




Which is the best LLM for prompting QML code (featuring DeepSeek v3)
哪种LLM是提示QML代码的最佳LLM(具有DeepSeek v3)
February 05, 2025 by Peter Schneider | Comments
2025年2月5日作者:彼得·施耐德|评论
Claude 3.5 Sonnet is the best LLM to write QML code when prompted in English. If you want to know why we reached this conclusion, keep reading.
Claude 3.5 Sonnet是在英文提示下编写QML代码的最佳LLM。如果想知道我们为什么得出这个结论,请继续阅读。
The QML100 Benchmark
QML100基准
Like the QML100FIM Benchmark we described in a previous blog post, we developed a benchmark for prompted code generation. These benchmarks help us guide our customers and adjust our fine-tuning work.
与我们在之前的博客文章中描述的QML100FIM基准一样,我们开发了一个用于提示代码生成的基准。这些基准帮助我们指导客户并调整我们的微调工作。
What tasks does the QML100 Benchmark contain?
QML100基准测试包含哪些任务?
The QML100 Benchmark contains 100 coding challenges in English, such as "Generate QML code for a button that indicates with a change of shadow around the button that it has been pressed.”
QML100基准测试包含100个英文编码挑战,例如“为按钮生成QML代码,通过按钮周围阴影的变化表示按钮已被按下。”
The first 50 tasks are focused on testing the breath of QML knowledge, covering tasks on most of the Qt Quick Controls. They include coding challenges for common components such as Buttons and less common controls such as MonthGrid.
前50个任务侧重于测试QML知识的广度,涵盖了Qt Quick控制的大部分任务。它们包括常见组件(如按钮)和不太常见的控件(如MonthGrid)的编码挑战。
The next 50 tasks cover typical UI framework applications such as "Create QML code for showing a tooltip when the user hovers with the mouse over a text input field.” or “Create QML code for a behavior of a smooth animation every time a rectangle's x position is changed.”
接下来的50个任务涵盖了典型的UI框架应用程序,例如“创建QML代码,用于在用户将鼠标悬停在文本输入字段上时显示工具提示。”或“创建QML代码,用于每次更改矩形的x位置时显示平滑动画的行为。”
How challenging are the QML 100 Benchmark tasks?
QML 100基准测试任务的挑战性有多大?
QML100 includes simple tasks that all LLMs complete successfully such as: “Generate QML code for a Hello World application. The Hello World text shall be displayed in the middle of the window on a light grey background.”
QML100包括所有LLM成功完成的简单任务,例如:“为Hello World应用程序生成QML代码。Hello World文本应显示在窗口中间的浅灰色背景上。”
QML100 also includes difficult tasks that all LLMs still fail, such as “Create QML code for a tree view displaying vegetables and things you can cook from them in their branch nodes. It shall be possible to expand and collapse branches through a mouse click.”
QML100还包括所有LLM仍然失败的困难任务,例如“为树视图创建QML代码,显示蔬菜和你可以在它们的分支节点中用它们烹饪的东西。应该可以通过鼠标点击来展开和折叠分支。”
The benchmark includes a few tasks that ask it to fix a bug in existing code or add code to enhance the existing code.
基准测试包括一些任务,要求它修复现有代码中的错误或添加代码以增强现有代码。
Image: LLM selection for Qt AI Assistant in Qt Creator
图:Qt Creator中Qt AI助手的LLM选择
Few tasks measure the knowledge of the in-built capabilities of a Qt Quick Control, such as "Create QML code for a checkbox which is set to status checked by a touch interaction from a user." Many LLMs tend to write code for all parts of the instructions, creating code that fails the above task. Adding a handler ´onClicked: checked =!checked ` to a CheckBox will render the UI control useless.
很少有任务衡量Qt Quick控件内置功能的知识,例如“为复选框创建QML代码,该复选框设置为通过用户的触摸交互进行状态检查。”许多LLM倾向于为指令的所有部分编写代码,创建的代码无法完成上述任务。添加处理程序´onClicked: checked =!checked `到复选框将使UI控件无效。
Not included are multi-file challenges requiring the LLM to read context from multiple files, tasks related to Qt Quick3D, Qt Multimedia, Qt Charts, Qt PDF, Qt Positioning, or any other similar tasks.
不包括要求LLM从多个文件读取上下文的多文件挑战、与Qt Quick3D、Qt多媒体、Qt图表、Qt PDF、Qt定位或任何其他类似任务相关的任务。
When is the generated QML code considered correct?
生成的QML代码何时被认为是正确的?
The generated code is manually checked to run in Qt Creator 15 with the Qt 6.8.1 kit. It must not contain run-time errors and must solve the task. Redundant import version numbers or unnecessary additional code do not lead to disqualification (as long as they work).
生成的代码被手动检查,以便在Qt Creator 15中使用Qt 6.8.1工具包运行。它不能包含运行时错误,并且必须解决任务。冗余的导入版本号或不必要的附加代码不会导致取消资格(只要它们有效)。
We prompt an LLM only once. We don't do "best out of three" or something like that. Considering the probabilistic nature of LLMs, we can assume that benchmark responses are never precisely the same repeated Hence, I wouldn't read too much into an LLM being 1% better or worse than the next one.
我们只提示LLM一次。我们不做“三选一”或类似的事情。考虑到LLM的概率性,我们可以假设基准响应永远不会完全相同。因此,我不会过多解读LLM比下一个好或坏1%。
Which LLMs were tested?
测试了哪些LLM?
New LLMs pop up like mushrooms after a rainy day. We have tested the majority of mainstream LLMs. We did test LLMs which are available as a commercial cloud service and some which can be self-hosted free of royalties.
雨天过后,新的LLM像蘑菇一样冒了出来。我们已经测试了大多数主流法学硕士。我们确实测试了LLM,它们可以作为商业云服务提供,有些可以免费自托管。
Which LLM generates the best code when prompted in English language?
哪种LLM在用英语提示时生成的代码最好?
The best royalty-free LLM for writing QML code is DeepSeek-V3, which has a score of 57% for successful code creation. The best overall LLM is Claude 3.5 Sonnet, with a success rate of 66%.
编写QML代码的最佳免版税LLM是DeepSeek-V3,其代码创建成功率为57%。最佳的是Claude 3.5 Sonnet,成功率为66%。
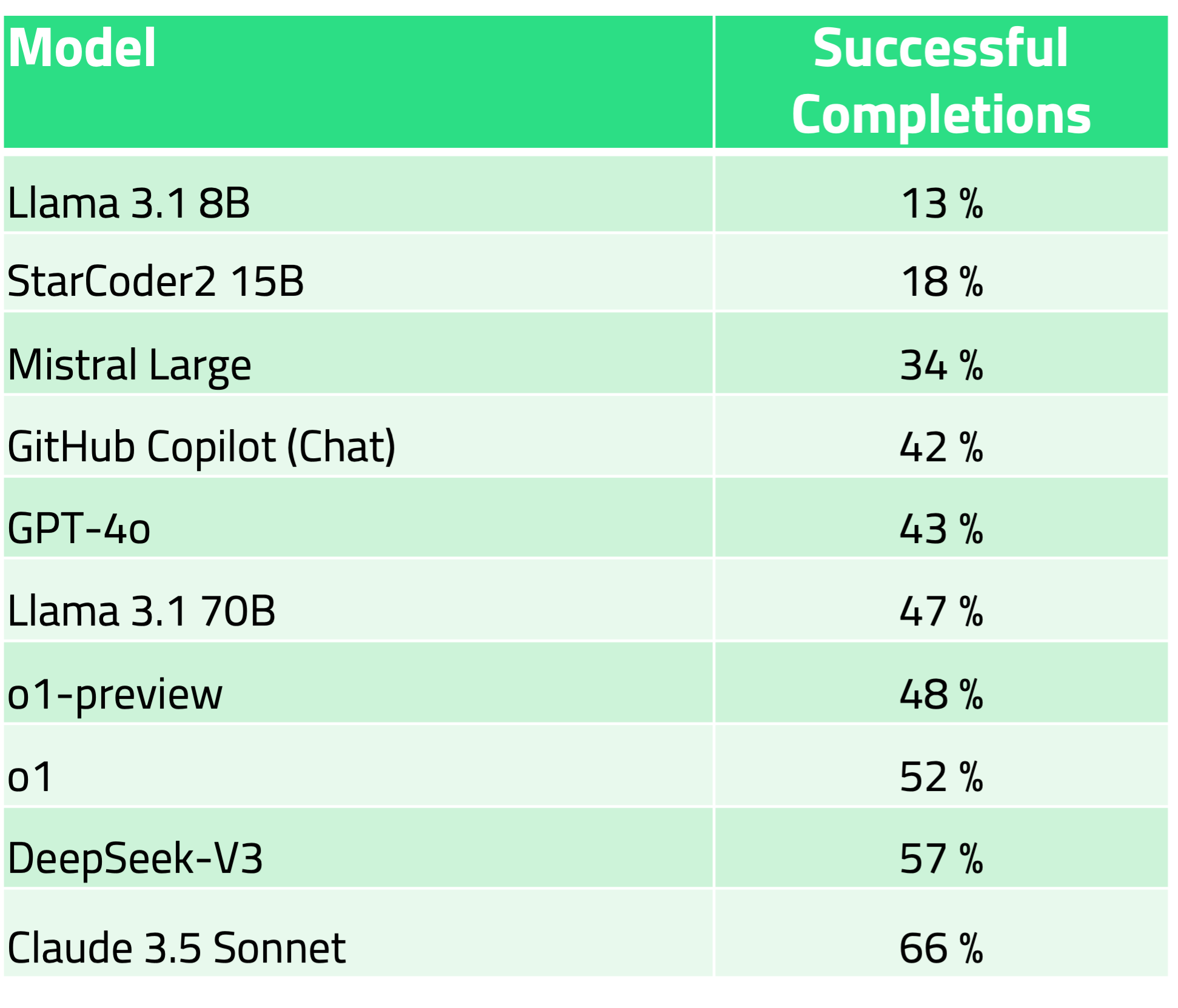
The performance of GitHub Copilot Chat in Visual Studio Code, which was 42% at the end of September 2024, is somewhat disappointing. We hope that this performance has improved by now. However, most of the results above are also from Q4 2024, and only DeekSeep-V3 and OpenAI o1 have been benchmarked this year. StarCoder2 and Mistral Large results are from Q2 2024.
GitHub Copilot Chat在Visual Studio Code中的性能在2024年9月底为42%,有点令人失望。我们希望到目前为止,这种表现已经有所改善。然而,上述大部分结果也来自2024年第四季度,今年只有DeekSeep-V3和OpenAI o1进行了基准测试。StarCoder2和Mistral Large的结果来自2024年第二季度。
The performance of StarCoder15B is a bit disappointing even when it has been trained on Qt documentation. However, we thought we should give it a try because it is the only model with transparent pre-training data.
即使经过Qt文档的训练,StarCoder15B的性能也有点令人失望。然而,我们认为我们应该尝试一下,因为它是唯一一个具有透明预训练数据的模型。
Overall, considering both code completion as well prompt-based code generation skills, Claude 3.5 Sonnet is a serious option to consider for individuals and customers if it comes down purely to QML coding skills. However, other aspects such as cost-efficiency, IPR protection, and pre-training data transparency should play a role in selecting the best LLM for your software creation project.
总体而言,考虑到代码完成和基于提示的代码生成技能,如果纯粹归结为QML编码技能,Claude 3.5 Sonnet是个人和客户值得考虑的重要选择。然而,在软件创建项目选择最佳LLM时,成本效益、知识产权保护和预培训数据透明度等其他方面也应发挥作用。
Qt AI Assistant supports multiple LLM
Qt AI助手支持多个LLM
Qt AI Assistant supports connections to Claude 3.5 Sonnet, Llama 3.3 70B, and GPT4o for prompt-based code generation and expert advice at the time of writing this blog post. If you want to know more about what the Qt AI Assistant can do for you, please visit our product pages.
Qt AI Assistant支持连接到Claude 3.5 Sonnet、Llama 3.3 70B和GPT4o,以便在撰写本文时进行基于提示的代码生成和专家建议。如果想了解更多关于Qt AI助手可以做什么的信息,请访问我们的产品页面。
If you need instructions on how to get started, please refer to our documentation.
如果需要有关如何开始的说明,请参阅我们的文档。


















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









