



背景
LLM-Native 的最大特点就是抛弃 embedding/rerank 体系,只依赖大模型完成召回,切片,以及确保窗口的超高有效信息占比,从而保证最后的准确性。
但是 RAG 始终被困扰的问题在于灵活度不足,
比如用户的很多问题是需要一定推理的,比如A和B谁大,你直接做去问RAG,RAG可能无法回答。如果你拆解成两个问题,A多大,B多大,分别询问 RAG,可能就能得到答案。为此很多人引入了诸如图等,提前做大量的预计算来完成。这种灵活度不足,成本消耗巨大(项目所有文档都要读取,并且有超大输出)。
还有就是超大规模项目的理解其实是非常困难的。你需要先通过RAG得到一些种子,然后再仔细查看必要的内容并且根据内容里的细节再去查找相关内容,最后才能得到答案。这些都是传统 RAG 或者 llm-native 难以满足的。
为此,我们推出了 Agentic LLM-Native RAG: auto-coder.RAG, 该RAG巧妙的融合两者,实现了几乎最高天花板的效果。
使用和验证效果
安装一个RAG库
pip install -U auto-coder然后选择一个有文档或者源码的目录启动RAG服务:
auto-coder.rag serve --agentic \--lite --port 8109 \--doc_dir /Users/allwefantasy/projects/auto-coder \--model ark_v3_0324_chat --enable_local_image_host \--required_exts .py接着在 cherry studio 配置OpenAI 兼容模型,地址为 http://127.0.0.1:8109/v1

现在可以直接在cherry studio里问问题了,我询问了一个auto-coder自身,该项目已经开发了一年多,具备一定的复杂度,且RAG只是里面部分比较小功能,我们看是否能够大海捞针,准确的回答用户。下面是回答结果:
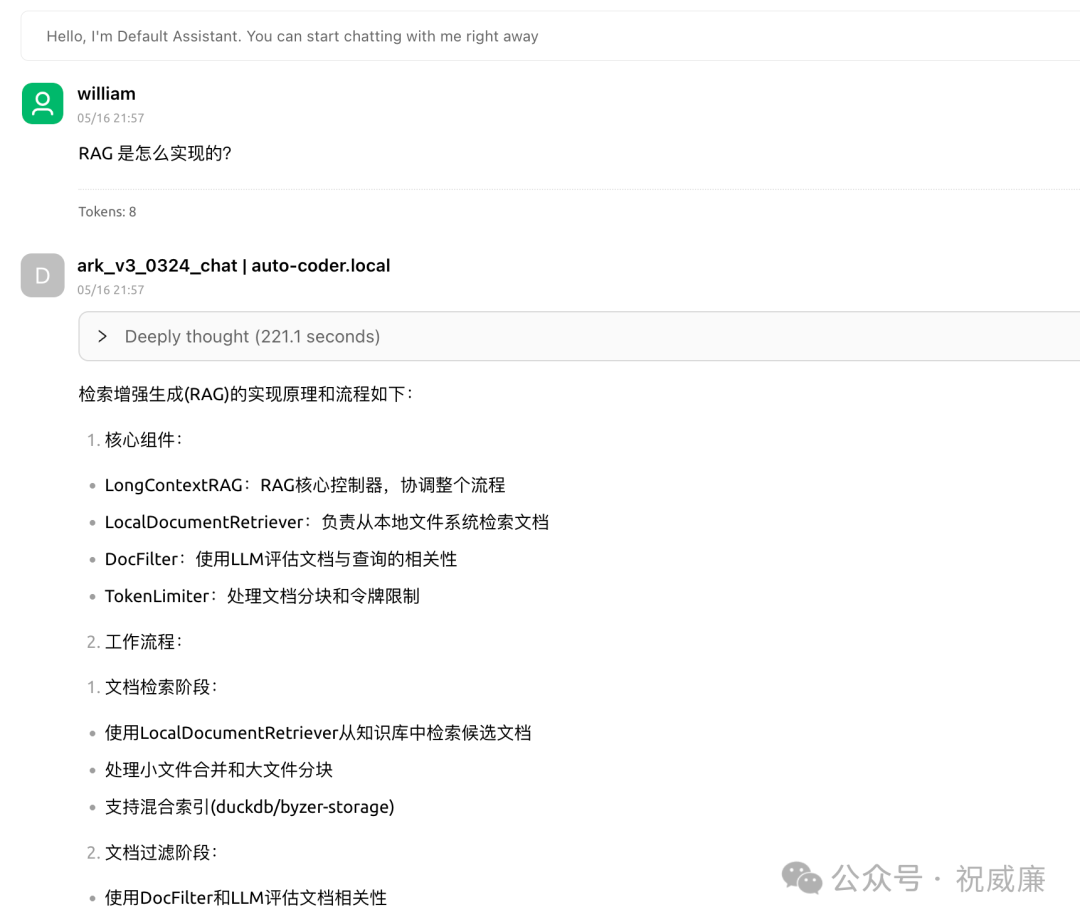
附带完整的回答,这个回答精准且简洁:
检索增强生成(RAG)的实现原理和流程如下:
1. 核心组件:- LongContextRAG:RAG核心控制器,协调整个流程- LocalDocumentRetriever:负责从本地文件系统检索文档- DocFilter:使用LLM评估文档与查询的相关性- TokenLimiter:处理文档分块和令牌限制
2. 工作流程:1) 文档检索阶段:- 使用LocalDocumentRetriever从知识库中检索候选文档- 处理小文件合并和大文件分块- 支持混合索引(duckdb/byzer-storage)
2) 文档过滤阶段:- 使用DocFilter和LLM评估文档相关性- 多线程并行处理文档- 记录详细的性能指标(处理时间、令牌使用等)
3) 答案生成阶段:- 使用TokenLimiter对文档进行智能分块- 将相关文档内容作为上下文输入LLM- 生成最终回答并记录完整流程统计信息
3. 关键技术点:- 动态分块:根据token限制自动调整文档分块大小- 混合索引:支持本地文件系统和向量数据库混合检索- 性能优化:多线程处理、缓存机制- 可观测性:详细的日志和性能统计
4. 代码结构:- 主入口:LongContextRAG类- 文档检索:document_retriever.py- 文档过滤:doc_filter.py- 令牌限制:token_limiter.py- 相关工具:recall_tool.py/search_tool.py
5. 配置参数:- rag_context_window_limit:上下文窗口大小- rag_doc_filter_relevance:文档相关度阈值- index_filter_workers:过滤线程数- rag_storage_type:存储类型(duckdb/byzer-storage)再给大家看看“Deeply thought 部分”,实际上是auto-coder.RAG 内部的 agentic 思维以及工具调用链情况:
<thinking>1. 用户询问RAG(检索增强生成)的实现原理2. 我需要从知识库中检索与RAG实现相关的文档内容3. 首先使用召回工具获取相关文档片段4. 根据召回结果决定是否需要进一步深入阅读特定文件</thinking>🛠️ 操作: RecallToolUnknown tool type: RecallToolData: { "query": "RAG 实现原理 检索增强生成", "file_paths": null}[bold]状态:[/bold] 成功[bold]消息:[/bold] 成功召回 3 个相关文档片段[ { "path": "Merged_26_docs_286f1ac9-8583-4030-b53c-9231cffaa02e", "content": "#File: ##File: /Users/allwefantasy/proj...orage_type: Optional[str] = \"duckdb\" # 向量化存储类型 byzer-storage | duckdb\n rag_params_max_tokens: Optional[int] = 500000 \n rag_doc_filter_relevance: Optional[int] = 2\n rag_context_window_limit: Optional[int] = 120000\n rag_duckdb_vector_dim: Optional[int] = 1024 # DuckDB 向量化存储的维度\n rag_duckdb_query_similarity: Optional[float] = 0.1 # DuckDB 向量化检索 相似度 阈值\n rag_duckdb_query_top_k: Optional[int] = 10000 # DuckDB 向量化检索 返回 TopK个结果(且大于相似度)\n rag_index_build_workers: Optional[int] = 10\n rag_emb_dim: Optional[int] = 1024\n rag_emb_text_size: Optional[int] = 1024\n rag_qa_conversation_strategy: Optional[str] = \"multi_round\"\n\n verify_file_relevance_score: int = 6\n enable_rag_search: Optional[Union[bool, str]] = False\n enable_rag_context: Optional[Union[bool, str]] = False\n collection: Optional[str] = None\n\n enable_multi_round_generate: Optional[bool] = False\n\n monitor_mode: bool = False\n enable_hybrid_index: bool = False" }]<thinking>1. 从召回结果中可以看到多个与RAG实现相关的代码文件和文档片段2. 主要涉及的文件包括: - demo_rag_agent.py:展示了RAG工具的使用 - demo_recall_tool.py:专门测试RecallTool的实现 - RAGFactory相关代码:RAG服务的核心实现3. 需要进一步深入分析这些文件以获取RAG的具体实现细节4. 首先读取demo_rag_agent.py文件,了解RAG的基本使用方式</thinking>🛠️ 操作: ReadFileToolAutoCoder 想要读取此文件:[bold cyan]examples/demo_rag_agent.py[/][bold]状态:[/bold] 成功[bold]消息:[/bold] Successfully read file: examples/demo_rag_agent.py"""演示 LongContextRAG 工具的使用展示如何在 BaseAgent 中使用 SearchTool 和 RecallTool"""import osimport argparseimport shutilfrom loguru import loggerimport byzerllm# 解析命令行参数def parse_args(): parser = argparse.ArgumentParser(description="演示 LongContextRAG 工具的使用") parser.add_argument("--model", type=str, default="v3_chat", help="使用的LLM模型") parser.add_argument("--product_mode", type=str, default="lite", help="产品模式") parser.add_argument("--event_file", ty...件路径等) - 优先使用知识库中的信息,避免生成可能不准确的内容 - 当知识库中没有足够信息时,我会坦诚告知用户,并提供基于已有信息的最佳建议 - 提供有条理、易于理解的回答,必要时使用代码示例、列表或表格增强可读性 ''')
# 8. 演示使用SearchTool logger.info("开始演示SearchTool的使用...")
# search_query = "请使用搜索工具查找与文件监控相关的代码文件:"# search_request = AgentRequest(user_input=f"""# {search_query}# <search># <query>文件监控系统实现</query># <max_files>3</max_files># </search># """)
# logger.info(f"用户输入: {search_query}")# logger.info("运行Agent...")# rag_demo_agent.run_in_terminal(search_request)
# 9. 演示使用RecallTool# logger.info("开始演示RecallTool的使用...")
recall_query = "找到系统里工具获取与文件监控相关的代码内容" recall_request = AgentRequest(user_input=f"""{recall_query}""")
logger.info(f"用户输入: {recall_query}") logger.info("运行Agent...") rag_demo_agent.run_in_terminal(recall_request)
# 10. 清理环境 logger.info(f"演示完成,保留演示环境以供检查: {source_dir}") logger.info("如需清理环境,请手动删除该目录")if __name__ == "__main__": main()<thinking>1. 从demo_rag_agent.py文件中可以看到RAG的核心实现是通过LongContextRAG类完成的2. 需要进一步查看LongContextRAG类的实现细节3. 根据文件中的导入路径,LongContextRAG类位于autocoder.rag.long_context_rag模块4. 需要读取该模块的源代码以了解RAG的具体实现</thinking>🛠️ 操作: ReadFileToolAutoCoder 想要读取此文件:[bold cyan]src/autocoder/rag/long_context_rag.py[/][bold]状态:[/bold] 成功[bold]消息:[/bold] Successfully read file: src/autocoder/rag/long_context_rag.pyimport jsonimport osimport timefrom typing import Any, Dict, Generator, List, Optional, Tupleimport pathspecfrom byzerllm import ByzerLLMfrom loguru import loggerfrom openai import OpenAIimport statisticsimport traceback.... """估算当前请求的令牌成本(人民币)""" # 实际应用中,可以根据不同模型设置不同价格 input_cost_per_1m = 2.0/1000000 # 每百万输入令牌的成本 output_cost_per_1m = 8.0/100000 # 每百万输出令牌的成本 cost = (input_tokens * input_cost_per_1m / 1000000) + \ (output_tokens * output_cost_per_1m/1000000) return cost<thinking>1. 从long_context_rag.py文件中可以看到RAG的核心实现逻辑2. RAG主要分为三个阶段: - 文档检索阶段:使用LLM模型从知识库中检索相关文档 - 文档分块阶段:对检索到的文档进行分块和重排序 - 答案生成阶段:基于检索到的文档内容生成最终回答3. 需要进一步了解文档检索和分块的具体实现细节4. 根据文件中的导入路径,文档检索由LocalDocumentRetriever类实现5. 需要查看LocalDocumentRetriever类的实现</thinking>🛠️ 操作: ReadFileToolAutoCoder 想要读取此文件:[bold cyan]src/autocoder/rag/document_retriever.py[/][bold]状态:[/bold] 成功[bold]消息:[/bold] Successfully read file: src/autocoder/rag/document_retriever.pyimport threadingfrom typing import Dict, Generator, List, Tuple, Any, Optional,Unionfrom byzerllm import ByzerLLM, SimpleByzerLLMfrom loguru import loggerfrom autocoder.common import SourceCodefrom uuid import uuid4from abc import ABC, abstractmethodfrom autocoder.rag.cache.simple_cache import AutoCoderRAGAsyncUpdateQueuefrom autocoder.rag.cache.file_monitor_cache import AutoCoderRAGDocListenerfrom autocoder.rag.cache.byzer_storage_cache import ByzerStorageCachefrom autocoder.rag.cache.local_byzer_storage_cache import LocalByzerStorageCachefrom autocoder.rag.cache.local_duckdb_storage_cache import LocalDuckDBStorageCachefrom autocoder.common import AutoCoderArgscache_lock = threading.Lock()class BaseDocumentRetriever(ABC): """Abstract base class for document retrieval.""" @abstractmethod def get_cache(self, options: Optional[Dict[str, Any]] = None): """Get cached documents.""" pass @abstractmethod def retrieve_documents( se...ule_name=chunk_name, source_code=chunk_content, tokens=chunk_tokens, metadata={ "original_doc": doc.module_name, "chunk_index": i // chunk_size + 1, }, )... remaining_tokens -= chunk_tokens chunk_number += 1<thinking>1. 从document_retriever.py文件中可以看到文档检索的具体实现2. LocalDocumentRetriever类负责从本地文件系统检索文档3. 主要功能包括: - 处理小文件合并 - 处理大文件分块 - 支持混合索引4. 需要进一步了解文档过滤的实现细节5. 根据long_context_rag.py中的引用,文档过滤由DocFilter类实现6. 需要查看DocFilter类的实现</thinking>🛠️ 操作: ReadFileToolAutoCoder 想要读取此文件:[bold cyan]src/autocoder/rag/doc_filter.py[/][bold]状态:[/bold] 成功[bold]消息:[/bold] Successfully read file: src/autocoder/rag/doc_filter.pyimport timefrom typing import List, Dict, Optional, Generator, Tupleimport byzerllm@byzerllm.prompt()def _check_relevance_with_conversation( conversations: List[Dict[str, str]], documents: List[str], filter_config: Optional[str] = None,) -> str: """ 使用以下文档和对话历史来回答问题。如果文档中没有相关信息,请说"我没有足够的信息来回答这个问题"。 文档: .....<thinking>1. 从doc_filter.py文件中可以看到文档过滤的具体实现2. DocFilter类使用LLM模型评估文档与查询的相关性3. 主要功能包括: - 多线程处理文档过滤 - 计算文档相关度分数 - 记录详细的性能统计信息4. 现在我们已经收集了RAG实现的关键组件信息5. 可以开始整理RAG的实现原理和流程</thinking>可以看到,agentic 会自动改写query并且进行使用llm-native 召回工具进行召回,然后根据召回结果重新查看相关文件,最终得到结果。
适用场景
Agnetic + LLM-Native 范式存在速度较慢,token消耗进一步增大,更适合高价值场景或者允许较长时间才能得到结果的情况。而单纯的 LLM-Native 则可同时给人或者程序调用。
最后详细使用教程在这里: https://uelng8wukz.feishu.cn/wiki/NfrVwutGDiDm9qkiFgSc60zRnNc?fromScene=spaceOverview
或者点击原文链接。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









