




过去几年,很多开发者都有同一个感受:大模型变强了,但我们似乎越来越看不懂它们。尤其是在多模态任务中,“为什么模型能同时理解图像、文字和语音?”、“不同模态之间的信息是怎么融合的?”、“这些能力靠堆算力还是靠结构创新?”——类似的问题在社区里反复出现。
这种困惑不是偶然——多模态模型确实走到了一个分水岭,而 原生全模态(Native Omni-Modal) 的思路,更像是一场架构范式的重构。
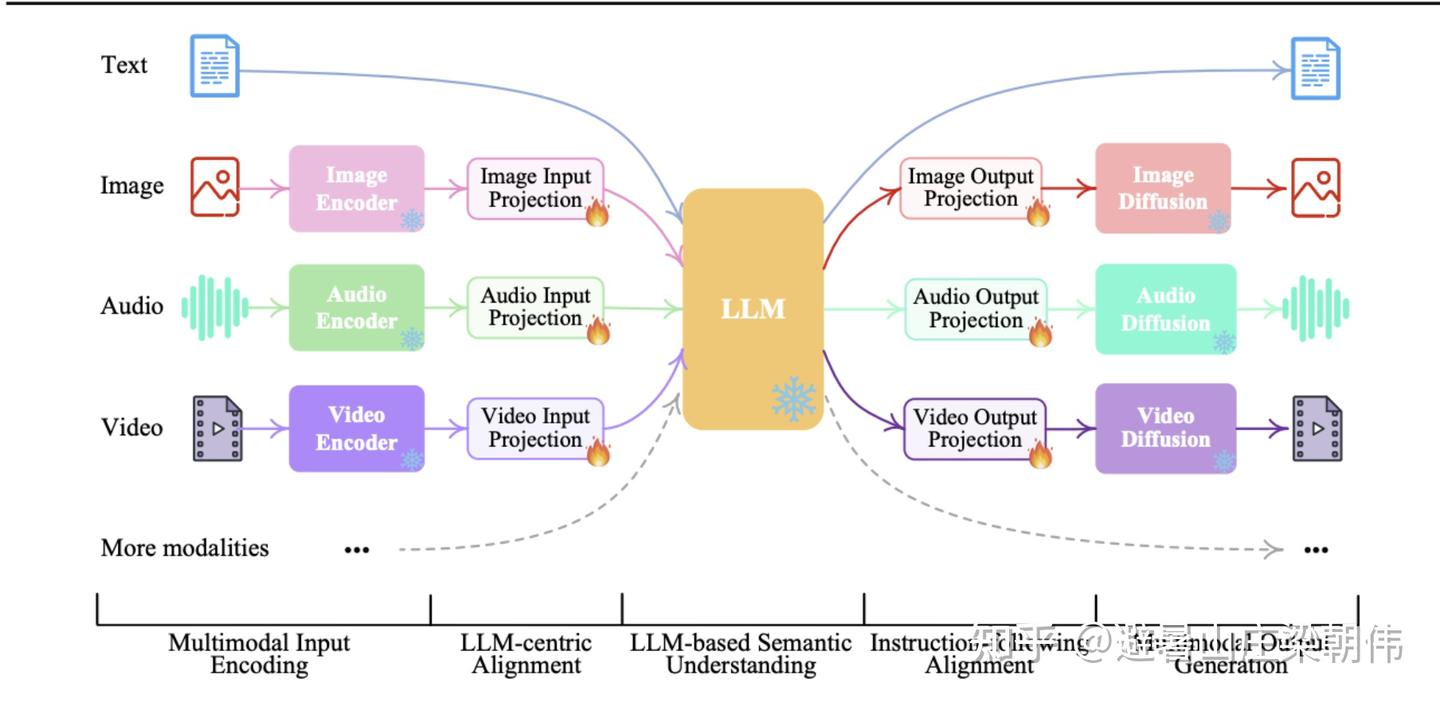
今天,我们不讲概念堆叠,也不贴大段代码,而是想把这条复杂技术演进路径,讲成你能“看懂、记住、讲得清”的一篇文章。读完之后,你应该能把多模态模型的底层结构,在脑子里形成一个清晰、可视化的统一图。
一、从“模态孤岛”开始:为什么过去的多模态总感觉拼凑?
如果要理解原生全模态,我们必须回到最初的架构语境。
在很长一段时间里,AI 世界的模态都是“各自为政”的:
-
图像模型学的是像素世界
-
文本模型学的是语义世界
-
语音模型学的是频谱世界
-
视频模型则是时序与帧间关系
这些领域各有自己的数据格式、损失函数、网络结构与训练习惯。于是,我们就得到了 AI 历史上最常见的多模态架构拼法:
把各模态模型输出的 embedding 取出来,再做一次后期融合(late-fusion)。
这就像你把来自不同国家的人拉到一个会议室里,大家语言不通,只能靠翻译凑合着沟通。能合作,但效率极低。其结果是:
-
信息损失是必然的:不同模态的表达从一开始就没有对齐。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 913
913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









