



(一)雪崩
1.什么是微服务雪崩:指微服务某一服务的生产者不能提供某一服务或者提供某一服务慢 使得消费者该服务堆积 耗尽消费者服务 资源耗尽 ,在此之后由于微服务之间以链式拓扑结构进行调用 每个消费者对应的若干个他们自己消费者就会收到影响 递归的耗尽自己的资源 几何式传递使接下来几乎所有微服务都不能使用
关于解决方案
根据上述 首先可以想到某一服务资源量不足 进而阻塞过度消耗 那让他不要影响别的进程即可这就是线程隔离
2.第二个服务熔断 1说的服务堆积 只要发生了消费问题 就控制输入的请求即可 走falback逻辑
3.在前两点基础上 降低峰值流量带来的瞬间爆炸 进行qps整形 用限流处理即可
分别对应于讲师归纳的下图:

4.运行sentinel.jar 导入依赖就能拉起sentinel服务了 这个东西监控的是接口调用情况 因此未发生调用时候只显示自己
访问接口后界面如下
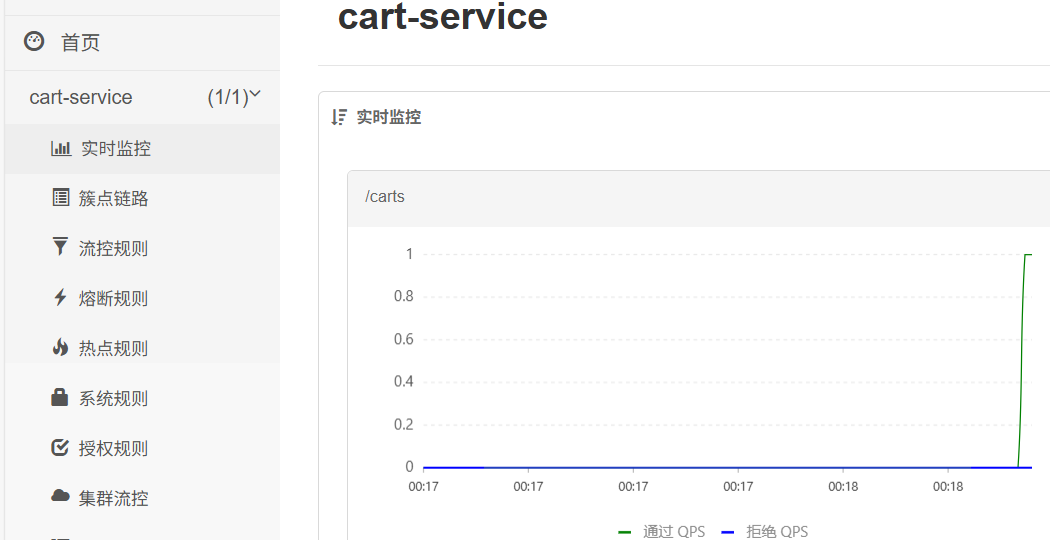
5 人话:sentinel会监控 controller调用接口 它对应的传输链路的并发量 但问题是这个路径相同时候没有区分具体接口
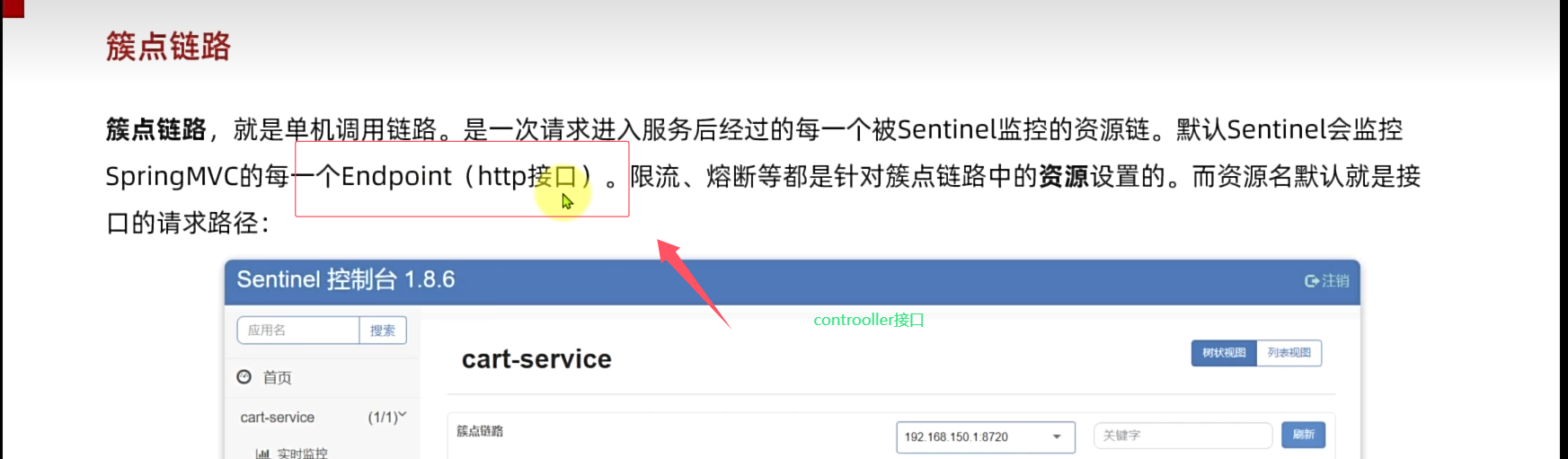
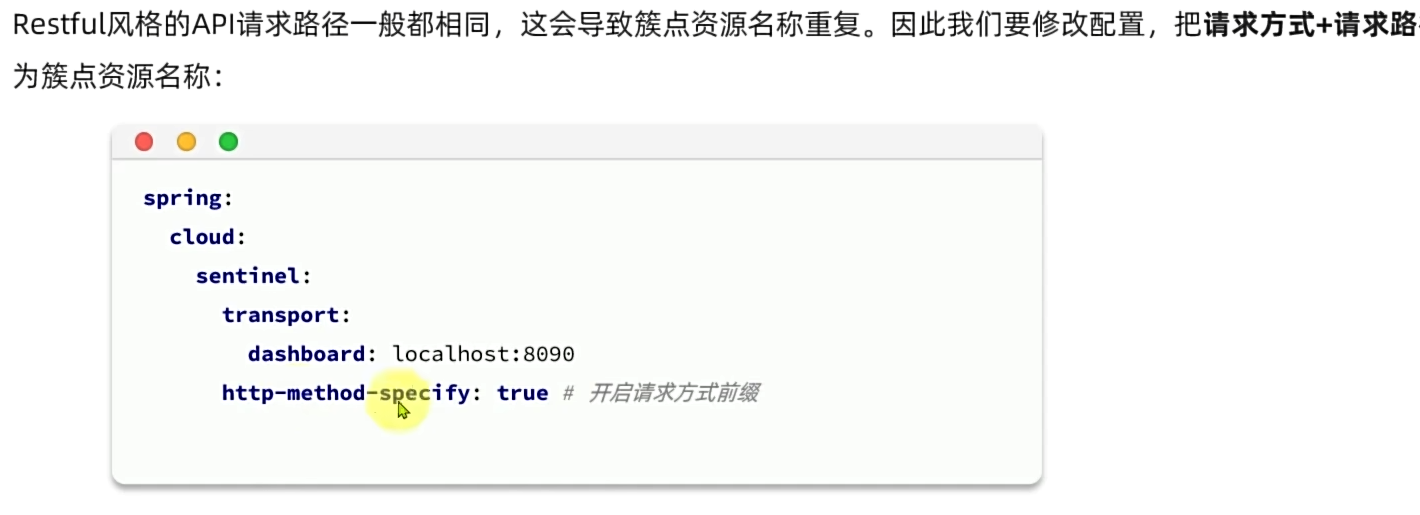
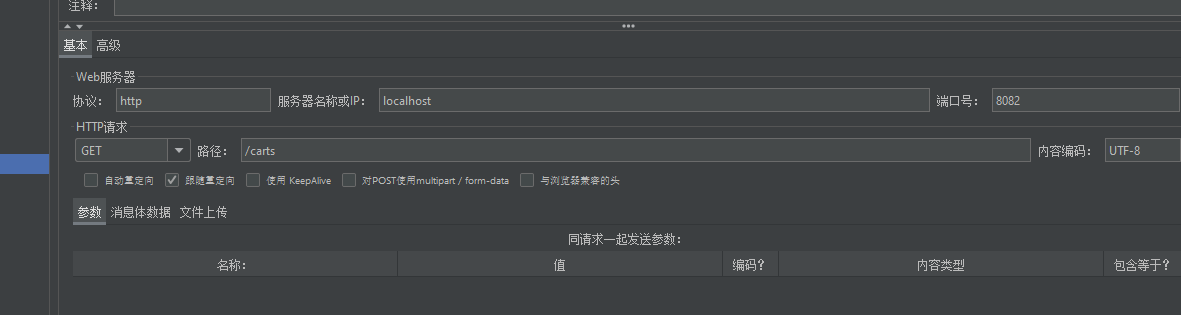
配置httpmodifyspecify属性
用jmeter打流进行性能测试 感觉这玩意很慢 429 errcode 是限流自己请求被限制的意思
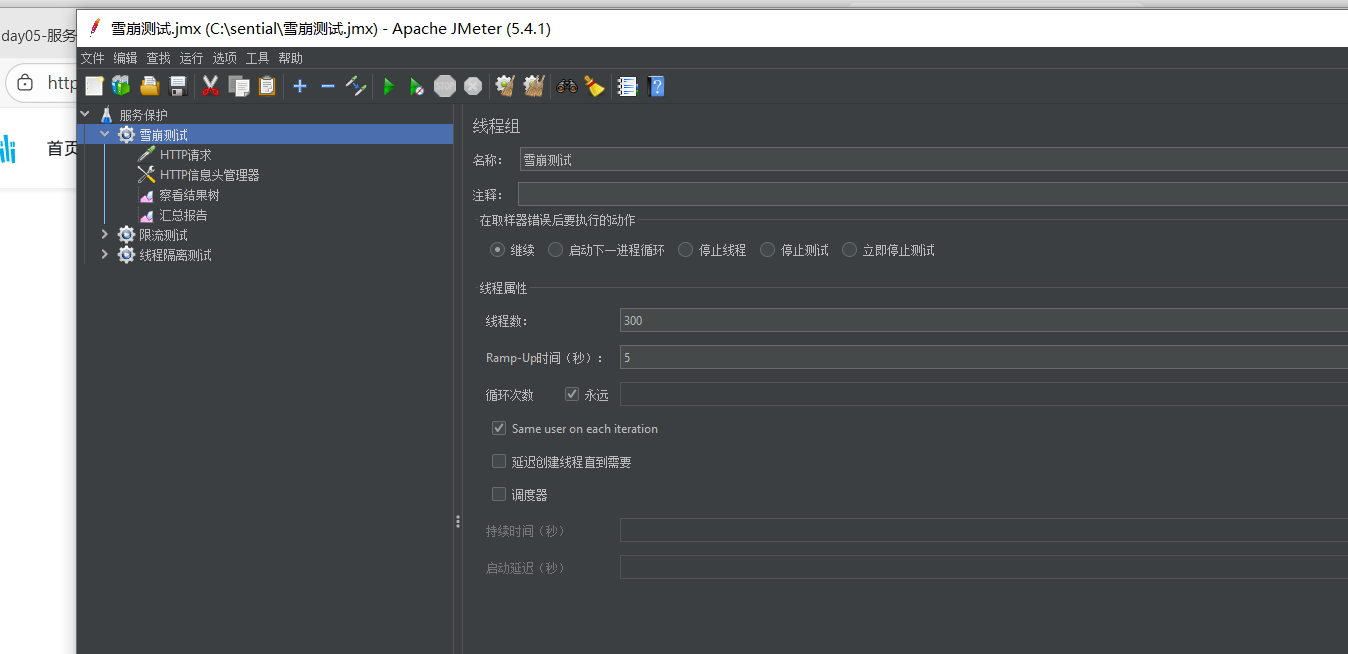
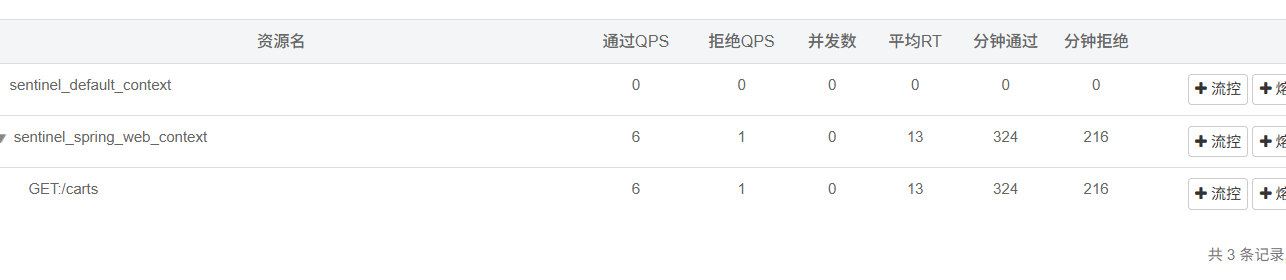
QPS = 并发线程数 * 单线程qps 也就是说线程隔离要防止的极端情况其实QPS是低的 反之亦然
同时限制这两个事 相当于整个雪崩的极大值极小值都被抹去了
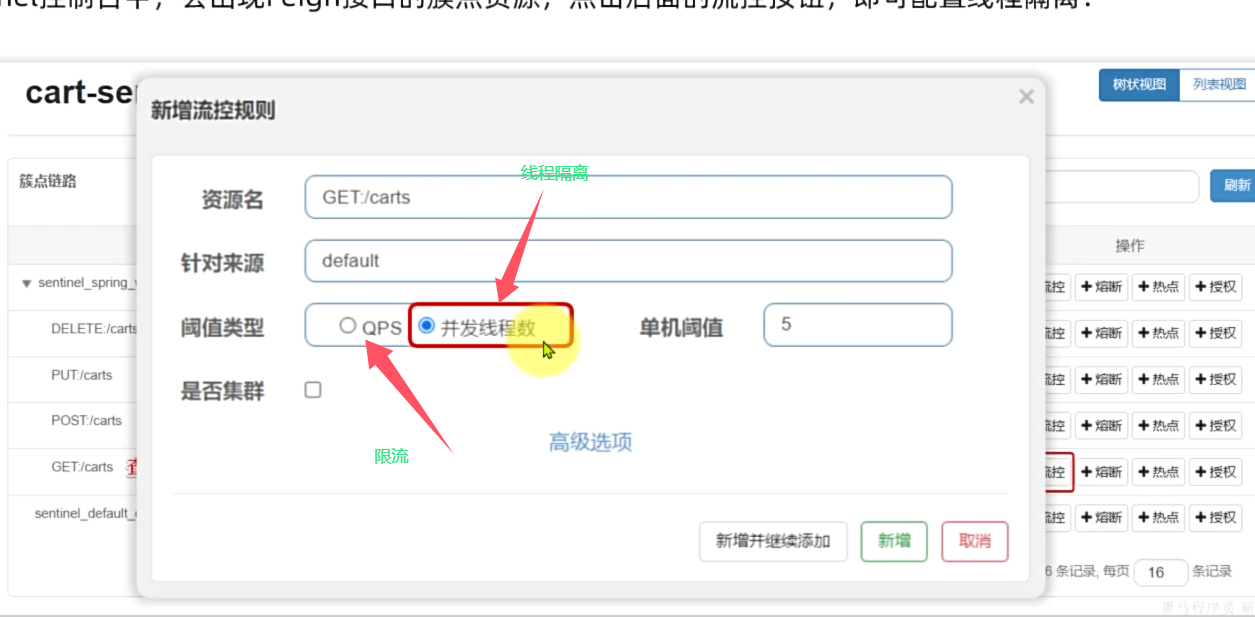
6.线程隔离测试 点击修改会显示查询失败 原因是修改生效了 只不过查询没法显示修改的效果
7.前面说的fallback逻辑 在这用上了 线程隔离相当于自断一臂保全大局 但是太过惨烈 用fallback修饰或者发一个普适性的结果 才明白feign调用不属于簇点链路资源 怪不得刚才打流都是针对于 服务本身而不是级联服务 甚至连网关都没走

通过别人造好的轮子 一个工厂方法来定义后备client实例 再想办法注册


这里fallback工厂对象要在配置类定义bean 因为配置类会被扫描 在那里面注册bean对应的组件才会被拉起 最后在对应的client Feign注解扫描fallback 工厂
8.配上这个 feigncvlient级联事务 会被加入簇点 也就是说对级联事务加留空 最后返回一个同样的结果 fallback 保证子簇点被阻断时候查询不会过度占用资源卡死
总结来说 限流针对某个服务本身 防止其链路传入过多的请求 线程隔离 阻断 高频服务子模块影响次数 避免影响其他服务 fallback 使得阻断的子模块不会返回异常结果影响界面
1.fallback要将feign打开 sentinel 针对级联限流 2.然后定义fallback逻辑 并放到 配置类注册3.对应的client配置fallback工厂类.class+
9.关于服务熔断 大概就是一个定时器定时放行检测耗资源率搞得线程并把它关掉返回fallback 也是在流控规则配的
(二)分布式事务
1.分布式事务大致是级联事务种中 同一层次的分支事务相互不能感知 导致有的事务成功了 有的事务没成功 要解决的方案就是用seta-tc去管理 分支事务与全局事务
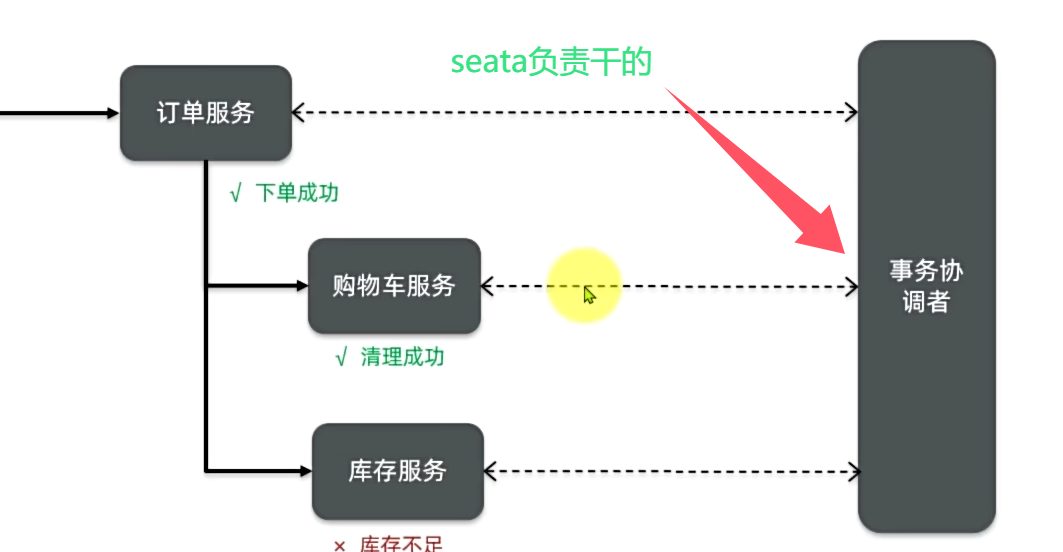
这玩意有tm,tc分别管理主干事务和分支事务 大概是说主干事务从函数入口到确认完各分支事务结束为一个主干周期 给TM配置入口出口配置 TM进行监控 监控到主干异常通知TC回滚所有分支事务 TM看不到分支事务 tc通过rm获取分支状态

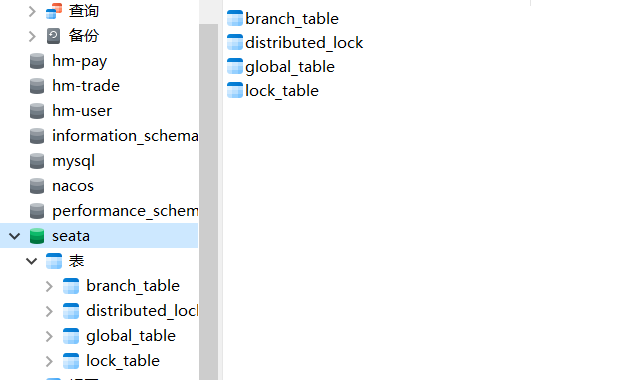
要搭建TC微服务 引入seata依赖 导入tc要基于来运行的sql数据和锁:
2.关于要配置的: seata这个东西本身跟n个微服务去相互通信 因此要用nacos负载均衡注册+feign访问
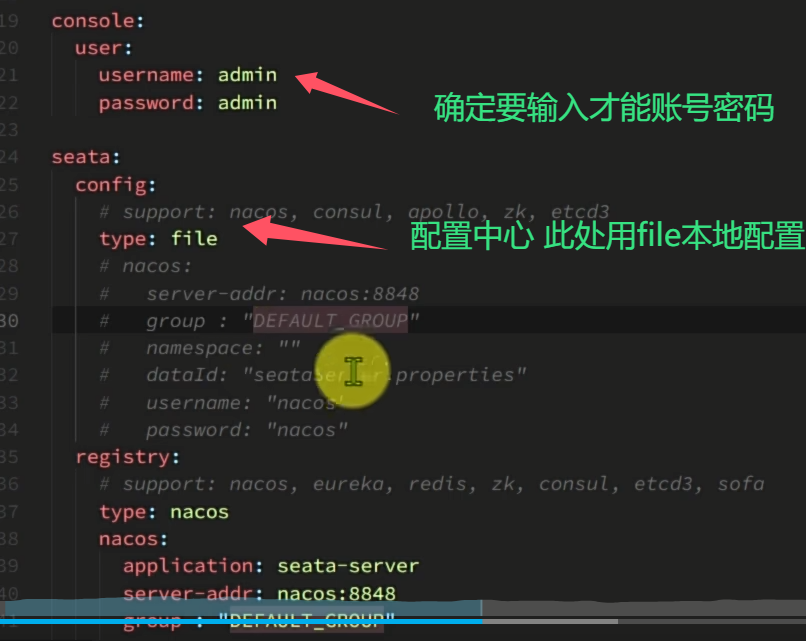
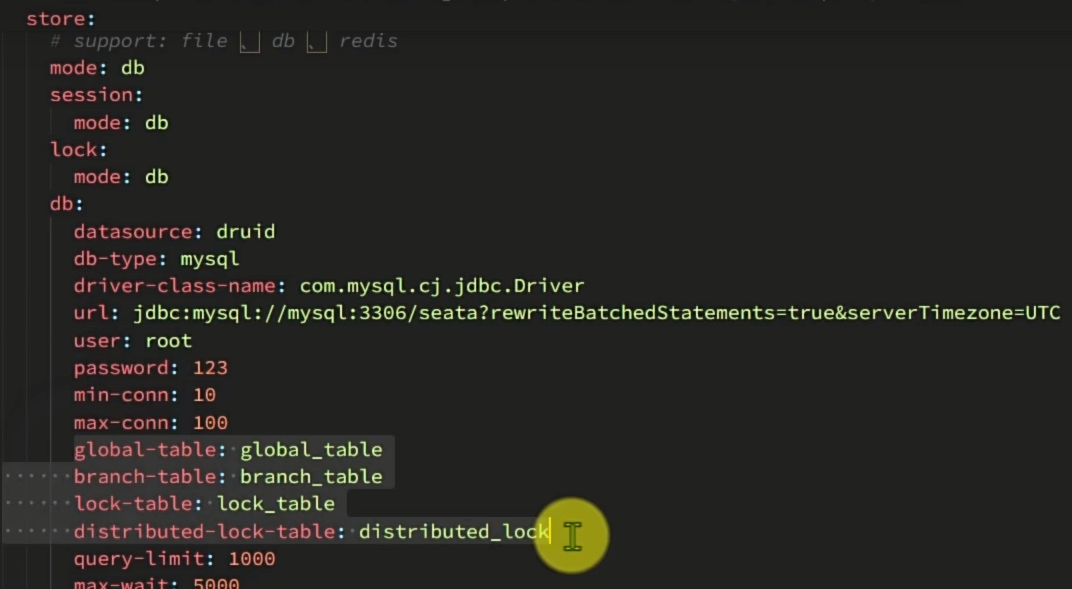
类似yml的配置 可以决定管理分布式时候用的数据来源 这里的seata作为一个微服务部署在docker 由于和其他的不一样不是在本地 因此网络如果不同访问不到nacos和数据库自然运行时候就会挂掉且无法和他们通信
可以用docker ps -a --format '{{.ID}}\t{{.Names}}\t{{.Networks}}'去查看已有容器的连接网络 并通过 docker network connect [网络名] [容器名] 这样就能正常拉起 也让我知道了 上次errcode 255挂掉是因为和数据库/nacos连不上
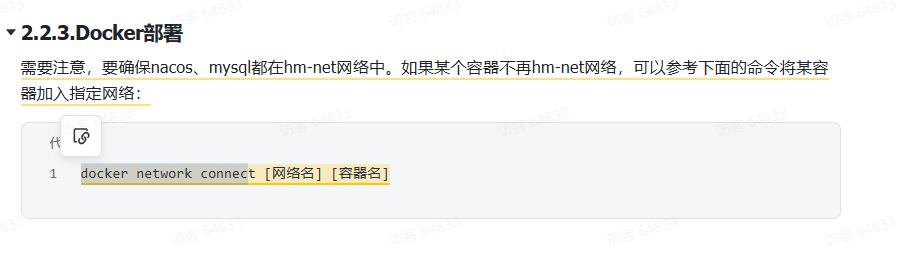
别的服务要被seata分布式事务管理就要给seata注册 为了找到一个seata实例就需要配置这么多 通过命名空间 group 集群等来进行找到实例 这里的事务组就是集群 大概就是多台机器主备关系共同完成任务的一个概念 我在公司也用过集群
3.nacos依赖mysql seata 依赖这两者 有时候比如mysql 没就绪 或者nacos 起的有问题debug时间就长了 建议restart大法解决或者
docker上seata有问题就会导致通信问题 同时boostrap 及nacos也会导致 调了40min终于通了
4.关于分布式事务 主要分为XA与AT两种模式具体管理
XA:关系数据库中由于事务复杂很多就继集成了这个模式 大概是全局事务执行每个分支事务前都会在TC注册下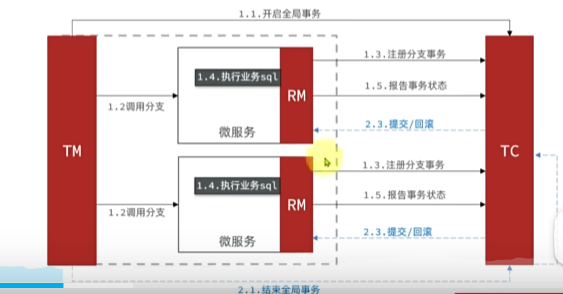
其中每个都开启排他锁 等待TM确认所有分支都成功或者失败才 一起回滚或者提交
假如每次失败概率正比于1/n 那么就会平均失败O(n)次 那么总共时间复杂度就会说O(n^2)
然后的话由于大部分数据库支持 所以实现极其简单


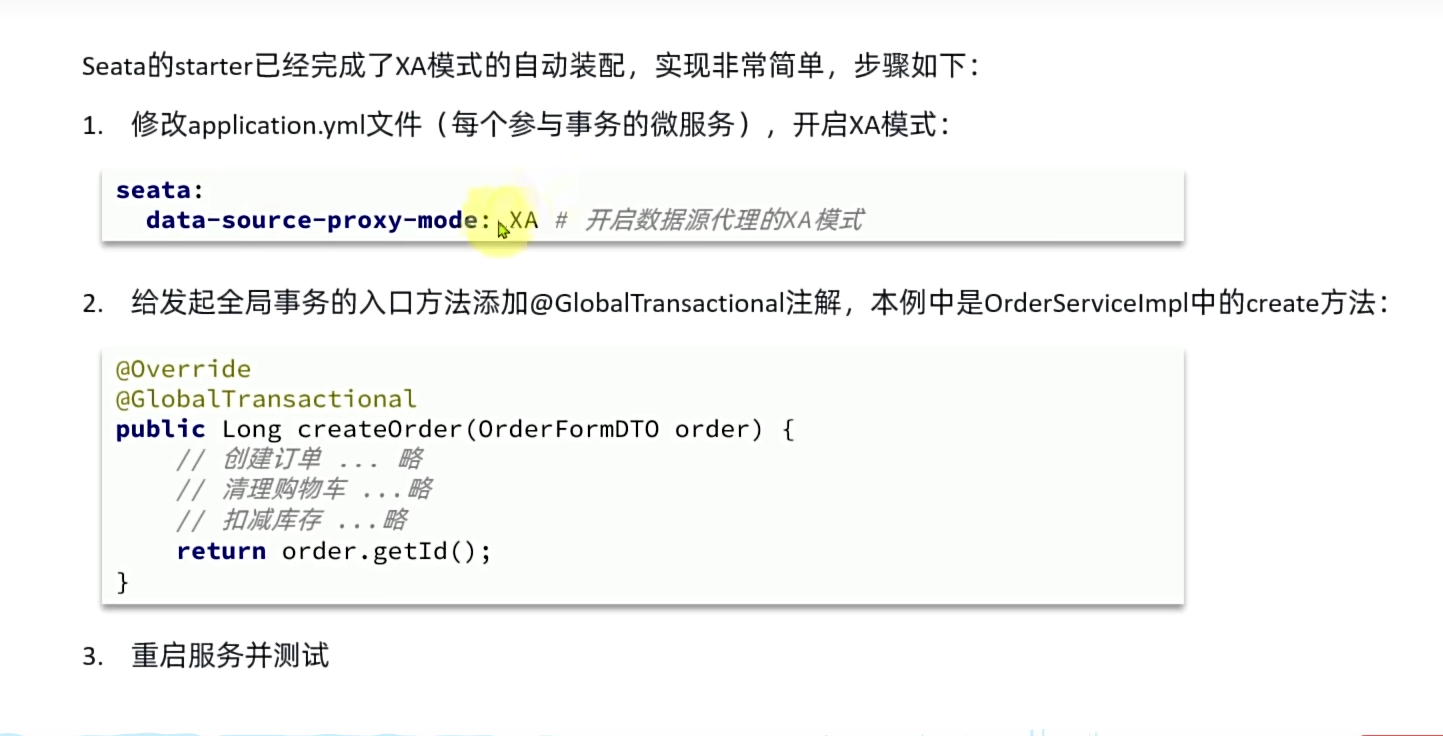
AT:的话 大概就是Xa进阶版 通过快照来避免了统一提交的的O(n^2)


同理如果失败率1/n 大概是O(n+1)复杂度 中间出现了短暂不一致
每个微服务都需要有自己的undolog及相应的at数据库可以看到确实存在二阶段回滚


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









