 自然语言驱动的视觉模型:CLIP的零样本预测与数据集构建
自然语言驱动的视觉模型:CLIP的零样本预测与数据集构建





根据题目,我们发现有两个关键字,一个是自然语言,另一个是可迁移性
目的就是想通过建立与语义之间的联系学一个泛化性很好的视觉模型!
总体方法
- 对比学习联合训练一个图像特征提取器和一个文本特征提取器
- 零样本预测:给定图像,通过图像特征提取和通过模板和类别构成的文本特征进行coisine 相似度比对
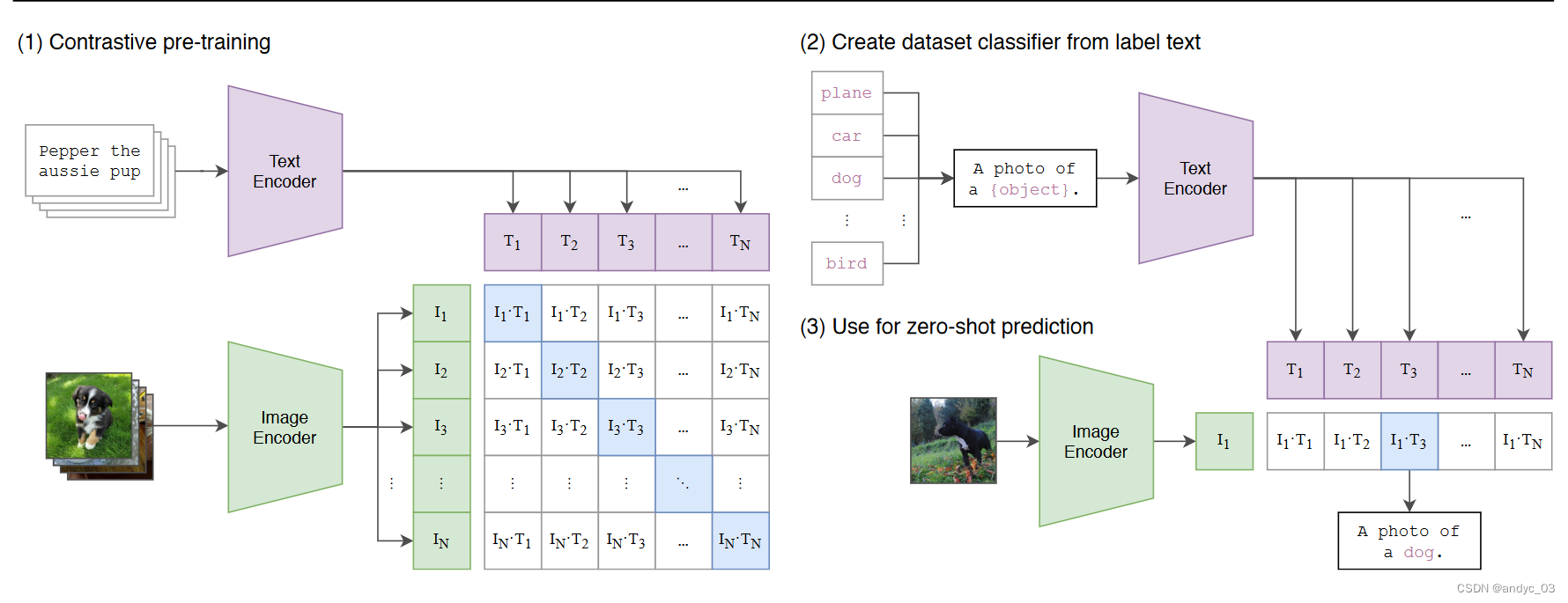
效果
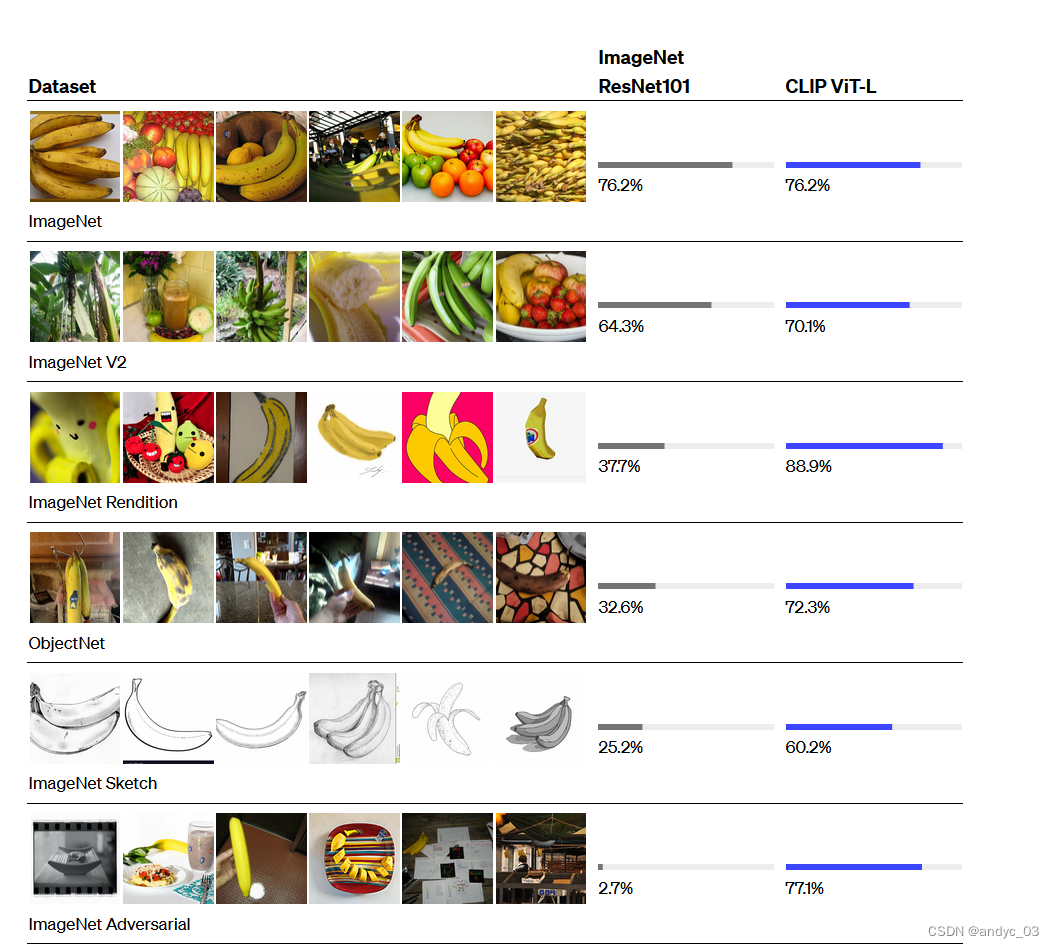
在ImageNet上零样本预测精度很高,且迁移效果很好,有很强的语义性,证明了其与我们的语义世界产生了很强的联系
还引发了很多有趣的工作,例如StyleCLIP,CLIPDraw,Object Dection via knowledge
(open - vocabulary)
相关工作
NLP 中的 Text-to-Text 的模型使得我们不需要去专门设计输出头去完成相应的下游任务
而在CV领域这样的工作却很少见,更多的还是在有监督的数据集上进行固定类别的分类训练,有个别工作尝试去做无监督的zero-shot但是由于缺少大规模的数据集等原因,导致了其效果极差,没能够引起大家的热情。
而本篇论文就是去close this gap,将数据集推到足够大,来展现这种方法的惊人效果。
数据集构建
工作在自然语言上的方法可以被动地从互联网上海量文本中蕴含的监督中学习,数据更容易收集。
目前有MS-COCO,Visual Genome都是高质量的人群标注数据集,但是规模太小。
YF
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 384
384



 到【灌水乐园】发言
到【灌水乐园】发言








