




"大佬 我看你这项目直接把doc 扔给llm 分析相关性啊, token不大惨了啊"。
这是大部分尝试去理解 auto-coder.RAG 知识库底层原理的人的第一反应。实际上 auto-coder.RAG 有大量反业界常识设计。
充满反骨的auto-coder.RAG 知识库
第一个最大的大反直觉设计,就是把文档全部交给大模型做召回这个事。
我们从工程角度让这件看起来粗暴的事情变得可行,我们来一起看看:
1. 从速度角度,我们基本可以确保第一个token出现的速度,就是整个过滤时间,并且几乎只消耗input token, 从模型供应商角度而言,只要他GPU资源足,那么就不会受到速度困扰(如果你依赖output token,就会受限于decoding的限制,就算GPU充足,速度也是有上限规模的。)
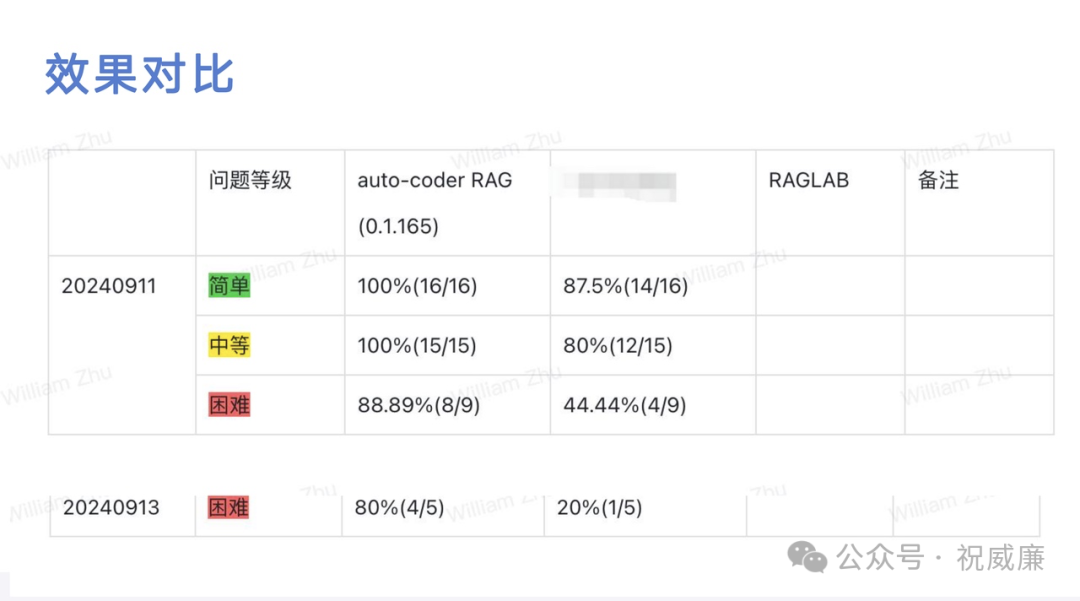
2. 从效果来看,我们的设计,基本上就是你给我的模型越好,我的效果就越好,你愿意投钱,效果也可以越好。而传统 EMB 架构的 RAG 是你给钱,给好的模型,效果也不会有太大提升。我们的效果有多好的呢?我么有个用户他实际用下来用了半年,给我的反馈是,达到了和 notebookllm 差不多的效果(但是notebookllm 实际上还是完全依赖自己Google模型超长上下文的,而我们还是通用的 RAG 知识库,可以支持任意多的token规模数,不受 1m 的限制)
3. 从成本角度看,我们全球第一时间适配了 DeepSeek 的缓存机制,让输入成本再降2/3 左右(每百万可以到1块钱以内),并且量大,你还可以和供应商谈。此外单次请求,我们可以精确计算成本消耗。
实际上,对于普通用户,全部给这个默认设置足够好了(你的文档规模几百万token的话),而且效果也能获得最佳。
很多用户会感到惊讶,还有一个原因是,就是成本过于透明以后,他直观的感受到了成本,本质还是因为他现在的 RAG 场景实际上可有可无,价值,如果场景是一个特别值钱,甚至对赚钱很重要的情况,用户就不会这么敏感,甚至会觉得越贵越好(只要能效果能通过投钱不断提升。。。这是一件非常的好事)。 而 auto-coder.RAG 知识库就是那个,你只要愿意花钱就能提升效果,而不是花了钱,还不知道能不能提升效果,你的每一分钱提升了多少百分比都是可以精确计算的。
当然了,也有个悖论,有价值的场景和用户是稀缺的,你想让用户真的用起来,除了引导,还需要让成本变得用户感知上能接受,此外用户可能确实有几千万,上亿token规模的文档。于是我们也通过 duckdb/byzer storage 做成本和效果的 balance 平衡,整体而言,我们的发展路子是从上往下走的。。。先做到效果top,然后再不断的减低效果来降低成本,这个和 OpenAI 的策略是颇为类似的。
说到 duckdb/byzer storage , 其中 byzer storage 是我们自研的全文检索+向量融合存储和召回引擎,效果也很好,而且我们的用法也是反直觉的,比如我们基于duckdb/byzer storage 做召回,就没有所谓相似度阈值的设计,我们从 duckdb/byzer storage 做召回的时候,是按token数来做阈值的,比如你可以控制输出100万token,那么他就输出100万token,而不是所谓相似度分值。这个就是为了控制成本而诞生的一个阈值,而不是为了效果做的设计。
第三个反直觉设设计,我们也有rerank 阶段,但是我们没有使用任何rerank 模型,不像业界傻不拉几的按所谓相关度重排,而是采用了“信息还原” 为基本原则来做重排。比如我们召回了两个来自同一个文章的片段,我们重排是按出现片段在文档中按其出现顺序来实际顺序,保证来自同一篇文章的片段都被紧挨着排序,这样可以显著的降低回答模型看信息的难度。此外,对于比如如果是两篇文章有多个片段都出现了,我们有一套完整策略保证文章之间,文章内部片段顺序性。
第四个反直觉设计是,我们片段是会根据模型窗口,会自动调整,把小的文档做合并,把大的文档做超大切片(比如单个切片40k token),并且在做完召回后,会对切片做二次动态信息抽取,这种也是基于 emb 架构的RAG知识库不会做的。此外,我们认为窗口是极度稀缺的资源,我们将窗口按内存的方式进行管理,有全文区,有片段区,有缓存区等等,确保窗口被高质量,非重复的内容占用。
RAG 的第二层认知
最后,对于 RAG知识库,很多人是没有看到的本质的,大部分人对 RAG 知识库的认知是问答场景,也就是根据文档回答问题。这其实是一个非常初级的认知,同时这种使用场景也是一个非常初级的场景。
RAG 的本质是:
1. 从一堆tokens中,抽取范式/经验
2. 通过抽取的范式和经验,对新数据做处理
也就是RAG的服务不是人,而是新的数据。现在可以简单理解为,所谓“范式和经验” 等价于 ==> 资深老人。 大模型擅长“范式和经验”的抽取和模仿,而不是创新。听着比较抽象,等后续我做几个案例出来,大家就容易理解了。
最后吹了这么多,大家可以在通过这里的文档感受下 auto-coder.RAG (或者点击原文链接):
https://uelng8wukz.feishu.cn/wiki/Ham5w4qpRi5OoSkNyyAcM30Enmf?fromScene=spaceOverview

















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









