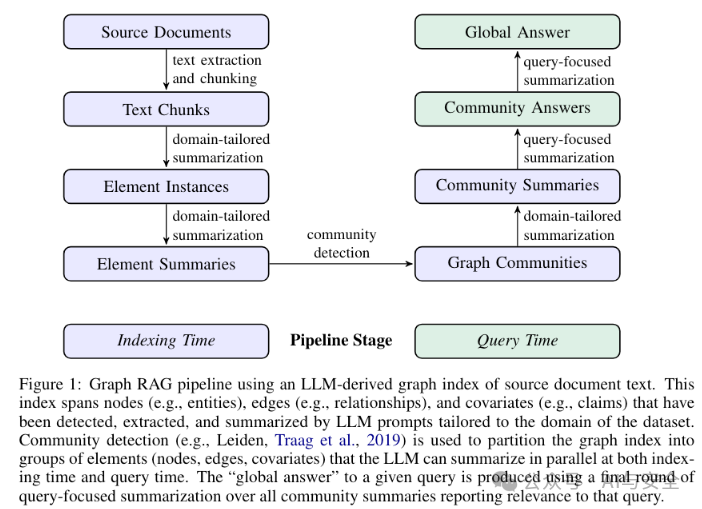
相对向量搜索,它在分段后,加入了元素和关系的一系列处理,形成答案,这个答案,已经不是原始内容,而是经过图搜索以后总结内容。
基于图搜索的RAG架构与向量搜索非常相似,只是搜索过程变了一下。
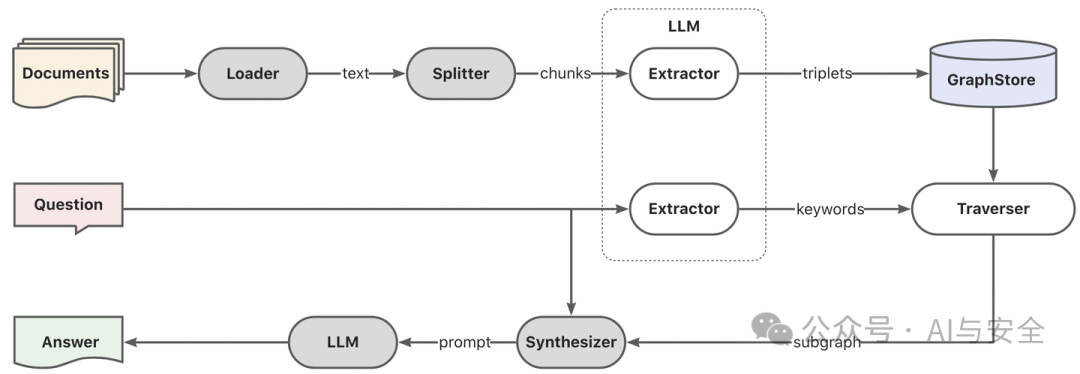
目前看,基于图搜索的RAG有点火,但后续进展,还需要观察。
5、更复杂一点的RAG
上边是一些RAG的简单的原理性的图,比较简单直接。这种简单架构,称之为Naive RAG(朴素RAG,天真RAG?)。实际上,RAG针对不同问题,有不同的解决方案,有一些是复杂一些的,一般叫高级RAG(Advanced RAG),比如下边这个:
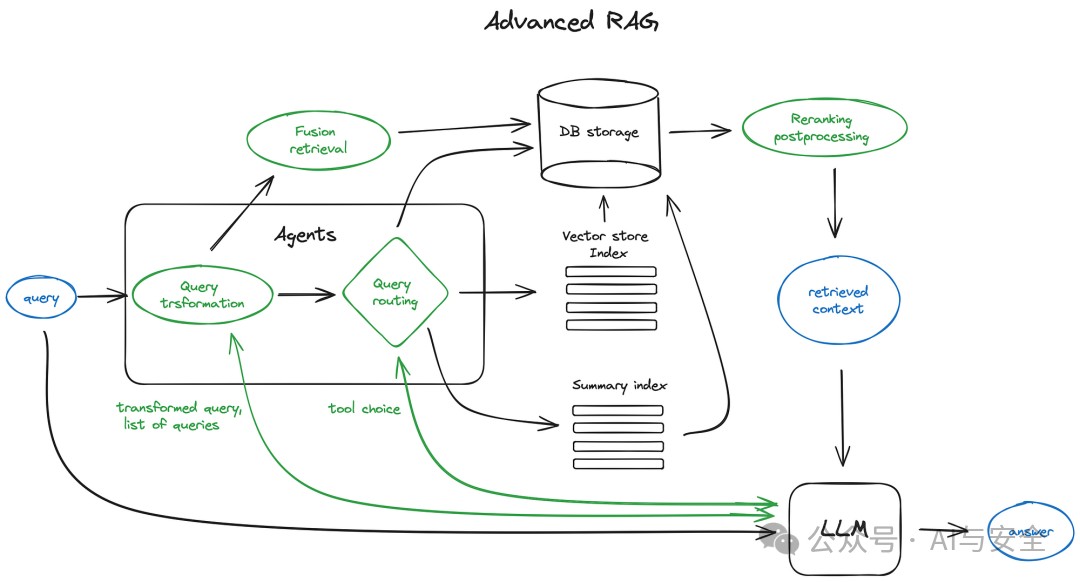
它把查询做了更复杂的路由处理,以期取得更好的效果。
下边这个,把向量搜索和图搜索结合在一起:
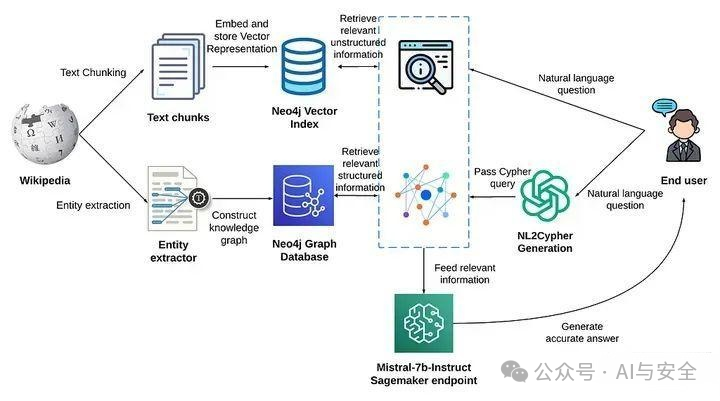
下图中间的Advaned RAG,进行了检索后处理。检索到相关上下文后,将其与查询有效集成至关重要。后检索过程中的主要方法包括 rerank chunks 和 context compressing。重新对检索到的信息进行排名,将最相关的内容重新定位到提示的边缘是一项关键策略。
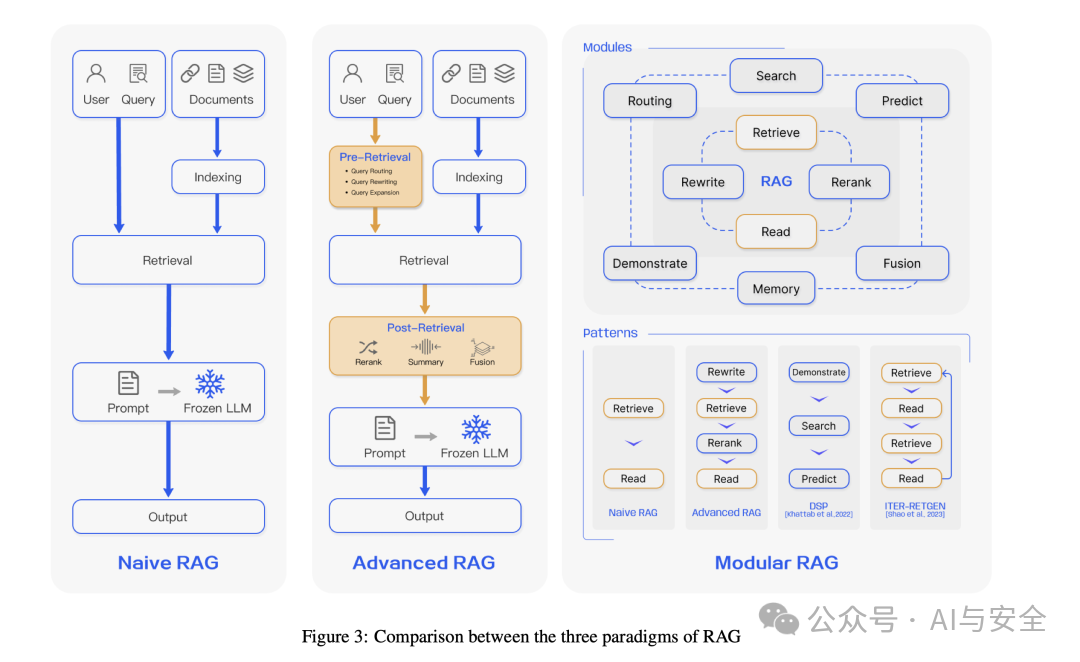
RAG 的三种范式之间的比较。(左)Naive RAG 主要由三个部分组成:索引、检索和生成。(中)Advanced RAG 围绕 pre-retrieval 和 post-retrieval 提出了多种优化策略,其过程类似于 Naive RAG,仍然遵循链状结构。(右)模块化 RAG 继承并发展自以前的范式,总体上表现出更大的灵活性。(详见论文2)
6、总结
RAG解决了一个大模型无法实时获取外部数据的问题,是一个非常大的进步。
但RAG方案真的很好吗?我觉得不够好。
打个比方,这个外部查询数据再送给大模型的方法,有点类似于一个教授在写论文,但它依靠的输入是一个小学生查的资料,并且这个资料它还必须用。你说教授能写出好论文?
但当前也没有更好的方案来解决这个问题。所以,在没有更好的方案之前,它仍然是最好的。
6.2 系统的持续优化
通过数据反馈、模型微调和算法优化,AI大模型问答系统能够不断进化。这使得系统不仅能够适应新兴问题,还能处理日益复杂的用户需求,为用户提供更加智能的服务。
如何学习AI大模型 ?
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
倘若大家对大模型抱有兴趣,那么这套大模型学习资料肯定会对你大有助益。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









