



 文章介绍了seq2seq模型在序列生成任务中的应用,特别是用于句子翻译。模型由Encoder和Decoder两部分组成,Encoder通过RNN捕捉输入序列的隐藏状态,Decoder则利用这些状态进行解码生成目标序列。在训练过程中,真实翻译作为Decoder的输入,而在推理时,预测的输出会作为下一次迭代的输入。BLEU指标被用来衡量生成句子的质量,通过n-gram的精确度和长度惩罚来评估预测序列与目标序列的相似性。
文章介绍了seq2seq模型在序列生成任务中的应用,特别是用于句子翻译。模型由Encoder和Decoder两部分组成,Encoder通过RNN捕捉输入序列的隐藏状态,Decoder则利用这些状态进行解码生成目标序列。在训练过程中,真实翻译作为Decoder的输入,而在推理时,预测的输出会作为下一次迭代的输入。BLEU指标被用来衡量生成句子的质量,通过n-gram的精确度和长度惩罚来评估预测序列与目标序列的相似性。
模型用途:该模型的用途在于通过序列生成序列,实际用途以句子翻译为主,可处理任意长度的句子。
模型结构:

seq2seq模型结构
模型由Encoder与Decoder组成:
Encoder是由RNN组成的,用于获取整个句子的隐藏状态,可以为双向,也可为单向;
Decoder也是由RNN组成的,但仅能为单向;
在执行seq2seq的过程中,Encoder种的RNN将整合后的隐藏状态(包含相对位置信息)发送给Decoder进行解码,从而实现翻译;
编码器及信息传递细节:
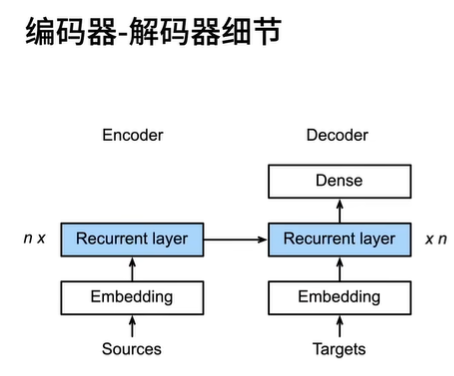
需要注意的点在于,编码器是一个“没有输出的”RNN,所谓没有输出在于其最后没有添加一个常规的全连接层用于产生结果,而是将“最后一层”的RNN输出的隐藏状态作为输出,然后将其与句子的Embedding结合,再输入到Decoder中;
训练与推理的区别
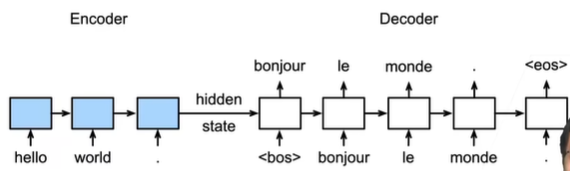
训练过程
在训练时,解码器的输入以原句子的真实翻译作为输入,可以看到,第一块的输入为<bos>,第二块的输入内容原本应为第一块的输出(预测内容),但是为防止第一块的预测错误,那么仅以训练来讲,其输入仍然为真实的翻译bonjour。

推理过程
在实际推理时,可以看到,前一块的预测输出作为了后一块RNN的输入。
如何衡量生成句子的好坏(类损失函数)——BLEU

使用n-gram衡量预测精度
首先需要指出n-gram的定义,比如p1,对于预测序列中的A, B, B, C, D,第二个B相对于标签序列多余,也即是错误的,那么p1=4/5;再比如p2,指的是预测序列与标签序列中相邻两个词出现次数正确的概率。如预测序列中A-B, B-B, B-C, C-D,四个中只有三个是正确的,那么p2=3/4。
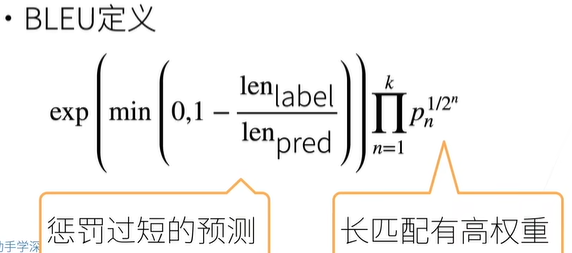
BLEU的定义
上图为BLEU的定义,len label为标签序列长度,len pred为预测序列长度,长度越短,惩罚越高。对于句内的n-gram,匹配越长,权重越高(pn是一个小于1的数,那么n越大(句内匹配越长,权重越高),1/2^n越小,达到权重更高的目的)。
代码:
【62 序列到序列学习(seq2seq)【动手学深度学习v2】】 https://www.bilibili.com/video/BV16g411L7FG/?p=2&share_source=copy_web&vd_source=54a003f2fe57290ef9f347426cdb53c9


















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











