




1. 背景与研究动因
近年来,大模型的发展已经从“堆算力 + 扩数据”的范式,逐步进入“如何低成本高效率训练”的阶段。OpenAI、Anthropic 等公司主打 RLHF(人类反馈强化学习),通过人类标注者提供奖励信号,引导模型优化输出。但问题在于:
-
人力成本高:需要成千上万的标注者,训练周期长。
-
反馈尺度有限:人类无法覆盖全部复杂任务,尤其是推理链条场景。
-
扩展性不足:依赖外部数据与人类标签,使得模型无法实现真正的“自主进化”。
DeepSeek 提出的 自我博弈(Self-Play)训练范式,正是为了解决这一瓶颈。它的核心思想是:让模型自己和自己对局,在内部生成训练数据,并通过自博弈产生奖励信号,从而减少人类依赖。
这种范式在 强化学习、博弈论、自动推理 等领域都有渊源。例如,AlphaGo 就是通过自我博弈超越人类棋手的。而 DeepSeek 将这一理念推广到 自然语言推理与大模型优化,具有更广泛的意义。
2. 自我博弈的基本原理
2.1 传统 RLHF 流程
传统 RLHF(Reinforcement Learning with Human Feedback)包含几个步骤:
-
预训练模型生成答案。
-
人类评估答案的好坏。
-
奖励模型(Reward Model)学习人类偏好。
-
策略模型通过强化学习更新参数。
这意味着训练效果很大程度依赖于 人类的主观判断。
2.2 DeepSeek 的自博弈范式
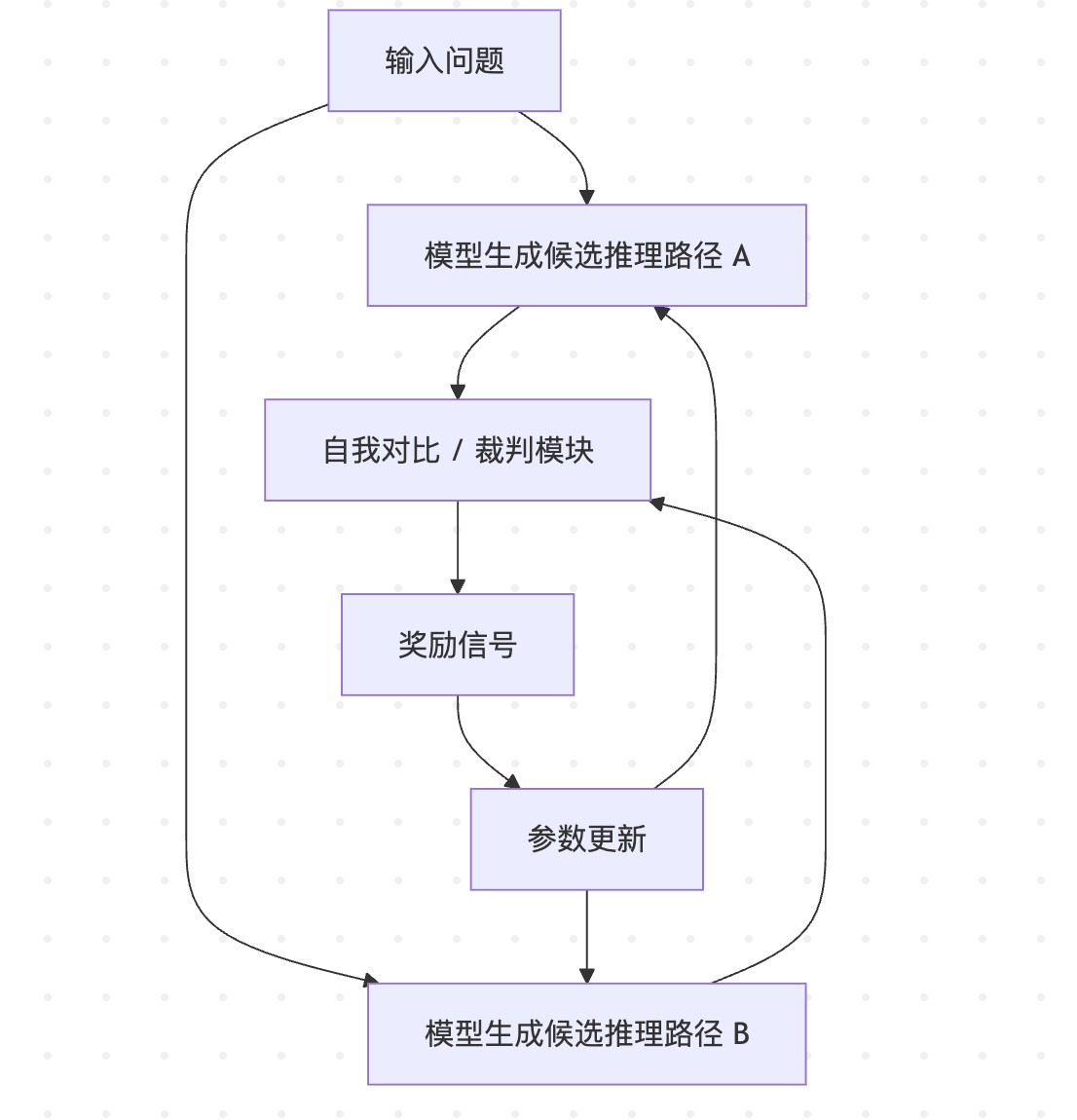
DeepSeek 用 模型-模型对局 替代了人类标注,形成一个闭环:
-
生成推理路径
模型在面对问题时,不仅输出答案,还会生成一个详细的推理链(Reasoning Path)。 -
自我对比 / 自我对局
模型会生成多个候选推理路径,并进行对局。例如,路径 A 与路径 B 进行对比,看哪条更符合逻辑、哪条更简洁。 -
奖励信号生成
通过一致性检验(比如逻辑自洽、数学验证、知识匹配),模型自己给出奖励分数,而不是依赖人工。 -
参数更新
模型基于奖励信号更新策略,强化更优的推理路径。
这就像一个棋手,不断和自己下棋、复盘,并通过自动裁判机制给出胜负,逐渐提升水平。
2.3 技术特点
-
自动化奖励:减少对人类标注的依赖。
-
动态数据生成:模型不断产生新的博弈数据,避免过拟合现有语料。
-
闭环优化:形成“生成 → 对局 → 奖励 → 更新”的闭环,像一个自驱动的学习引擎。
下面用一段伪代码示意:
class SelfPlayTrainer:
def __init__(self, model, reward_fn):
self.model = model
self.reward_fn = reward_fn
def play_round(self, question):
# 模型生成两个候选推理路径
path_a = self.model.generate(question, strategy="path_a")
path_b = self.model.generate(question, strategy="path_b")
# 模型自己裁判:谁更合理?
reward_a = self.reward_fn(path_a, question)
reward_b = self.reward_fn(path_b, question)
# 更新模型参数(强化学习)
self.model.update([path_a, path_b], [reward_a, reward_b])
return path_a, path_b, reward_a, reward_b
在实际系统中,DeepSeek 还会引入 对称对局、多样性控制、奖励对抗网络 等机制,让博弈更具挑战性。
3. 自我博弈的实践与应用
3.1 数学推理任务
以 GSM8K 或 MATH 数据集为例,传统 RLHF 需要人工判断推理链条是否合理。但在自我博弈中:
-
模型 A 输出推理链,得到结果 X。
-
模型 B 走另一条链,得到结果 Y。
-
如果结果不同,则通过“数学验证器”判定谁正确。
-
正确的一方获得奖励,错误的一方被惩罚。
这就像两个学生解同一道题,最后把答案带入去验证,自动生成胜负。
def math_reward_fn(path, question):
result = evaluate_math(path)
if check_answer(result, question.correct_answer):
return 1.0
else:
return -1.0
3.2 语言推理与写作任务
在开放式问答、写作场景中,人类偏好很难量化。DeepSeek 的方法是:
-
让多个推理路径相互批判。
-
使用“逻辑一致性 + 内容覆盖度 + 风格规范”作为奖励指标。
-
通过模型内部对比,得到奖励信号。
这类似于论文写作的 双盲评审:作者提交稿件,审稿人(模型自己)互相打分,逐步提升质量。
3.3 图示:自我博弈闭环
4. 与传统方法的对比
| 特点 | RLHF | DeepSeek 自我博弈 |
|---|---|---|
| 依赖 | 大量人工标注 | 模型内部对局 |
| 成本 | 高 | 低 |
| 可扩展性 | 有限 | 高 |
| 奖励信号 | 主观偏好 | 逻辑/一致性/验证 |
| 代表性应用 | GPT-4、Claude | DeepSeek R1 |
可以看到,自我博弈不是完全替代 RLHF,而是对其的 升级与扩展。在人类标注难以覆盖的领域,自我博弈尤其有效。
5. 代码实战:构建一个迷你自博弈训练器
下面给出一个简化版的实验,用 Python 模拟自我博弈:
import random
class MiniModel:
def generate(self, question, strategy="A"):
if strategy == "A":
return f"Answer_A with reasoning for {question}"
else:
return f"Answer_B with reasoning for {question}"
def update(self, paths, rewards):
# 简化版更新逻辑
print("Updating model with:", list(zip(paths, rewards)))
def reward_fn(path, question):
# 随机奖励,模拟一致性判定
return random.choice([1, -1])
model = MiniModel()
trainer = SelfPlayTrainer(model, reward_fn)
for i in range(5):
qa, qb, ra, rb = trainer.play_round("2+2=?")
print(f"Round {i+1}: A={ra}, B={rb}")
运行后,你会看到模型 A 和 B 在不断进行“对局”,并根据奖励信号更新。这是 DeepSeek 自博弈的极简缩影。
6. 局限与挑战
-
奖励设计困难
如果奖励函数不科学,模型可能学到“投机取巧”的模式,而非真正的推理能力。 -
模式坍塌风险
如果博弈双方过于相似,容易陷入“自嗨循环”,生成的数据缺乏多样性。 -
与人类价值对齐
自我博弈能提升推理,但在人类价值观层面,仍可能需要 RLHF 或 RLAIF(AI Feedback)补充。
7. 总结与展望
DeepSeek 的 自我博弈范式,可以看作是大模型从“外部监督学习”向“内部驱动进化”迈出的关键一步。它不仅降低了成本,还打开了 自动生成高质量训练数据 的大门。
未来我们可能看到:
-
多模型生态博弈:不同模型之间互相切磋,而非仅限于自我对局。
-
混合奖励机制:结合人类反馈、AI 反馈、符号验证器,实现更稳健的优化。
-
跨模态博弈:语言模型与视觉模型在多模态任务上进行自博弈,推动通用智能。
DeepSeek 正在尝试的,是一种“模型自进化”的道路。它让我们看到,大模型不再仅仅依赖人类,而是逐渐具备了 自我改进的能力。



















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









