




文章目录
使用测试集群使用FsShell断点
@Test
public void testWrite() throws Exception{
FsShell shell = new FsShell();
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://hadoop1:9000");
conf.setQuietMode(false);
shell.setConf(conf);
System.setProperty("HADOOP_USER_NAME", "hadoop");
System.setProperty("HADOOP_USER_PASSWORD", "xxx");
String local = "/Users/didi/CodeFile/proTest/hadoop-test/src/main/resources/test/core-site.xml";
String[] args = {"-put", local, "/test/write/1219-1.xml"}; // 普通目录ok
int res = 1;
try {
res = ToolRunner.run(shell, args);
} finally {
shell.close();
}
System.exit(res);
}
在org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.<init>构造器中加断点。
DFSOutputStream
"main@1" prio=5 tid=0x1 nid=NA runnable
java.lang.Thread.State: RUNNABLE
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.<init>(DFSOutputStream.java:276)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.<init>(DFSOutputStream.java:227)
at org.apache.hadoop.hdfs.DFSOutputStream.<init>(DFSOutputStream.java:1626)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1679)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1692)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1627)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:503)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:499)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:514)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:442)
at org.apache.hadoop.fs.FilterFileSystem.create(FilterFileSystem.java:179)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:979)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:960)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:857)
at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.create(CommandWithDestination.java:488)
at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.writeStreamToFile(CommandWithDestination.java:465)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyStreamToTarget(CommandWithDestination.java:391)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyFileToTarget(CommandWithDestination.java:328)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:263)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:248)
at org.apache.hadoop.fs.shell.Command.processPaths(Command.java:319)
at org.apache.hadoop.fs.shell.Command.processPathArgument(Command.java:291)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPathArgument(CommandWithDestination.java:243)
at org.apache.hadoop.fs.shell.Command.processArgument(Command.java:273)
at org.apache.hadoop.fs.shell.Command.processArguments(Command.java:257)
at org.apache.hadoop.fs.shell.CommandWithDestination.processArguments(CommandWithDestination.java:220)
at org.apache.hadoop.fs.shell.CopyCommands$Put.processArguments(CopyCommands.java:267)
at org.apache.hadoop.fs.shell.Command.processRawArguments(Command.java:203)
at org.apache.hadoop.fs.shell.Command.run(Command.java:167)
at org.apache.hadoop.fs.FsShell.run(FsShell.java:287)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at cn.whbing.hadoop.ReadWriteTest.testWrite(ReadWriteTest.java:132)
创建了临时文件如:
/test/write/1219-5.xml.COPYING
DataStreamer --> 是一个守护线程类。
1.主线程创建DFSOutputStream
static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize, Progressable progress, int buffersize,
DataChecksum checksum, String[] favoredNodes)

其中 FSOutputSummer 继承 OutputStream,主要是添加了一个计算checksum的功能。DFSOutputStream继承FSOutputSummer。
主要的三个类:
- DFSOutputStream
- DataStreamer
- ResponseProcessor
2
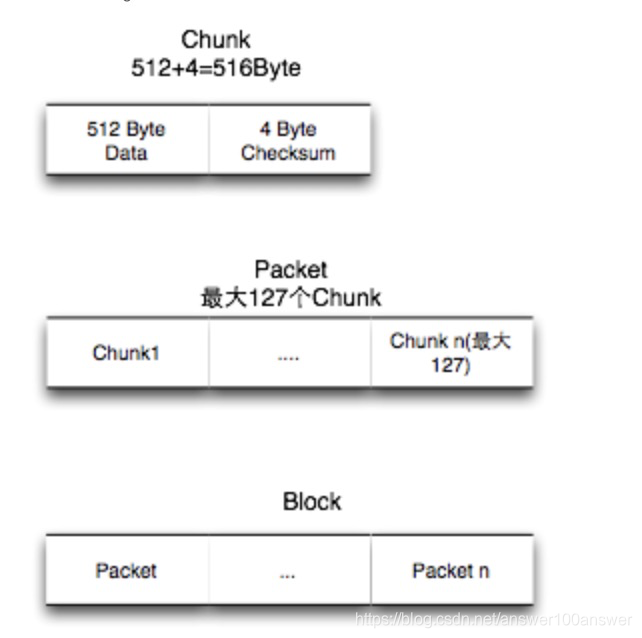
要把读写过程细节搞明白前,你必须知道block、packet与chunk
- block
block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定。文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。 - packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。 - chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
一个比较好的图如下:

对他的解释:
写过程中的三层buffer
写过程中会以chunk、packet及packet queue三个粒度做三层缓存;
- 首先,当数据流入DFSOutputStream时,DFSOutputStream内会有一个chunk大小的buf,当数据写满这个buf(或遇到强制flush),会计算checksum值,然后填塞进packet;
- 当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
- 进入dataQueue队列的packet会被另一线程(DataSreamer)按序取出发送到datanode,发送出去后,会将该packet放入ackQueue中;只有当ResponseProcessor线程收到下游节点传过来的ack消息后,才会将数据包从ackQueue中移除。(注:生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限)
DFSOutStream中使用 DFSPacket 来包装数据。
DFSPacket:
/**
* buf is pointed into like follows:
* (C is checksum data, D is payload data)
*
* [_________CCCCCCCCC________________DDDDDDDDDDDDDDDD___]
* ^ ^ ^ ^
* | checksumPos dataStart dataPos
* checksumStart
*
* Right before sending, we move the checksum data to immediately precede
* the actual data, and then insert the header into the buffer immediately
* preceding the checksum data, so we make sure to keep enough space in
* front of the checksum data to support the largest conceivable header.
*/

DataStreamer线程

DataStreamer将数据包通过管道发送给datanode,并在当前数据块写满时,向NN申请分配新的数据块,然后更新管道。DataStream定义了管道的状态信息:
// 数据块数据流管道中的datanode
private volatile DatanodeInfo[] nodes = null; // list of targets for current block
// 在dn上保存这个块的存储类型
private volatile StorageType[] storageTypes = null;
// 在dn上保存这个块的存储
private volatile String[] storageIDs = null;
// 数据块对应的数据流管道状态
private BlockConstructionStage stage; // block construction stage
...
private void setPipeline(DatanodeInfo[] nodes, StorageType[] storageTypes,
String[] storageIDs) {
this.nodes = nodes;
this.storageTypes = storageTypes;
this.storageIDs = storageIDs;
}
1.对于新写文件操作,DataStreamer会调用nextBlockOutputStream()方法向NN申请新的数据块,然后构建这个新的数据块的数据流管道。
// get new block from namenode.
if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Allocating new block");
}
setPipeline(nextBlockOutputStream()); //新写数据块时,先调用next
initDataStreaming(); // 再传输数据
} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Append to block " + block);
}
setupPipelineForAppendOrRecovery();
initDataStreaming();
}
2.对于append,会返回最后一个数据块的位置。根据最后一个数据块的位置信息初始化数据流管道。
3.成功构建管道后,会调用initDataStreaming将管道状态更改为DATA_STREAMING。然后就通过数据流管道发送数据。

PIPELINE整理
1. [HDFS写文件过程分析]
2. [Hadoop Pipeline详解]
3. [再议HDFS写流程之pipeline]
4.[HDFS源码分析(5):datanode数据块的读与写]
5.[Hhadoop-2.7.0中HDFS写文件源码分析(二):客户端实现之DFSPacket]
Hhadoop-2.7.0中HDFS写文件源码分析(二):客户端实现之DFSPacket

开启debug模式流程分析
hadoop fs -put xxx
...
19/12/23 09:11:46 DEBUG hdfs.DFSClient: /test/write/1.txt._COPYING_: masked=rw-r--r--
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #3
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #3
19/12/23 09:11:46 DEBUG ipc.ProtobufRpcEngine: Call: create took 13ms
19/12/23 09:11:46 DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/1.txt._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=65016
19/12/23 09:11:46 DEBUG hdfs.LeaseRenewer: Lease renewer daemon for [DFSClient_NONMAPREDUCE_-78804544_1] with renew id 1 started
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #4
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #4
19/12/23 09:11:46 DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 1ms
19/12/23 09:11:46 DEBUG hdfs.DFSClient: DFSClient writeChunk allocating new packet seqno=0, src=/test/write/1.txt._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=0
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Queued packet 0
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Queued packet 1
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Allocating new block
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Waiting for ack for: 1
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #5
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #5
19/12/23 09:11:46 DEBUG ipc.ProtobufRpcEngine: Call: addBlock took 29ms
19/12/23 09:11:46 DEBUG hdfs.DFSClient: pipeline = DatanodeInfoWithStorage[10.179.72.122:50010,DS-508839e9-efb9-417c-8aa9-fd7b5b78b688,DISK]
19/12/23 09:11:46 DEBUG hdfs.DFSClient: pipeline = DatanodeInfoWithStorage[10.179.72.42:50010,DS-239d3012-2d81-4f66-9b08-77e9d21397d1,DISK]
19/12/23 09:11:46 DEBUG hdfs.DFSClient: pipeline = DatanodeInfoWithStorage[10.179.16.227:50010,DS-286d8579-fe5f-484d-bb05-ae41787734e3,DISK]
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Connecting to datanode 10.179.72.122:50010
19/12/23 09:11:46 DEBUG hdfs.DFSClient: Send buf size 131072
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #6
19/12/23 09:11:46 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #6
19/12/23 09:11:46 DEBUG ipc.ProtobufRpcEngine: Call: getServerDefaults took 2ms
19/12/23 09:11:46 DEBUG sasl.SaslDataTransferClient: SASL client skipping handshake in unsecured configuration for addr = /10.179.72.122, datanodeId = DatanodeInfoWithStorage[10.179.72.122:50010,DS-508839e9-efb9-417c-8aa9-fd7b5b78b688,DISK]
19/12/23 09:11:47 DEBUG hdfs.DFSClient: DataStreamer block BP-857948820-10.179.72.122-1560825265775:blk_1073747684_6863 sending packet packet seqno: 0 offsetInBlock: 0 lastPacketInBlock: false lastByteOffsetInBlock: 1114
19/12/23 09:11:47 DEBUG hdfs.DFSClient: DFSClient seqno: 0 reply: SUCCESS reply: SUCCESS reply: SUCCESS downstreamAckTimeNanos: 545916 flag: 0 flag: 0 flag: 0
19/12/23 09:11:47 DEBUG hdfs.DFSClient: DataStreamer block BP-857948820-10.179.72.122-1560825265775:blk_1073747684_6863 sending packet packet seqno: 1 offsetInBlock: 1114 lastPacketInBlock: true lastByteOffsetInBlock: 1114
19/12/23 09:11:47 DEBUG hdfs.DFSClient: DFSClient seqno: 1 reply: SUCCESS reply: SUCCESS reply: SUCCESS downstreamAckTimeNanos: 1111705 flag: 0 flag: 0 flag: 0
19/12/23 09:11:47 DEBUG hdfs.DFSClient: Closing old block BP-857948820-10.179.72.122-1560825265775:blk_1073747684_6863
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #7
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #7
19/12/23 09:11:47 DEBUG ipc.ProtobufRpcEngine: Call: complete took 11ms
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #8
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #8
19/12/23 09:11:47 DEBUG ipc.ProtobufRpcEngine: Call: rename took 13ms
19/12/23 09:11:47 DEBUG ipc.Client: stopping client from cache: org.apache.hadoop.ipc.Client@d737b89
19/12/23 09:11:47 DEBUG ipc.Client: removing client from cache: org.apache.hadoop.ipc.Client@d737b89
19/12/23 09:11:47 DEBUG ipc.Client: stopping actual client because no more references remain: org.apache.hadoop.ipc.Client@d737b89
19/12/23 09:11:47 DEBUG ipc.Client: Stopping client
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop: closed
19/12/23 09:11:47 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop: stopped, remaining connections 0
注:上述debug打印了关键信息,下文会顺序分析;DFSClient的log不一定在该类中,可能是其他类中的调用。
核心流程
1.fs.create获得FSDataOutputStream,实质是DFSOutputStream。
中间借助DFSClient.create()方法进入:
public DFSOutputStream create(String src,
FsPermission permission,
EnumSet<CreateFlag> flag,
boolean createParent,
short replication,
long blockSize,
Progressable progress,
int buffersize,
ChecksumOpt checksumOpt,
InetSocketAddress[] favoredNodes) throws IOException {
checkOpen();
if (permission == null) {
permission = FsPermission.getFileDefault();
}
FsPermission masked = permission.applyUMask(dfsClientConf.uMask);
if(LOG.isDebugEnabled()) {
LOG.debug(src + ": masked=" + masked); // 1 该出的debug,见上述调试
}
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
buffersize, dfsClientConf.createChecksum(checksumOpt),
getFavoredNodesStr(favoredNodes)); // 2 获得Stream
beginFileLease(result.getFileId(), result); // 3 租约有关
return result;
}
注:该debug见上述打印,先建一个临时文件;并获得管道stream进行复杂操作;同时启动租约。

2.关键入口方法:DFSoutputStream.newStreamForCreate,通过构造器得到输出流。并同时启动输出流主线程。
static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize, Progressable progress, int buffersize,
DataChecksum checksum, String[] favoredNodes) throws IOException {
TraceScope scope =
dfsClient.getPathTraceScope("newStreamForCreate", src);
try {
HdfsFileStatus stat = null;
// Retry the create if we get a RetryStartFileException up to a maximum
// number of times
boolean shouldRetry = true;
int retryCount = CREATE_RETRY_COUNT;
while (shouldRetry) {
shouldRetry = false;
try {
stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
new EnumSetWritable<CreateFlag>(flag), createParent, replication,
blockSize, SUPPORTED_CRYPTO_VERSIONS);
break;
} catch (RemoteException re) {
IOException e = re.unwrapRemoteException(
AccessControlException.class,
DSQuotaExceededException.class,
FileAlreadyExistsException.class,
FileNotFoundException.class,
ParentNotDirectoryException.class,
NSQuotaExceededException.class,
RetryStartFileException.class,
SafeModeException.class,
UnresolvedPathException.class,
SnapshotAccessControlException.class,
UnknownCryptoProtocolVersionException.class);
if (e instanceof RetryStartFileException) {
if (retryCount > 0) {
shouldRetry = true;
retryCount--;
} else {
throw new IOException("Too many retries because of encryption" +
" zone operations", e);
}
} else {
throw e;
}
}
}
Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");
final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,
flag, progress, checksum, favoredNodes); // 获得输出流
out.start(); // 启动输出流注线程
return out;
} finally {
scope.close();
}
}
上述创建输出流分为三步:
(1)向NN发送请求,调用NN的create()方法(这块暂时不研究);
(2)通过构造器构造出输出流;
(3)启动输出流线程
后续流程均在out.start()方法中启动。即DFSOutputStream.run()方法。
根据调用栈及debuglog、代码可知,在DFSOutputStream的构造器中,调用了computePacketChunkSize。

上述数值固定。即每个packet有126个chunk,每个chunk大小(data 512 + checksum 4=516),header占了33个字节。(计算的值是126.9那么这里到底是用126还是127呢?)
每个packet传输的data+checksum的字节为:126*516=65016字节。
每个packet传输的有效字节为:126*512=64512字节。

文本如下:
19/12/23 10:35:58 DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=65016
19/12/23 10:35:58 DEBUG hdfs.LeaseRenewer: Lease renewer daemon for [DFSClient_NONMAPREDUCE_-1334506554_1] with renew id 1 started
19/12/23 10:35:58 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop sending #4
19/12/23 10:35:58 DEBUG ipc.Client: IPC Client (1537471098) connection to cluster-host1/10.179.72.122:9000 from hadoop got value #4
19/12/23 10:35:58 DEBUG ipc.ProtobufRpcEngine: Call: getFileInfo took 1ms
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk allocating new packet seqno=0, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=0
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=0, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=64512, blockSize=134217728, appendChunk=false
19/12/23 10:35:58 DEBUG hdfs.DFSClient: Queued packet 0
19/12/23 10:35:58 DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=65016
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk allocating new packet seqno=1, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=64512
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=1, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=129024, blockSize=134217728, appendChunk=false
19/12/23 10:35:58 DEBUG hdfs.DFSClient: Queued packet 1
19/12/23 10:35:58 DEBUG hdfs.DFSClient: Allocating new block
19/12/23 10:35:58 DEBUG hdfs.DFSClient: computePacketChunkSize: src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, chunkSize=516, chunksPerPacket=126, packetSize=65016
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk allocating new packet seqno=2, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, packetSize=65016, chunksPerPacket=126, bytesCurBlock=129024
19/12/23 10:35:58 DEBUG hdfs.DFSClient: DFSClient writeChunk packet full seqno=2, src=/test/write/hadoop-2.7.6-2.tar.gz._COPYING_, bytesCurBlock=193536, blockSize=134217728, appendChunk=false
每次传64512个有效字节,然后再新分配一个packet。
继续看分配packet的代码,在writeChunkImpl后续分析。

那么谁在调用看下调用栈:
java.lang.Thread.State: RUNNABLE
at org.apache.hadoop.hdfs.DFSOutputStream.computePacketChunkSize(DFSOutputStream.java:1741)
at org.apache.hadoop.hdfs.DFSOutputStream.writeChunkImpl(DFSOutputStream.java:1876)
- locked <0xaeb> (a org.apache.hadoop.hdfs.DFSOutputStream)
at org.apache.hadoop.hdfs.DFSOutputStream.writeChunk(DFSOutputStream.java:1813)
at org.apache.hadoop.fs.FSOutputSummer.writeChecksumChunks(FSOutputSummer.java:206)
at org.apache.hadoop.fs.FSOutputSummer.write1(FSOutputSummer.java:124)
at org.apache.hadoop.fs.FSOutputSummer.write(FSOutputSummer.java:110)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:58)
at java.io.DataOutputStream.write(DataOutputStream.java:107)
- locked <0xb29> (a org.apache.hadoop.hdfs.client.HdfsDataOutputStream)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:87)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:59)
at org.apache.hadoop.io.IOUtils.copyBytes(IOUtils.java:119)
at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.writeStreamToFile(CommandWithDestination.java:466)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyStreamToTarget(CommandWithDestination.java:391)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyFileToTarget(CommandWithDestination.java:328)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:263)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:248)
at org.apache.hadoop.fs.shell.Command.processPaths(Command.java:319)
at org.apache.hadoop.fs.shell.Command.processPathArgument(Command.java:291)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPathArgument(CommandWithDestination.java:243)
at org.apache.hadoop.fs.shell.Command.processArgument(Command.java:273)
at org.apache.hadoop.fs.shell.Command.processArguments(Command.java:257)
at org.apache.hadoop.fs.shell.CommandWithDestination.processArguments(CommandWithDestination.java:220)
at org.apache.hadoop.fs.shell.CopyCommands$Put.processArguments(CopyCommands.java:267)
at org.apache.hadoop.fs.shell.Command.processRawArguments(Command.java:203)
at org.apache.hadoop.fs.shell.Command.run(Command.java:167)
at org.apache.hadoop.fs.FsShell.run(FsShell.java:287)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at cn.whbing.hadoop.ReadWriteTest.testWrite(ReadWriteTest.java:133)
可以看到,调用FSOutputSummer.write,然后循环调用write1()。为什么这个线程栈和上述的不一样呢?我们将两个都列出来:
java.lang.Thread.State: RUNNABLE
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1679)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1692)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1627)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:503)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:499)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:514)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:442)
at org.apache.hadoop.fs.FilterFileSystem.create(FilterFileSystem.java:179)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:979)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:960)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:857)
at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.create(CommandWithDestination.java:488)
at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.writeStreamToFile(CommandWithDestination.java:465)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyStreamToTarget(CommandWithDestination.java:391)
at org.apache.hadoop.fs.shell.CommandWithDestination.copyFileToTarget(CommandWithDestination.java:328)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:263)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPath(CommandWithDestination.java:248)
at org.apache.hadoop.fs.shell.Command.processPaths(Command.java:319)
at org.apache.hadoop.fs.shell.Command.processPathArgument(Command.java:291)
at org.apache.hadoop.fs.shell.CommandWithDestination.processPathArgument(CommandWithDestination.java:243)
at org.apache.hadoop.fs.shell.Command.processArgument(Command.java:273)
at org.apache.hadoop.fs.shell.Command.processArguments(Command.java:257)
at org.apache.hadoop.fs.shell.CommandWithDestination.processArguments(CommandWithDestination.java:220)
at org.apache.hadoop.fs.shell.CopyCommands$Put.processArguments(CopyCommands.java:267)
at org.apache.hadoop.fs.shell.Command.processRawArguments(Command.java:203)
at org.apache.hadoop.fs.shell.Command.run(Command.java:167)
at org.apache.hadoop.fs.FsShell.run(FsShell.java:287)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at cn.whbing.hadoop.ReadWriteTest.testWrite(ReadWriteTest.java:133)
可以看到在 at org.apache.hadoop.fs.shell.CommandWithDestination$TargetFileSystem.writeStreamToFile(CommandWithDestination.java:465) 时,走向了不同的方法。
void writeStreamToFile(InputStream in, PathData target,
boolean lazyPersist) throws IOException {
FSDataOutputStream out = null;
try {
out = create(target, lazyPersist); // 1
IOUtils.copyBytes(in, out, getConf(), true); // 2
} finally {
IOUtils.closeStream(out); // just in case copyBytes didn't
}
}
分为两步,先创建一个流,再复制到目标流。
write中初次长度131072,write1每次写4608:

private synchronized void writeChunkImpl(byte[] b, int offset, int len,
byte[] checksum, int ckoff, int cklen) throws IOException {
dfsClient.checkOpen();
checkClosed();
if (len > bytesPerChecksum) {
throw new IOException("writeChunk() buffer size is " + len +
" is larger than supported bytesPerChecksum " +
bytesPerChecksum);
}
if (cklen != 0 && cklen != getChecksumSize()) {
throw new IOException("writeChunk() checksum size is supposed to be " +
getChecksumSize() + " but found to be " + cklen);
}
// 1 分配一个新的packet
if (currentPacket == null) {
currentPacket = createPacket(packetSize, chunksPerPacket,
bytesCurBlock, currentSeqno++, false);
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DFSClient writeChunk allocating new packet seqno=" +
currentPacket.getSeqno() +
", src=" + src +
", packetSize=" + packetSize +
", chunksPerPacket=" + chunksPerPacket +
", bytesCurBlock=" + bytesCurBlock);
}
}
currentPacket.writeChecksum(checksum, ckoff, cklen);
currentPacket.writeData(b, offset, len);
currentPacket.incNumChunks();
bytesCurBlock += len;
// If packet is full, enqueue it for transmission
//
if (currentPacket.getNumChunks() == currentPacket.getMaxChunks() ||
bytesCurBlock == blockSize) {
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("DFSClient writeChunk packet full seqno=" +
currentPacket.getSeqno() +
", src=" + src +
", bytesCurBlock=" + bytesCurBlock +
", blockSize=" + blockSize +
", appendChunk=" + appendChunk);
}
waitAndQueueCurrentPacket();
// If the reopened file did not end at chunk boundary and the above
// write filled up its partial chunk. Tell the summer to generate full
// crc chunks from now on.
if (appendChunk && bytesCurBlock%bytesPerChecksum == 0) {
appendChunk = false;
resetChecksumBufSize();
}
if (!appendChunk) {
int psize = Math.min((int)(blockSize-bytesCurBlock), dfsClient.getConf().writePacketSize);
computePacketChunkSize(psize, bytesPerChecksum);
}
//
// if encountering a block boundary, send an empty packet to
// indicate the end of block and reset bytesCurBlock.
//
if (bytesCurBlock == blockSize) {
currentPacket = createPacket(0, 0, bytesCurBlock, currentSeqno++, true);
currentPacket.setSyncBlock(shouldSyncBlock);
waitAndQueueCurrentPacket();
bytesCurBlock = 0;
lastFlushOffset = 0;
}
}
}
1.分配一个新的packet,createPacket
2.往这个packet中写checum、data:
currentPacket.writeChecksum(checksum, ckoff, cklen);
currentPacket.writeData(b, offset, len);
currentPacket.incNumChunks();
bytesCurBlock += len;

private void waitAndQueueCurrentPacket() throws IOException {
synchronized (dataQueue) {
try {
// If queue is full, then wait till we have enough space
boolean firstWait = true;
try {
while (!isClosed() && dataQueue.size() + ackQueue.size() >
dfsClient.getConf().writeMaxPackets) {
if (firstWait) {
Span span = Trace.currentSpan();
if (span != null) {
span.addTimelineAnnotation("dataQueue.wait");
}
firstWait = false;
}
try {
dataQueue.wait();
} catch (InterruptedException e) {
// If we get interrupted while waiting to queue data, we still need to get rid
// of the current packet. This is because we have an invariant that if
// currentPacket gets full, it will get queued before the next writeChunk.
//
// Rather than wait around for space in the queue, we should instead try to
// return to the caller as soon as possible, even though we slightly overrun
// the MAX_PACKETS length.
Thread.currentThread().interrupt();
break;
}
}
} finally {
Span span = Trace.currentSpan();
if ((span != null) && (!firstWait)) {
span.addTimelineAnnotation("end.wait");
}
}
checkClosed();
queueCurrentPacket();
} catch (ClosedChannelException e) {
}
}
}
private void queueCurrentPacket() {
synchronized (dataQueue) {
if (currentPacket == null) return;
currentPacket.addTraceParent(Trace.currentSpan());
dataQueue.addLast(currentPacket);
lastQueuedSeqno = currentPacket.getSeqno();
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Queued packet " + currentPacket.getSeqno());
}
currentPacket = null;
dataQueue.notifyAll();
}
}
writeMaxPackets 默认80,dataQueue + ackQueue > 80时就要等待。

1.使用nextBlockOutputStream向集群申请分配新的数据块。然后构造这个数据块的pipeline。

run(){
...
// get new block from namenode.
if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
if(DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("Allocating new block");
}
setPipeline(nextBlockOutputStream());
initDataStreaming();
} else if ...
...
}
上述三个方法如下:
- nextBlockOutputStream: 向NN申请分配新的数据块。
private LocatedBlock nextBlockOutputStream(){
...
// 故障节点
DatanodeInfo[] excluded =
excludedNodes.getAllPresent(excludedNodes.asMap().keySet())
.keySet()
.toArray(new DatanodeInfo[0]);
...
// 创建到第一个datanode的输出流
//
// Connect to first DataNode in the list.
//
success = createBlockOutputStream(nodes, storageTypes, 0L, false);
// 如果不成功,则放弃块
if (!success) {
DFSClient.LOG.info("Abandoning " + block);
// 将dadanode放入故障节点中
dfsClient.namenode.abandonBlock(block, fileId, src,
dfsClient.clientName);
block = null;
DFSClient.LOG.info("Excluding datanode " + nodes[errorIndex]);
excludedNodes.put(nodes[errorIndex], nodes[errorIndex]);
}
} while (!success && --count >= 0); // 进行重试
}
2.获取到数据管道中的第一个datanode的IO流,然后通过这个IO流发送数据包。
// get packet to be sent.
// 取出一个包,或者构造一个心跳包
if (dataQueue.isEmpty()) {
one = createHeartbeatPacket();
assert one != null;
} else {
one = dataQueue.getFirst(); // regular data packet
long parents[] = one.getTraceParents();
if (parents.length > 0) {
scope = Trace.startSpan("dataStreamer", new TraceInfo(0, parents[0]));
// TODO: use setParents API once it's available from HTrace 3.2
// scope = Trace.startSpan("dataStreamer", Sampler.ALWAYS);
// scope.getSpan().setParents(parents);
}
}
从dataQueue中取出一个待发送的packet,如果是最后一个,则构造一个空的心跳包。


心跳包与最后一个包?
A:心跳包一定不是最后一个包。
(四)心跳包
如果长时间没有数据传输,在输出流未关闭的情况下,客户端会发送心跳包给数据节点,心跳包是DataPacket的一种特殊实现,它通过数据包序列号为-1来进行特殊标识,如下:
/**
* Check if this packet is a heart beat packet
* 判断该包释放为心跳包
*
* @return true if the sequence number is HEART_BEAT_SEQNO
*/
boolean isHeartbeatPacket() {
// 心跳包的序列号均为-1
return seqno == HEART_BEAT_SEQNO;
}
而心跳包的构造如下:
/**
* For heartbeat packets, create buffer directly by new byte[]
* since heartbeats should not be blocked.
*/
private DFSPacket createHeartbeatPacket() throws InterruptedIOException {
final byte[] buf = new byte[PacketHeader.PKT_MAX_HEADER_LEN];
return new DFSPacket(buf, 0, 0, DFSPacket.HEART_BEAT_SEQNO,
getChecksumSize(), false);
}


queue到达80个的时候,不能再往队列中加了。必须要发送了。
上述写了一个块:DataStreamer block BP-857948820-10.179.72.122-1560825265775:blk_1073747689_6868



















 851
851




 到【灌水乐园】发言
到【灌水乐园】发言







