








基于多维卷积神经网络的视听关键字定位(2018)
摘要
音频和视频信息的融合是可靠的关键字定位(KWS)最有前途的解决方案之一,尤其是当音频被噪声破坏时。
KWS的目标是检测音频流中的特定单词,这在噪声环境下仍然是一个具有挑战性的问题。本文提出了一种基于多维卷积神经网络(MCNN)的视听神经网络来实现视听KWS。
首先,从音频和视频流中分别提取对数mel谱图和唇部区域序列,并将其作为音频-视频神经网络的输入。
然后,利用由二维CNN和三维CNN组成的基于MCNN的视听神经网络分别对对数mel谱图的时频特征和唇部区域序列的时空特征进行建模。
最后,通过决策融合将音频和视频网络的输出合并为KWS。在噪声学条件下的PKU-AV数据库上的实验结果表明,与其他最先进的方法相比,该方法具有更好的性能。
索引项——视听、关键词识别、多维神经网络、决策融合。
研究内容
本文提出了一种基于多维卷积神经网络(MCNN)的视听KWS方法。分别从音频和视频流中提取对数mel谱图和唇部区域序列作为音频和视频特征。
为了充分利用音频和视频特征中的各个维度信息,提出了一种基于MCNN的音频和视频神经网络模型,该模型由二维CNN和三维CNN组成。
二维CNN通过二维卷积运算同时学习对数谱图的时频特征。
同样,通过3D卷积运算,3D CNN被用来学习嘴唇区域序列的时间和空间特征。
最后,通过决策融合将音频和视频网络的输出结合起来,估计每个关键词的后验概率。在PKU-AV数据库上的实验结果表明,与其他常用方法相比,该方法具有更高的鲁棒性。
提出的方法&模型架构
视听神经网络
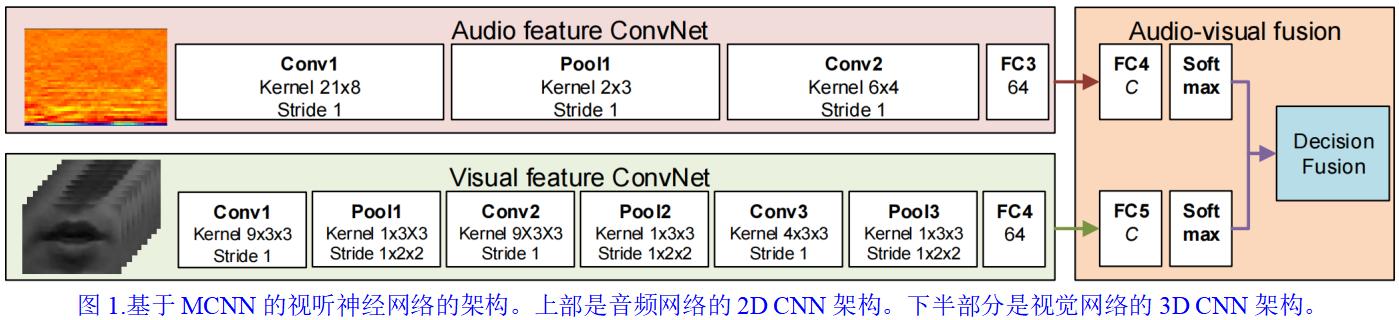
由多维卷积神经网络(MCNN)组成的视听神经网络的结构如图1所示。MCNN包括耦合的二维和三维CNN。对于音频和视频网络,除最后一层外,每个卷积层后面都有一个整流线性单元(ReLU)激活。
3.1. 音频网络
由于KWS的实时性要求,音频网络中的层数应尽可能少,以降低其计算复杂度,同时保持令人满意的KWS性能。为此,我们设计了一个音频网络,包括两个二维卷积层、一个二维最大池层和一个完全连接(FC)层。
如图1的上半部分所示,音频特征A首先被放入内核大小为21×8的2D卷积层。
然后,使用核大小为2×3的2D max池层来减少由说话风格、通道失真等引起的时频变化。池操作执行子采样以降低时频音频特征的维数。在池操作之后,使用一个内核大小为6×4的二维卷积层对音频特征进行加权。
最后,使用完全连接的层将前一层的输出压缩为64个输出单元。
在这个网络中,二维卷积层和池层的步长为1。不采用零填充,因为它会引入额外的虚拟零能量系数,这些系数在局部特征提取的意义上是没有意义的。在CNN层中使用非方核函数来学习有限层的更多时域信息。
3.2. 视觉网络
按照音频网络的类似原理,视频网络由三个3D卷积层、三个3D最大池层和一个完全连接层组成。
如图1下半部分所示,首先将视觉特征V放入一个内核大小为9×3×3的3D卷积层,然后使用一个内核大小为1×3×3的3D max池层来实现空间特征池。
接下来,同样的3D卷积和最大池操作再重复一次。
然后,应用核大小为4×3×3的三维卷积层和核大小为1×3×3的三维最大池层。最后,使用完全连接的层将前一层的输出压缩为64个输出单元。
在该网络中,执行3D卷积运算以发现时空唇部特征的相关性。三维卷积层的步长为1。为了提高对移动嘴唇效果的鲁棒性,3D max pooling层中的pooling Street设置为2,以在pooling内核附近保持嘴唇运动特征。
视听融合

数据集
我们实验中使用的数据集是我们自己收集的视听数据库,称为PKU-AV数据库。
PKU-AV数据库是在一个安静的声学环境中收集的,正常光照受控,由20名受试者(12名男性和8名女性)记录。在不遮挡口腔区域的条件下,每个人能说出300个汉语普通话,用摄像机以每秒20帧的速度记录,分辨率为640×480。相应的语音音频以16 kHz的采样频率同步记录,每个采样16位。我们定义了30个日常生活中常用的关键词/短语。在每个主题中,每个关键词有5个示例句子。因此,每个关键词有100个示例句,3000个否定示例句没有总结关键词。

















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









