






 本文探讨了在Python的matplotlib库中使用pyplot进行循环绘图时,如何正确使用pyplot.close()避免图像叠加的问题。通过示例代码展示了在每次循环后关闭图像的重要性,确保每个训练集和测试集的图像独立呈现。
本文探讨了在Python的matplotlib库中使用pyplot进行循环绘图时,如何正确使用pyplot.close()避免图像叠加的问题。通过示例代码展示了在每次循环后关闭图像的重要性,确保每个训练集和测试集的图像独立呈现。
1、不关闭将会引起什么问题
在一个循环中,如果我们的目的是每一个循环都做一副图出来,如果做完一副图,没有使用pyplot.close(),就会使之前做过的图出现在下一副上,看下图: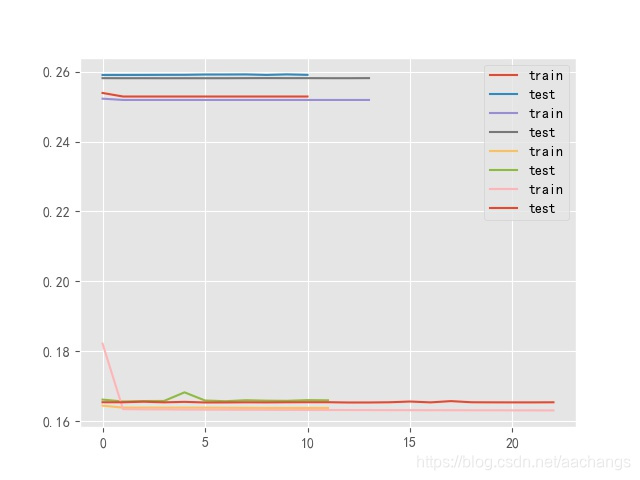
我们的目的
而如果你的目的是每一对train,test都做一张图,就要使用pyplot.close()每一次循环后关闭pyplot,即使在函数中也要这么做。改正后如下: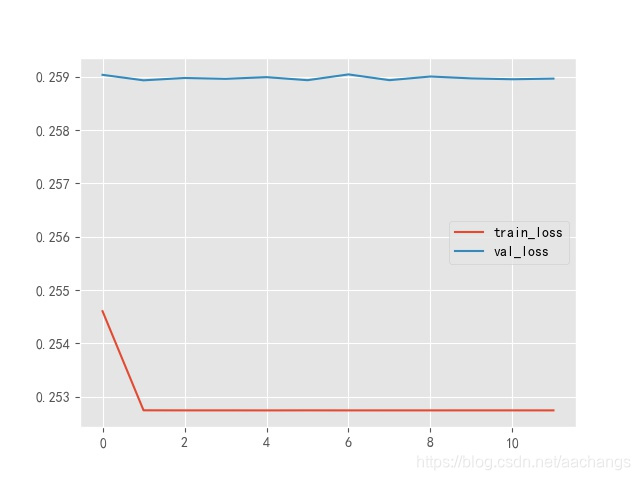
详细代码如下
plt.plot(history.history['loss'], label='train_loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.legend()
plt.savefig('fig_{}.jpg'.format(name))
plt.close() # 就是这里 一定要关闭

















 536
536





 到【灌水乐园】发言
到【灌水乐园】发言







