




 该博客介绍了如何使用PyTorch实现Fashion-MNIST数据集上的softmax回归模型。首先,定义`load_data_fashion_mnist`函数加载数据,接着初始化网络权重,创建一个全连接层的softmax回归模型。然后,定义损失函数为交叉熵损失,选择优化算法为小批量随机梯度下降。训练过程中,通过`train_epoch_ch3`函数进行单个epoch的训练,并使用`evaluate_accuracy`计算测试集的精度。最后,调用`train_ch3`函数进行模型训练。遇到问题时,作者选择了使用PyTorch内置模块的简洁版本来替代手动实现。
该博客介绍了如何使用PyTorch实现Fashion-MNIST数据集上的softmax回归模型。首先,定义`load_data_fashion_mnist`函数加载数据,接着初始化网络权重,创建一个全连接层的softmax回归模型。然后,定义损失函数为交叉熵损失,选择优化算法为小批量随机梯度下降。训练过程中,通过`train_epoch_ch3`函数进行单个epoch的训练,并使用`evaluate_accuracy`计算测试集的精度。最后,调用`train_ch3`函数进行模型训练。遇到问题时,作者选择了使用PyTorch内置模块的简洁版本来替代手动实现。
1. 读取数据
# 读取并加载数据集,定义load_data_fashion_mnist函数
def load_data_fashion_mnist(batch_size, resize=None):
"""下载fashion-MNIST数据集,然后将其加载到内存中"""
# ToTensor操作
trans = [transforms.ToTensor()]
# 因为当前trans里面包含的图片tensor大小是28x28,到后面训练时需要更大一点的数组就用resize变大
if resize:
trans.insert(0, transforms.Resize(resize))
# 这个transforms.Compose()类的主要作用是串联多个图片变换的操作
trans = transforms.Compose(trans)
# 下载数据集
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans, download=False)
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans, download=False)
# 返回构造的迭代器对象
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=True,
num_workers=get_dataloader_workers()))
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
2. 初始化模型参数
softmax回归的输出层是一个全连接层。因此,为了实现我们的模型,我们只需在Sequential中添加一个带有10个输出的全连接层。
初始化权重
def init_weights(m):
if type(m) == torch.nn.Linear:
torch.nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights) #初始化网络模型权重
初始化网络
#softmax回归的输出是一个全连接层
#pytorch不会隐式地调整输入的形状
#因此,定义了展平层(flatten)在线性层前调整网络输入的形状
net = torch.nn.Sequential(torch.nn.Flatten(), torch.nn.Linear(784, 10))3. 定义损失函数(交叉熵损失函数)
#在交叉熵损失函数中传递未归一化的预测,并同时计算softmax及其对数
loss = torch.nn.CrossEntropyLoss()4. 选择优化算法(随即梯度下降)
# 使用学习率为0.1的小批量随即梯度下降作为优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)5. 评估网络模型准确率
# 分类准确性
def accuracy(y_hat, y):
"""计算预测正确的数量"""
if (len(y_hat.shape) > 1 and y_hat.shape[1] > 1): # len(y_hat.shape)输出为y_hat的行向量的个数
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
# 我们可以评估再任意模型net的准确率
def evaluate_accuracy(net, data_iter):
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module): # isinstance() 函数来判断一个对象是否是一个已知的类型
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 累加器,正确预测数metric[0]、预测总数metric[1]
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1] # 返回的是分类正确的样本数量/总样本数量
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
6. 训练
#单个epoch训练
def train_epoch_ch3(net, train_iter, loss, updater):
if isinstance(net, torch.nn.Module): # 如果是torch.nn.Module则开始训练
net.train();
metric = Accumulator(3) # 用长度为3的迭代器来累加loss,accuracy, y.numel
for X, y in train_iter: # 接下来扫一遍数据
y_hat = net(X) # 计算y_hat
l = loss(y_hat, y) # 通过交叉熵损失函数来计算l
if isinstance(updater, torch.optim.Optimizer): # 如果是pytorch的optimizer的话,就
updater.zero_grad() # 先把梯度置为零
l.backward() # 然后计算梯度
updater.step() # 更新参数
metric.add( # 累加loss,准确数,样本数
float(l) * len(y), accuracy(y_hat, y),
y.size().numel())
else: # 如果全部自己实现的话
l.sum().backward() # 则l是一个向量,计算梯度并求和
updater(X.shape[0]) # 更具批量大小更新参数
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel()) # 记录分类的损失和,准确数,样本数
return metric[0] / metric[2], metric[1] / metric[2] # 返回的是 loss/样本数 所有正确的样本/样本数
# 训练函数
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): # @save
"""训练模型"""
for epoch in range(num_epochs):
train_loss, train_acc= train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
print('epoch: %d, loss: %.4f, train_acc: %.3f, test_acc: %.3f' %(epoch+1, train_loss, train_acc, test_acc))
#调用之前定义的训练函数来训练模型
num_epochs = 10
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)7. 输出
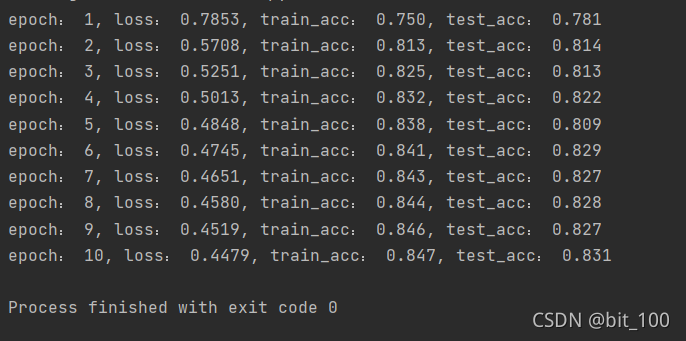
本来也跟着实现手写各个算法模块,但是可能某个地方写错了,loss表现的很奇怪,正确率也很低。就先实现调用torch.nn里面的各个模块的简洁版本了。
参考:
3.6. softmax回归的从零开始实现 — 动手学深度学习 2.0.0-alpha2 documentation (d2l.ai)

















 493
493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









