




——提示词时代结束了,真正的竞争在“谁能为模型构建结构化思维环境”
过去两年,AI 社区有一个明显的认知偏差:大家把“写提示词”当成能力,把“提示词技巧”当成个人竞争力。但随着 Agent、工具调用、多模态、长上下文、RAG、流程编排一起发展,我们越来越清楚地看到:
提示词不是终点,它只是上下文工程(Context Engineering)的一个子集。
真正提升模型表现的,不是你写的那几十个字,而是你给模型建造的“上下文生态”。
你可以把 LLM 想象成一名极其聪明,却对世界一无所知的“瞬时思考体”。它既不记得过去,也不知道未来,甚至不知道你的业务逻辑。
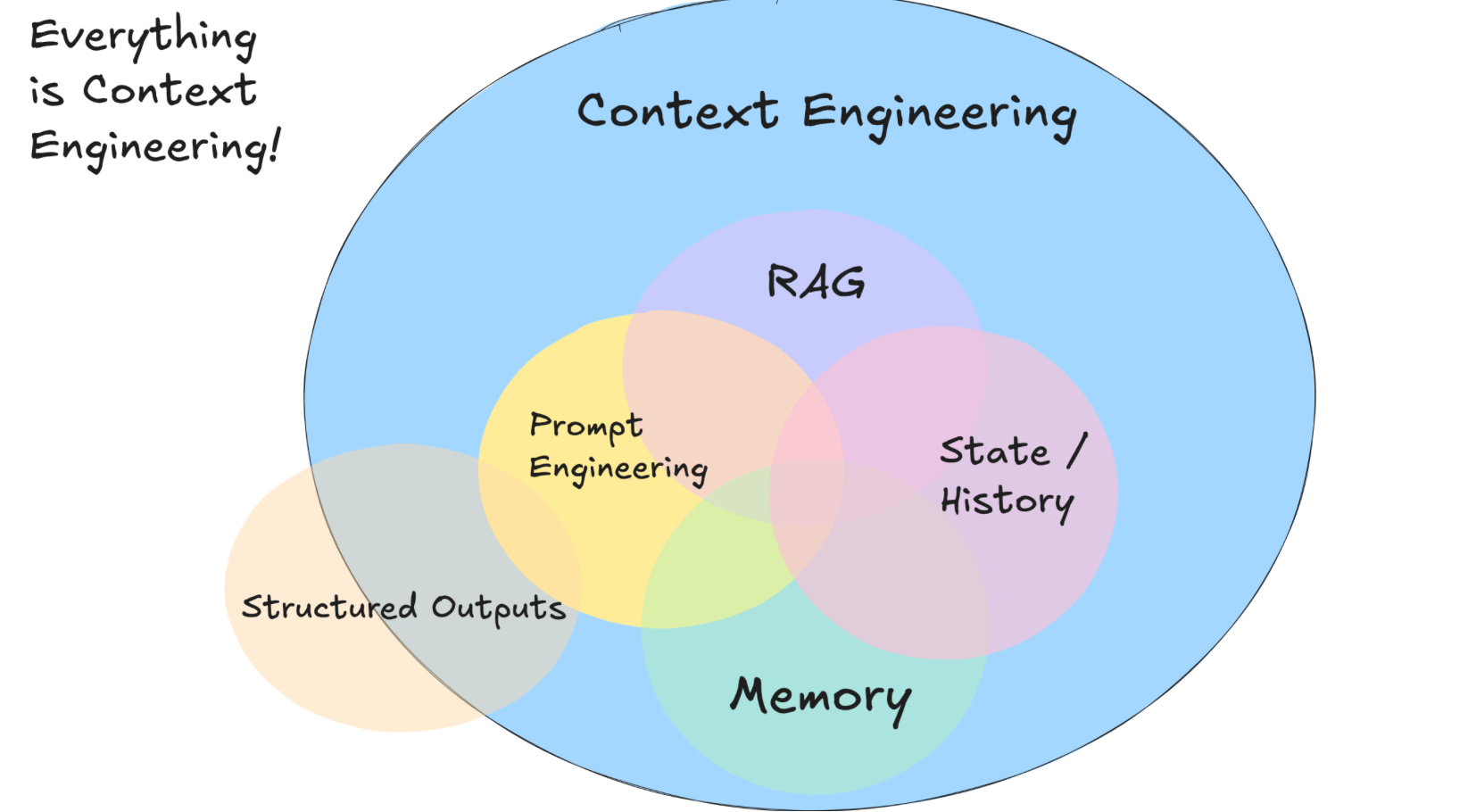
模型唯一能依赖的,就是你在推理时给予它的那一段上下文。
这意味着:
-
想让模型更准确?提供更好的上下文。
-
想让模型更稳定?提供结构化上下文。
-
想让模型更像一个智能体?让上下文动态演化。
于是,一个新的方向出现了:
Context Engineering(精密上下文工程)。
它不是提示词技巧,而是一种系统方法论。
它是未来 AI 应用的“编排层”“智能体层”真正核心。
它让模型从“输入-输出”走向“有状态的推理流程”。
这篇文章会带你看懂:
-
精密上下文工程是什么
-
为什么它比 Prompt Engineering 更重要
-
它的底层逻辑
-
它如何在 Agent、工具调用和业务场景中落地
-
如何动手构建一个“动态上下文管线”
读完之后,你会真正理解:
世界上没有强模型,只有强上下文。
一、为什么提示词工程会快速失效?
提示词工程的问题很简单:
-
靠手工经验
-
靠技巧,不靠结构
-
模型版本一换,全部失效
-
只能处理静态输入
-
无法表达复杂意图
-
无法适应真实业务的动态变化
它更像 UI 设计,而不是系统设计。
你有没有发现,真正的智能产品不会让你写一大串提示词:
-
GPTs 背后是“系统提示 + 动态上下文 + 工具调用”
-
LangCha

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









