




 本文深入剖析HDFS写文件过程,从DistributedFileSystem.create()方法入手,详细讲解了主线程、DataStreamer线程和ResponseProcessor线程的功能,以及它们如何协作完成文件写入。特别关注了DFSOutputStream、Packet等关键数据结构,揭示了HDFS如何高效地处理数据块和校验和。
本文深入剖析HDFS写文件过程,从DistributedFileSystem.create()方法入手,详细讲解了主线程、DataStreamer线程和ResponseProcessor线程的功能,以及它们如何协作完成文件写入。特别关注了DFSOutputStream、Packet等关键数据结构,揭示了HDFS如何高效地处理数据块和校验和。
1.概述
通过fsShell或api在客户端断点调试,可以知道写文件入口DistributedFileSystem.create()。
|
|
下文从该方法开始分析。
DistributedFileSystem.create()主要调用过程如下。
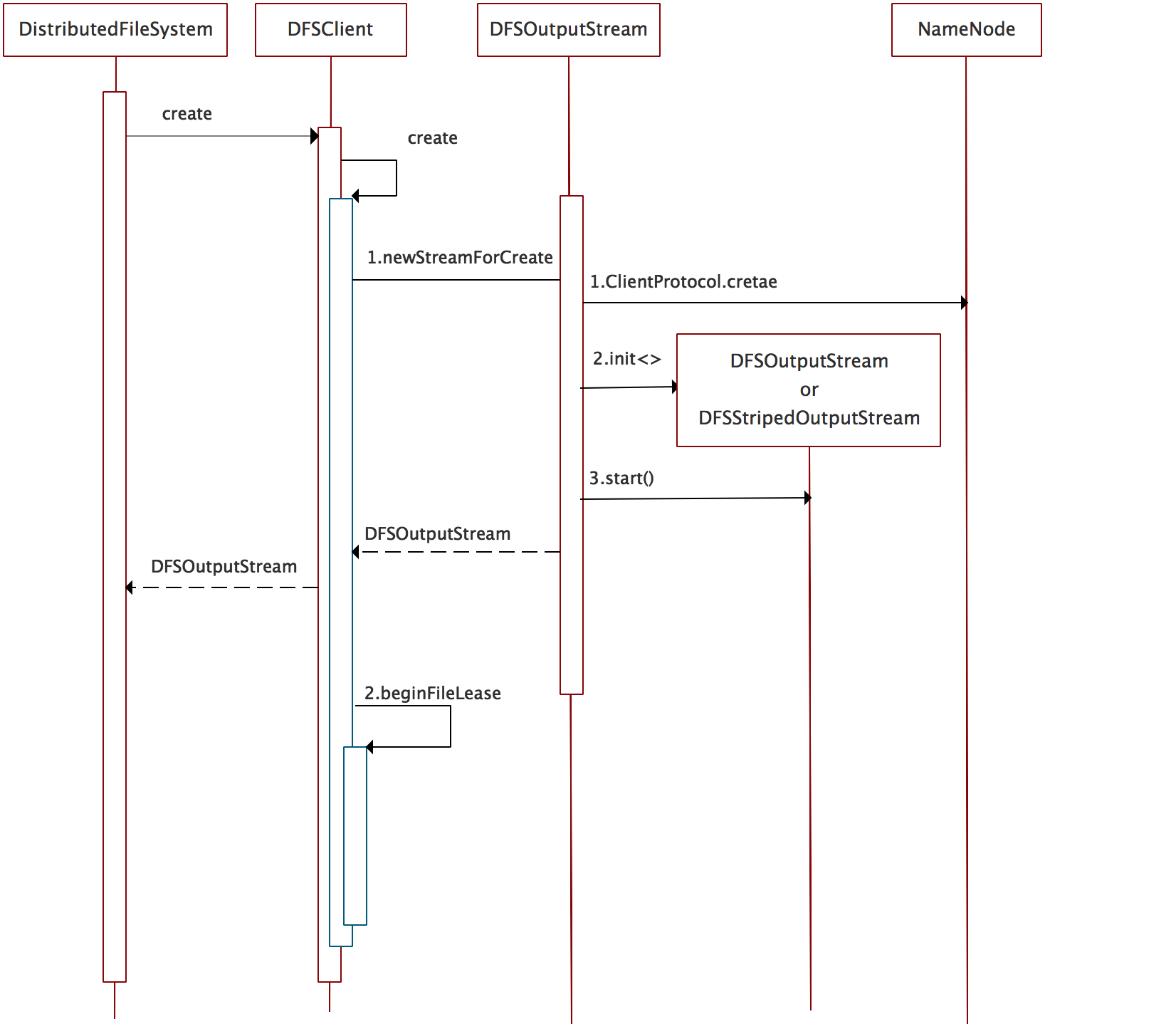
【流程说明】
- 通过DFSClient.create()创建一个新文件,获得输出流。构建输出流时通过ClientProtocol.create() RPC在NameNode创建文件。
- 调用DFSOutputStream.start()方法。实际会启动streamer线程,下文详解。
- 获得输出流后,通过beginFileLease开始文件租约。
【注意点】
- ClientProtocol.create() RPC返回HDFSFileStatus stat状态,从该标识中区分副本文件还是EC文件,创建对应的输出流,
即副本文件DFSOutputStream out =new DFSOutputStream(...),EC文件DFSOutputStream out = new DFSStripedOutputStream(...)。
2.主要数据结构
-
先分析创建输出流DFSOutputStream结构,如下:
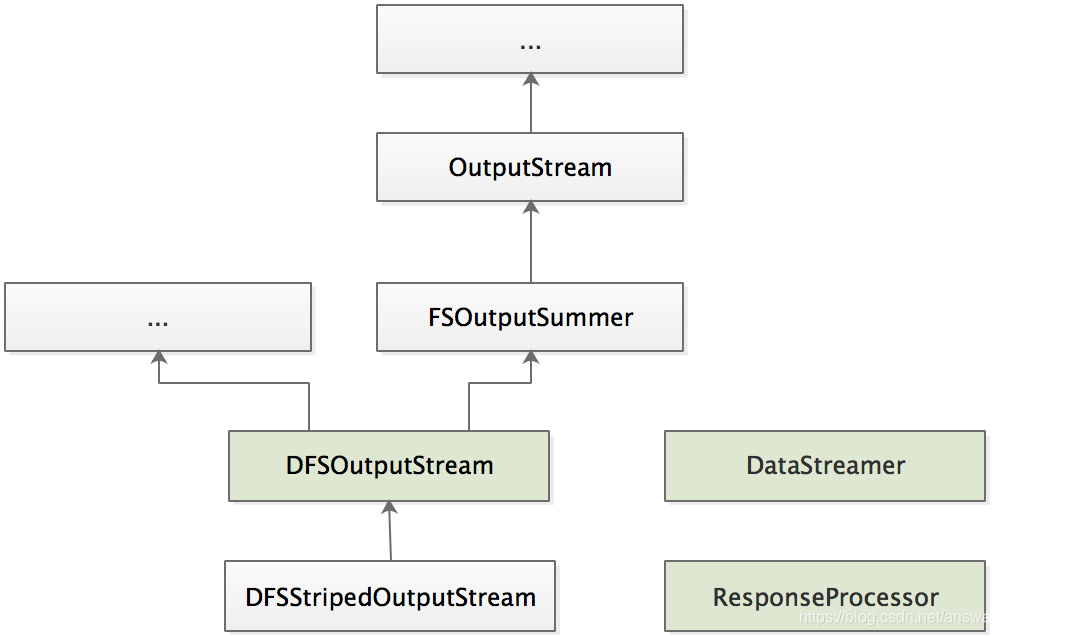
DFSOutputStream、DataStreamer、ResponseProcessor是写数据的三个线程类。
ResponseProcessor是DataStreamer的内部类。2.7版本中DataStreamer也是DFSOutputStream的内部类,3.2已经单独提出。
定义如下:
线程类的作用:classDataStreamerextendsDaemon {...}privateclassResponseProcessorextendsDaemon {...}
DataStreamer类负责将packets发送到pipeline中的数据节点,DataStreamer线程从dataQueue中picks up packets,发送到pipeline中的第一个datanode;
ResponseProcessor接收datanode返回的ack,并将其从dataQueue移至ackQueue,当所有datanode都返回了这个packets的successful ack,ResponseProcessor从ackQueue中删除相应的packets。

-
DFSOutputStream使用Packet来封装一个数据包,其结构如下。
在默认情况下(可debug调试),上述数据结构数据大小如下:
每个Packet可以有126个Chunk:Checksum+Data。Packet : 64k
CheckSum : 4Byte
Data: 512Byte
每个packet传输的data+checksum的字节为:126*516=65016字节。
每个packet传输的有效字节为:126*512=64512字节。通过debug,可以看到每个数据结构大小,部分log如下:
19/12/2310:35:58DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=6501619/12/2310:35:58DEBUG hdfs.LeaseRenewer: Lease renewer daemonfor[DFSClient_NONMAPREDUCE_-1334506554_1] with renew id1started19/12/2310:35:58DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000from hadoop sending #419/12/2310:35:58DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000from hadoop got value #419/12/2310:35:58DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 1ms19/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk allocatingnewpacket seqno=0, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=019/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=0, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=64512, blockSize=134217728, appendChunk=false19/12/2310:35:58DEBUG hdfs.DFSClient: Queued packet019/12/2310:35:58DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=6501619/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk allocatingnewpacket seqno=1, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=6451219/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=1, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=129024, blockSize=134217728, appendChunk=false19/12/2310:35:58DEBUG hdfs.DFSClient: Queued packet119/12/2310:35:58DEBUG hdfs.DFSClient: Allocatingnewblock19/12/2310:35:58DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=6501619/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk allocatingnewpacket seqno=2, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=12902419/12/2310:35:58DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=2, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=193536, blockSize=134217728, appendChunk=false
3.代码分析
获得输出流out后,就可以write数据了。如IOUtils.copyBytes工具。
先看一下调用栈如下:
|
|
以下围绕3个线程进行分析。
1.主线程
1.write
1)write()
-
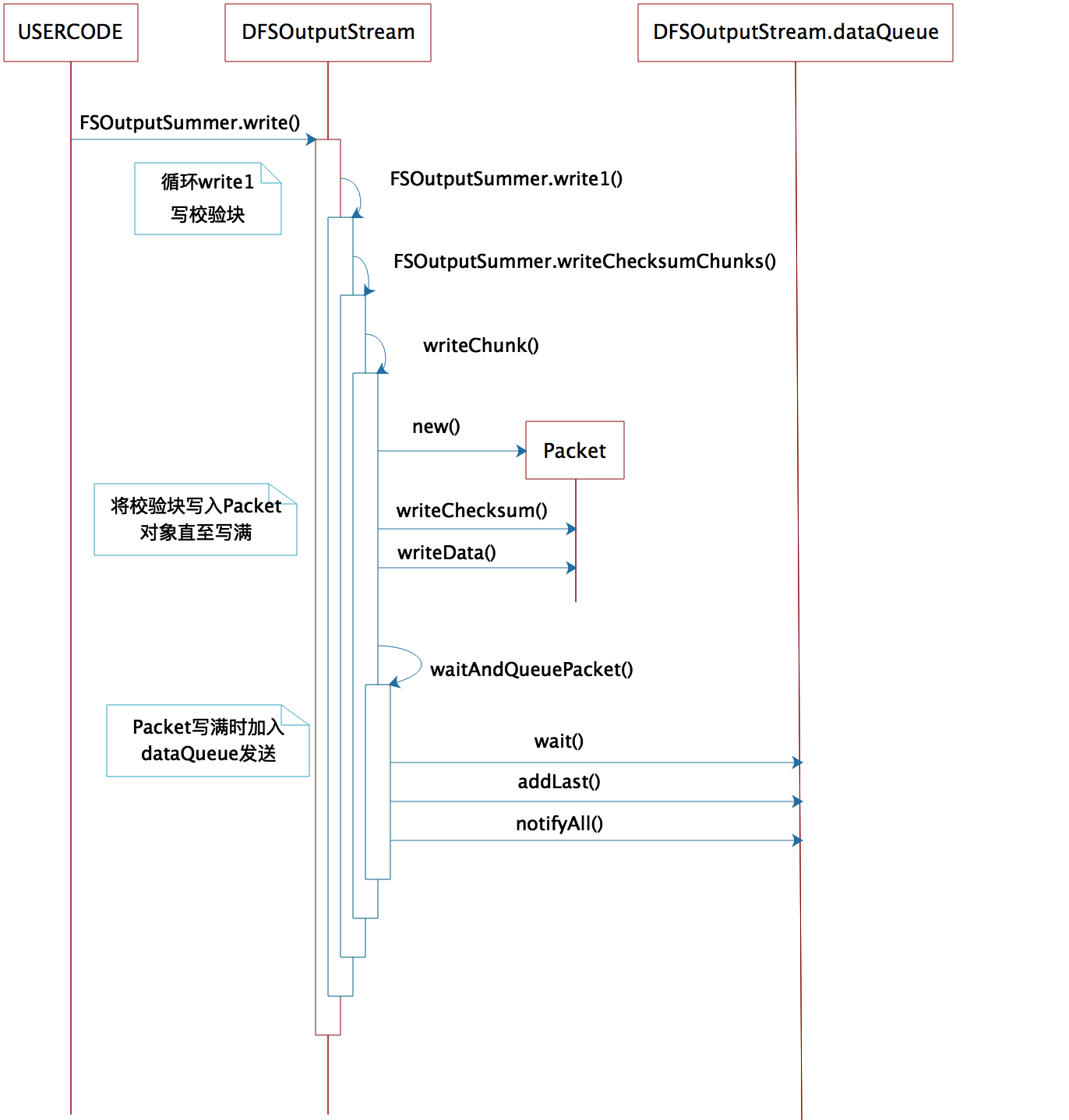
主线程主要执行write()方法。入口是抽象类FSOutputSummer.write()。
DFSOutputStream.write()继承FSOutputSummer.write()。write方法主要用于向pipeline中写入指定大小的数据及校验和。是客户端写数据操作的入口。// FSOutputSummer#write@Overridepublicsynchronizedvoidwrite(byteb[],intoff,intlen)throwsIOException {...//循环调用write1写数据,每次写入一个校验块,即checkChunk=checkSum+datafor(intn=0;n<len;n+=write1(b, off+n, len-n)) {}}
2)write1()
- write1每次写一个校验块数据。
- 当数据长度不足一个校验块时,则先写入buffer缓冲区,当buffer数据打到一个校验块时,调用flushBuffer();
-
如果buffer为空且数据大于一个校验块,则不经过buffer直接调用writeChecksumChunks()。
// FSOutputSummer#write1privateintwrite1(byteb[],intoff,intlen)throwsIOException {if(count==0&& len>=buf.length) {// local buffer is empty and user buffer size >= local buffer size, so// simply checksum the user buffer and send it directly to the underlying// streamfinalintlength = buf.length;writeChecksumChunks(b, off, length);returnlength;}// copy user data to local bufferintbytesToCopy = buf.length-count;bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy;System.arraycopy(b, off, buf, count, bytesToCopy);count += bytesToCopy;if(count == buf.length) {// local buffer is fullflushBuffer();}returnbytesToCopy;}
3)writeChunk()
- 无论是flushBuffer()还是writeChecksumChunks(),最终都调用writeChunk(),writeChunk()是抽象方法。最终由DFSOutputStream实现。
-
writeChunk()首先构造Packet对象,然后将校验块数据及校验和写入Packet对象中。当Packet对象写满时(maxChunks如126个校验块),则调用enqueueCurrentPacketFull()-->enqueueCurrentPacket()-->getStreamer().waitAndQueuePacket(currentPacket)将当前Packet放入输出队列dataQueue等待streamer处理,等待加入队列和发送。
protectedsynchronizedvoidwriteChunk(ByteBuffer buffer,intlen,byte[] checksum,intckoff,intcklen)throwsIOException {//构建currentPacketwriteChunkPrepare(len, ckoff, cklen);currentPacket.writeChecksum(checksum, ckoff, cklen);currentPacket.writeData(buffer, len);currentPacket.incNumChunks();getStreamer().incBytesCurBlock(len);// If packet is full, enqueue it for transmissionif(currentPacket.getNumChunks() == currentPacket.getMaxChunks() ||getStreamer().getBytesCurBlock() == blockSize) {//放入dataQueue队列enqueueCurrentPacketFull();}}
2.close
关闭DFSOutputStream并向NamenodeRPC,更新租约管理。dfsClient.namenode.complete(src, dfsClient.clientName, last, fileId);
说明:
- 如果是追加写(append),有可能最后一个校验块(chunk)并没有写满,新写的第一个校验块及Packet需要响应较少以至于补充满;
-
dataQueue.size() + ackQueue.size() > 80(默认值)时,Packet将等待。
主线程write流程如下:
2.DataStreamer
-
DataStreamer在DFSOutputStream的构造器中创建。
DataStreamer是一个线程类。从run方法入口,我们看到主要流程如下:protectedDFSOutputStream(DFSClient dfsClient, String src,HdfsFileStatus stat, EnumSet<CreateFlag> flag, Progressable progress,DataChecksum checksum, String[] favoredNodes,booleancreateStreamer) {...if(createStreamer) {streamer =newDataStreamer(stat,null, dfsClient, src, progress,checksum, cachingStrategy, byteArrayManager, favoredNodes,addBlockFlags);}}
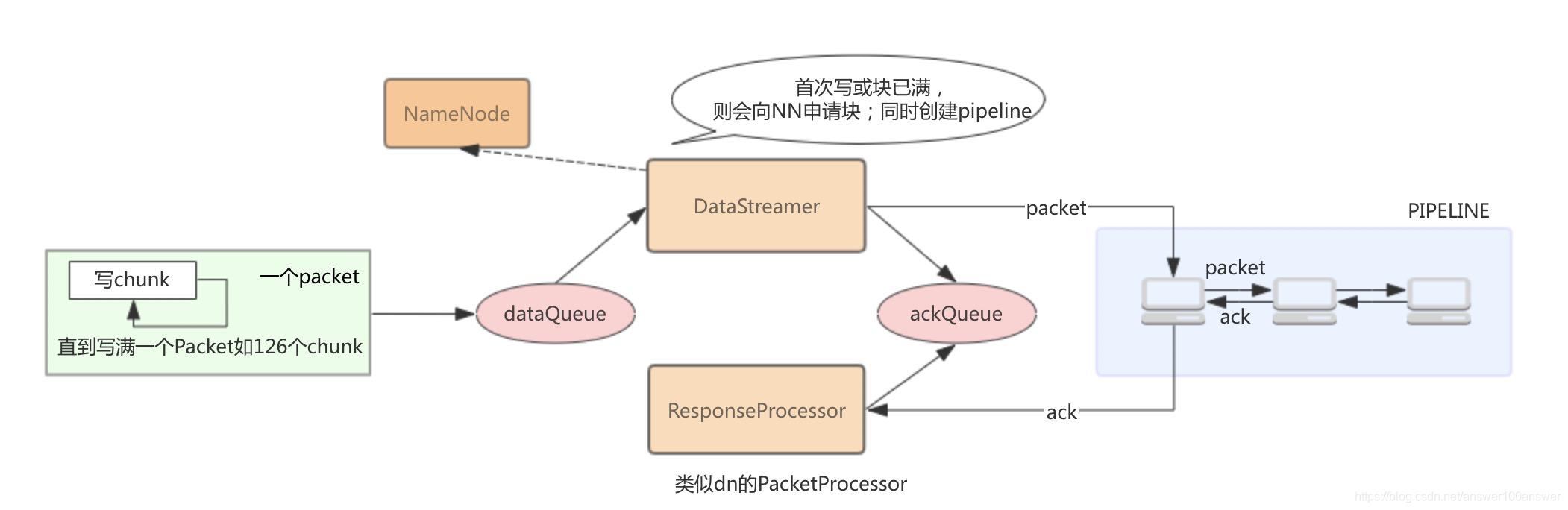
1)首先调用nextBlockOutputStream()向NameNode申请新的数据块blk;publicvoidrun() {...// if the Responder encountered an error, shutdown Responder...// get new block from namenode....// wait for all data packets have been successfully acked...// send the packet...// move packet from dataQueue to ackQueue...}
2)建立这个blk块对应的数据流管道pipeline;
3)从dataQueue中取出待发送的Packet,并通过pipeline发送给dataNode;
4)该blk的所有Packet都发送完毕并且获得ack后,streamer线程关闭该pipeline;
5)若还有数据再次申请数据块blk1并新建pipeline,重复上述1-4。 - 说明:DataStreamer针对错误处理做了很多复杂的工作。
3.ResponseProcessor
- DataStreamer每次发送一个Packet,pipeline中的datanode都会回复ack给客户端。PresponseProcessor就是处理ack响应的线程类。类似datanode上的PacketProcessor。
副本和EC文件流程
流程图如下:
- 副本
- EC
EC文件采用Striped块组方式存储。DataStreamer和ResponseProcessor都是线程组的方式出现。客户端具体对应的实现类为DFSStripedOutputStream。以下给出流程图。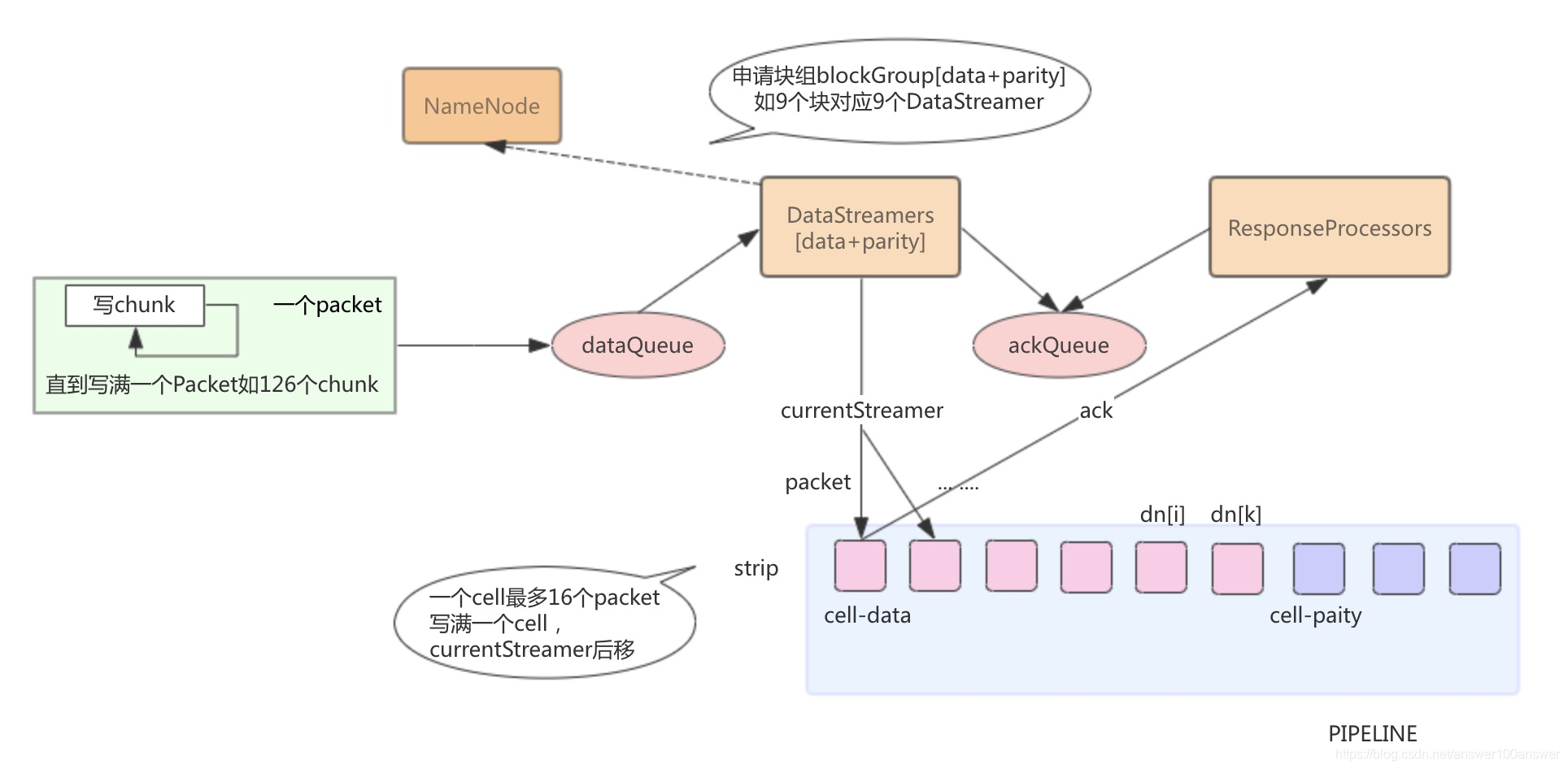


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









