




文章目录

0. 摘要
准确的估计噪声信息对于语音应用中的噪声感知训练至关重要。为了估计仅有噪声的帧,本文应用voice activity detection(VAD),通过对语音后验应用最佳阈值来检测非语音帧。这些帧用于提取噪声embedding,命名为动态噪声嵌入(dynamic noise embedding,DNE),这对于SE模块捕获背景噪声的特性非常重要。我们使用一个单独的神经网络提取DNE,SE模块和DNE可以联合训练。本文实验部分使用TIMIT数据集,使用U-Net作为SE模块的骨干网络。实验结果表明,DNE在SE模块中发挥重要作用,即使噪声信号是非平稳的,且是训练集中未曾出现的噪声信号,SE网络也能很好的提升语音信号的质量和可理解性。
1. 简介
本文提出了一种基于深度学习的方法处理单通道降噪任务,该方法同事使用VAD和SE模块。在模型中,首先使用VAD估计噪声信息,然后在SE模块中进行噪声感知训练。在带噪语音信号中,非语音帧仅仅包含噪声成分,VAD方法用于判别这些信号。这些非语音帧可用于提供有关噪声特征的信息,通过将它们与语音后验一起使用,简单的神经网络提取噪声自适应嵌入,这称为动态噪声嵌入 (DNE)。 DNE 附加到 SE 模块的输入声学特征中,以提高在嘈杂环境中的鲁棒性。
在本文提出的模型中,VAD和SE进行联合训练优化,因此不需要对VAD和SE模块进行单独的预训练。
2. Proposed method
带噪信号的时频域表示为:
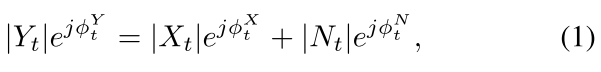
简化为幅度表示:
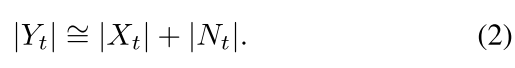
针对每一帧的情况,可以细分为带噪帧和仅有噪声的帧:
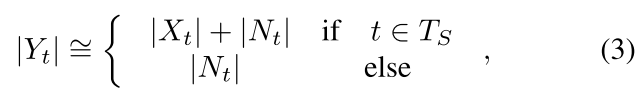
2.1 Estimating confident noise frames
在之前的工作[6, 26, 27]中,噪声估计方法:对语音的开始到结束取平均计算。这种方法简单,但难以表示非平稳噪声的趋势。 此外,这些帧不能保证它们总是只有噪声的帧。
从(3)中可以看出,非语音帧可以帮助表示噪声信息。因此,本文使用基于LSTM的VAD方法对非语音帧进行准确估计。
为了检测非语音帧,我们首先获得语音后验,它是 VAD 的输出。 来自 VAD 模块的语音后验的数学表达式可以表示如下:
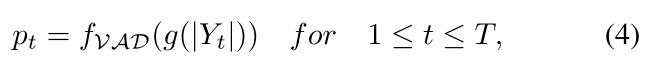
其中 p t p_t pt表示第t帧的语音后验,T表示语音的总帧数。函数g()将带噪语音信号转换为VAD的输入特征,例如梅尔频谱倒谱系数MFCCs或者梅尔滤波器
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











