




1. 算法光环下的“脏活累活”?
在人工智能的聚光灯下,我们习惯于谈论 Transformer 的架构创新、谈论千亿参数的涌现能力。但如果你深入过任何一个真实的计算机视觉(CV)落地项目,你会发现一个残酷的真相:决定模型生死的,往往不是你用了 YOLOv8 还是 v10,而是你的标注数据质量。
行业里流传着一句老话:“Garbage In, Garbage Out”(垃圾进,垃圾出)。但在实际工程中,这句话应该被改写为:“Gold In, God Out”。
很多开发者在刚入行时,觉得标注就是“画框框”,是低端的重复劳动。然而,当自动驾驶汽车在暴雨中需要识别一个模糊的行人,或者医疗 AI 需要在 CT 影像中勾勒出微小的肿瘤边界时,标注的每一像素偏差,都可能决定系统的上限。 视觉标注,早已从单纯的人力堆叠,进化为了一门融合了认知科学、几何学与工程管理的精密艺术。
2. 从矩形框到像素级语义:标注的进化阶梯
视觉标注的本质,是将人类对物理世界的理解,翻译成机器能读懂的数学语言。这个翻译过程,随着 AI 能力的提升,变得越来越精细。
最基础的是图像分类(Classification),给图片打个标签(如“猫”)。但这远远不够。
进阶是目标检测(Object Detection),我们需要画出边界框(Bounding Box)。这看起来简单,但充满了歧义:被遮挡了一半的汽车,框要画多大?只画露出来的部分,还是脑补出整体?不同的定义,训练出的模型行为截然不同。
再往上是语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。这时候,矩形框不够用了,我们需要用多边形(Polygon)甚至像素掩码(Mask)来精确描绘物体轮廓。这就像是从“画草图”变成了“精细素描”。
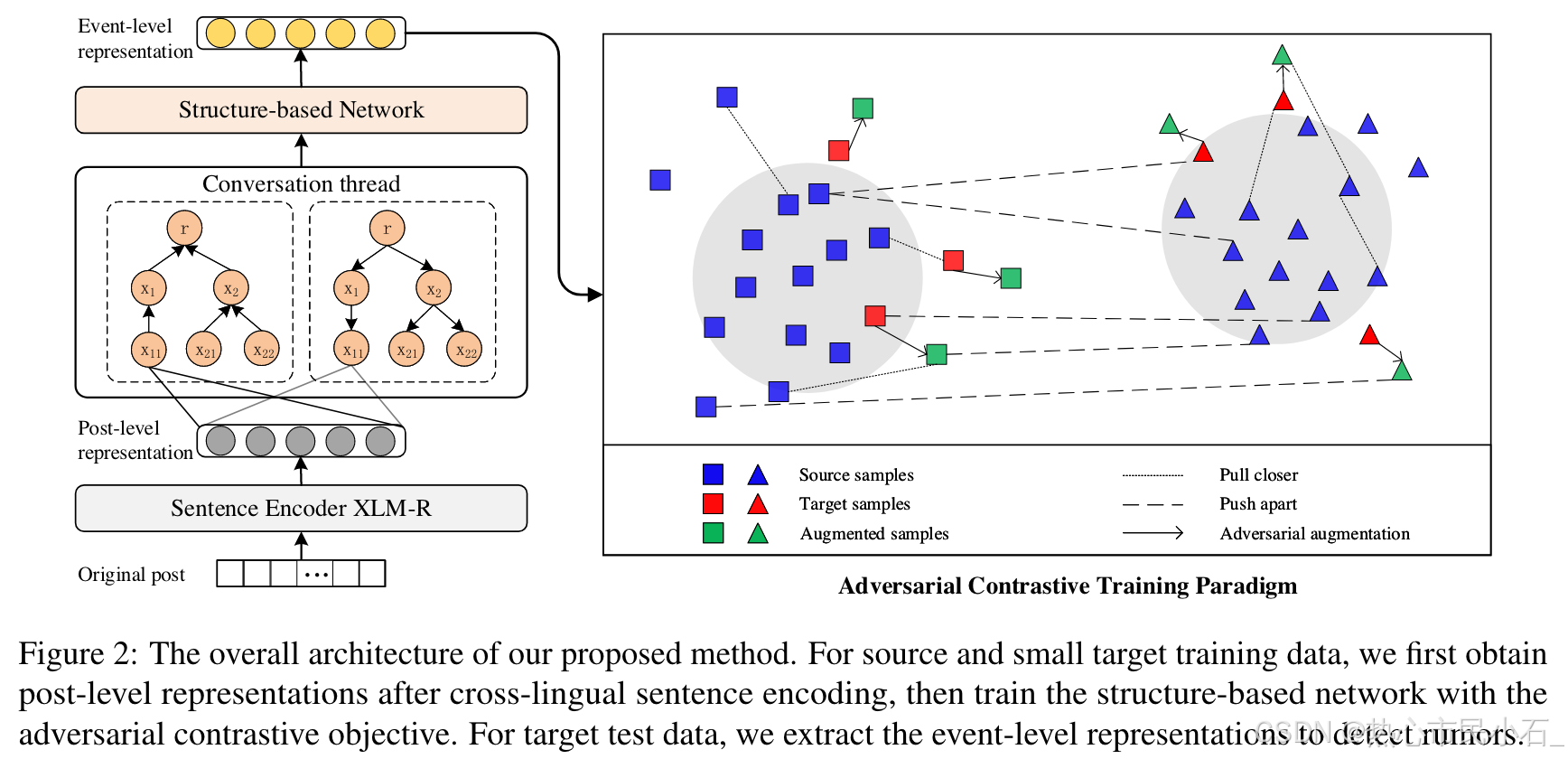
而现在,随着具身智能和自动驾驶的兴起,我们进入了 3D 标注时代。点云(Point Cloud)标注需要在三维空间中通过旋转、缩放来框选物体,难度呈指数级上升。
在这个过程中,“人机耦合”(Human-in-the-loop)成为了主流。我们不再完全依赖纯手工,而是利用 SAM(Segment Anything Model)这样的预训练大模型进行预标注,人类只需要进行微调和审核。这彻底改变了标注的工作流。
3. 动手实践:手写一个 YOLO 格式可视化工具
在实际开发中,我们经常拿到一堆 .txt 的 YOLO 格式标签文件,心里却没底:这些框画得对不对?坐标有没有归一化错误?
最直接的验证方法,就是写一段代码,把标签“画”回原图上。这不仅是验证,更是理解坐标系转换的最好练习。
环境配置
我们需要 OpenCV 来处理图像和绘图。
pip install opencv-python numpy
核心代码:YOLO 坐标反算与绘制
YOLO 格式的核心在于它使用的是归一化坐标(0~1 之间),格式为 class_id x_center y_center width height。我们需要将其还原为像素坐标。
import cv2
import numpy as np
import os
def visualize_yolo_labels(image_path, label_path, class_names=None):
"""
读取图片和 YOLO 格式的标签,并将边界框画在图片上。
"""
# 1. 读取图片
img = cv2.imread(image_path)
if img is None:
print(f"错误:无法读取图片 {image_path}")
return
h, w, _ = img.shape
print(f"图片尺寸: 宽={w}, 高={h}")
# 2. 读取标签文件
if not os.path.exists(label_path):
print(f"错误:找不到标签文件 {label_path}")
return
with open(label_path, 'r') as f:
lines = f.readlines()
# 3. 解析并绘制每一个框
for line in lines:
parts = line.strip().split()
if len(parts) != 5:
continue
class_id = int(parts[0])
# YOLO 格式:x_center, y_center, width, height (全部归一化到 0-1)
x_center_norm = float(parts[1])
y_center_norm = float(parts[2])
width_norm = float(parts[3])
height_norm = float(parts[4])
# 4. 坐标转换:归一化 -> 像素坐标
# 计算框的中心点像素坐标
cx = int(x_center_norm * w)
cy = int(y_center_norm * h)
# 计算框的像素宽高
bw = int(width_norm * w)
bh = int(height_norm * h)
# 计算左上角坐标 (x_min, y_min)
x_min = int(cx - bw / 2)
y_min = int(cy - bh / 2)
x_max = int(cx + bw / 2)
y_max = int(cy + bh / 2)
# 5. 绘图
# 画矩形框 (颜色 BGR: 绿色)
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), (0, 255, 0), 2)
# 添加类别标签文本
label_text = f"Class {class_id}"
if class_names and class_id < len(class_names):
label_text = class_names[class_id]
cv2.putText(img, label_text, (x_min, y_min - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 6. 显示结果 (在服务器环境通常保存为文件)
output_filename = "visualized_result.jpg"
cv2.imwrite(output_filename, img)
print(f"可视化结果已保存为: {output_filename}")
# 如果在本地运行,可以取消注释下面两行来直接显示窗口
# cv2.imshow("YOLO Visualization", img)
# cv2.waitKey(0)
# --- 模拟运行 ---
# 为了演示,我们生成一个假的图片和标签文件
def create_dummy_data():
# 创建一个黑色背景图
dummy_img = np.zeros((400, 400, 3), dtype=np.uint8)
cv2.imwrite("test_image.jpg", dummy_img)
# 创建一个 YOLO 标签文件
# 假设类别 0 是 "Car",位于图片中心,占据一半大小
# 格式: 0 0.5 0.5 0.5 0.5
with open("test_image.txt", "w") as f:
f.write("0 0.5 0.5 0.5 0.5\n")
# 再加一个小物体在左上角
f.write("1 0.2 0.2 0.1 0.1\n")
create_dummy_data()
visualize_yolo_labels("test_image.jpg", "test_image.txt", class_names=["Car", "Person"])
扩展思考
当你运行这段代码,你会直观地看到“归一化”的威力。无论图片怎么缩放,只要相对位置不变,YOLO 的标签数值就不变。这也是为什么 YOLO 格式在多尺度训练中如此受欢迎的原因。
4. 结语:从“以模型为中心”到“以数据为中心”
吴恩达(Andrew Ng)近年来一直在呼吁 Data-Centric AI(以数据为中心的 AI)。他认为,现在的模型架构已经足够成熟,与其花几个月去微调模型参数提升 0.1% 的精度,不如花几天时间清洗和修正标注数据,往往能带来 10% 的提升。
视觉标注,正在从一项劳动密集型工作,转变为一项知识密集型工作。未来的 AI 工程师,可能一半的时间不是在写代码,而是在设计“如何教机器看世界”的课程大纲(标注策略)。
如果说代码是 AI 的骨架,那么标注数据就是 AI 的灵魂。
如果你也在被“脏数据”折磨,或者对自动化标注流程有独到的见解,欢迎在评论区分享你的“填坑”经历。


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









