




大模型的迭代速度快得像风暴。你会明显感觉到一个变化——模型越来越不像“被训练出的静态产物”,而更像“会自己进化的生物系统”。
尤其是从 DeepSeek-R1、A2A(Answer-to-Answer)、以及 Self-Rewarding(自监督奖励) 这几个关键方向开始,2025 的大模型路线正在出现一个新的技术断层:
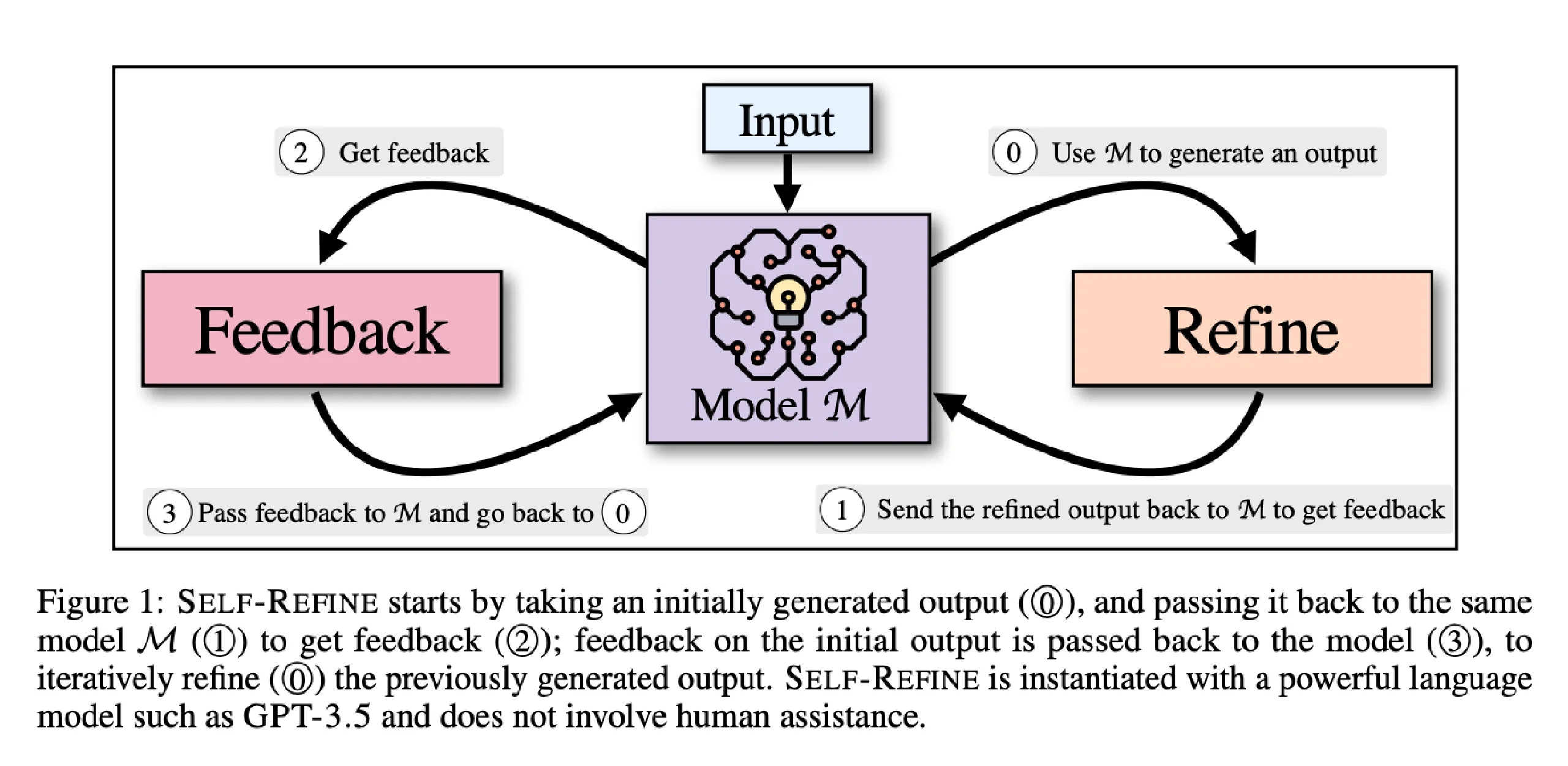
模型不再依赖人类给“标准答案”做微调,而开始学会自己判断、自己纠偏、自己优化。
这是一个巨大的范式转折,也正是本文想带你深入理解的主题。
在这篇文章里,我不希望堆知识点,也不希望一上来就甩术语;我希望你能顺着我的叙事,真正“看到”这些技术的内在逻辑,看到它们为什么出现、它们真正解决了什么痛点、以及它们如何向“自治模型”(Self-Improving Models)迈进。
在你继续往下读之前,想象一个真实的问题——
假如你今天训练一个模型写代码,谁来告诉它写得好不好?
如果答案仍然是“标注员”或“人工反馈”,那你就落后了。
因为 R1、A2A 和 Self-Rewarding 正是在做一件事:
教模型自己当“老师”。
1. 为什么自进化模型会在 2025 突然爆发?
其实这并不突然。背后的因果链非常清晰,而且几乎是行业无法避免的必然趋势。
过去的大模型训练高度依赖人类标注:
SFT(监督微调) → RLHF(人类反馈强化学习) → RLAIF(AI 反馈 RL)
这套模式有三个痛点:
-
标注成本极高
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









