






这篇文章主要介绍了python爬虫批量下载pdf文件,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。

任务起源
周六晚上小组开会,组长安排了一个根据ROI搜索HiRISE影像并进行下载的任务。
这项任务主要有两个步骤:
-
访问Mars Orbital Data Explorer网站,根据ROI检索HiRISE数据,得到数据搜索结果学python用啥书比较好。
-
根据搜索结果下载影像。MODE上可以对数据进行打包下载,但是下载的数据量有限制,因此选择到另一个HiRISE数据下载网站上根据影像ID进行搜索、下载。
Mars Orbital Data Explorer
HiSIRE数据下载网站
接到这项任务后,我并没有马上按部就班地开工干活,而是先停下来思考了一下。如果全过程都仅靠人工手动操作,那么对于每一幅影像而言,需要进行的步骤是:选中影像ID,复制,点击搜索框,粘贴,搜索,点击搜索结果,下拉定位到下载链接,点击下载。这个过程共有8个细分操作步骤,而且对于每幅影像都要进行一遍相同的操作,不可谓不繁琐。基于不做无用重复劳动的考虑,使用Python+Selenium库的方式将这个过程自动化。
搜索框
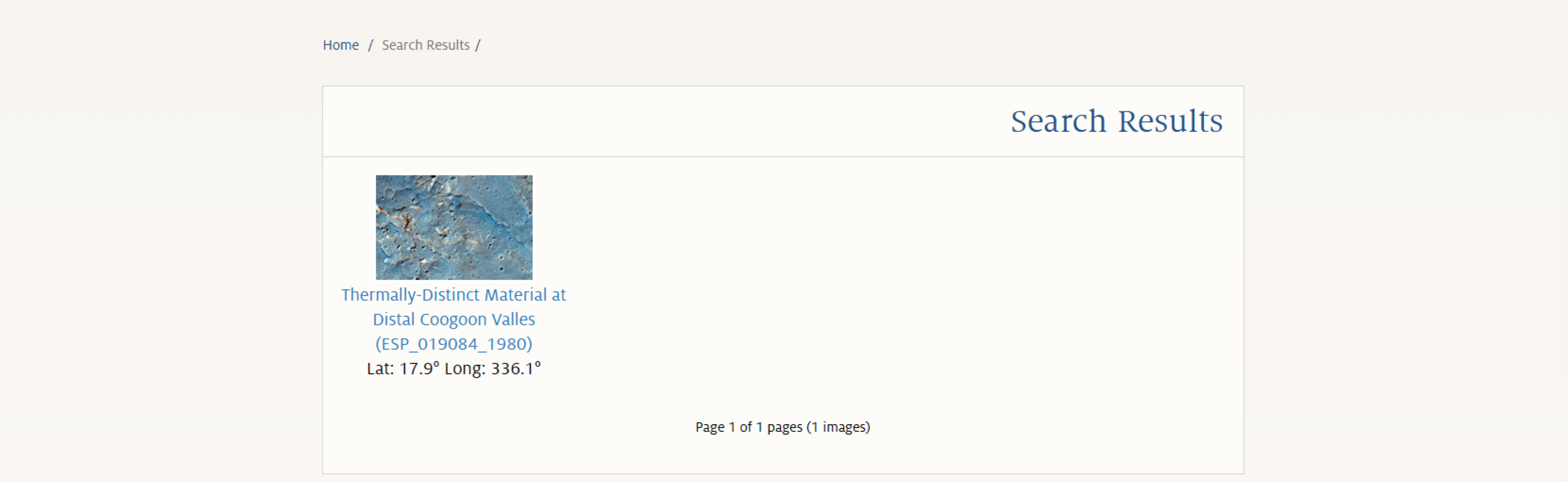
搜索结果页面
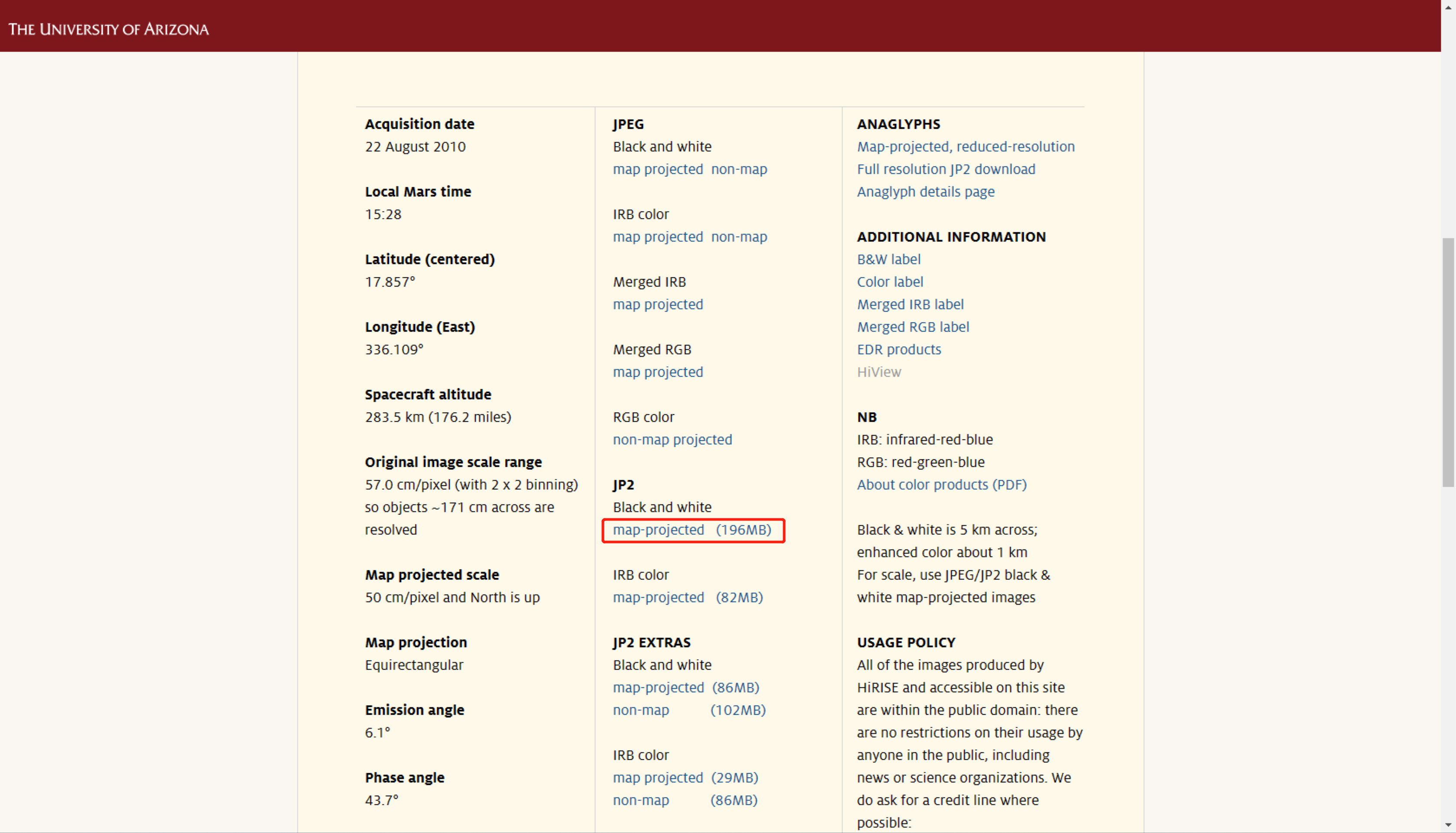
影像数据详情页和下载链接所在位置
环境配置
Python环境准备及相关库安装
-
Python环境
我使用Anaconda配置了一个虚拟环境,并在Pycharm中使用该环境进行编程。
配置环境的具体方法比较简单,可以参照网上的其他教程,在此不加赘述。
-
Selenium库
浏览器的自动调试主要通过Selenium库实现。在安装Selenium库是建议安装最新版本,因为旧版本与新版本之间的语法可能存在一定差异,这种差异会导致程序出bug。
在命令行中输入如下命令,进行Selenium库的安装。
pip install selenium安装Edge浏览器驱动
Selenium库需要配合浏览器驱动才能进行自动调试。根据自己电脑平台到Edge浏览器驱动下载页 下载驱动程序,下载解压后将msedgedriver.exe文件复制到Python所在的目录下即可。
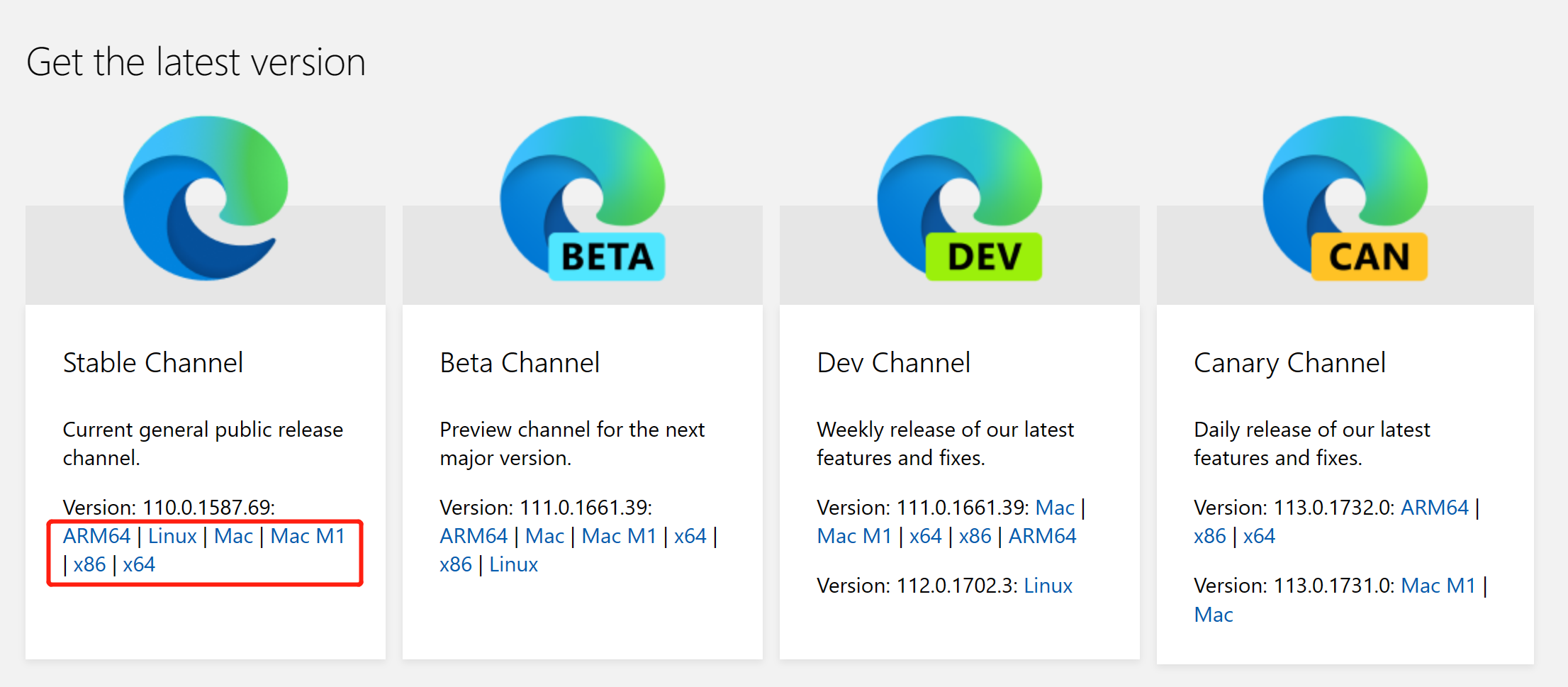
Edge浏览器驱动下载页
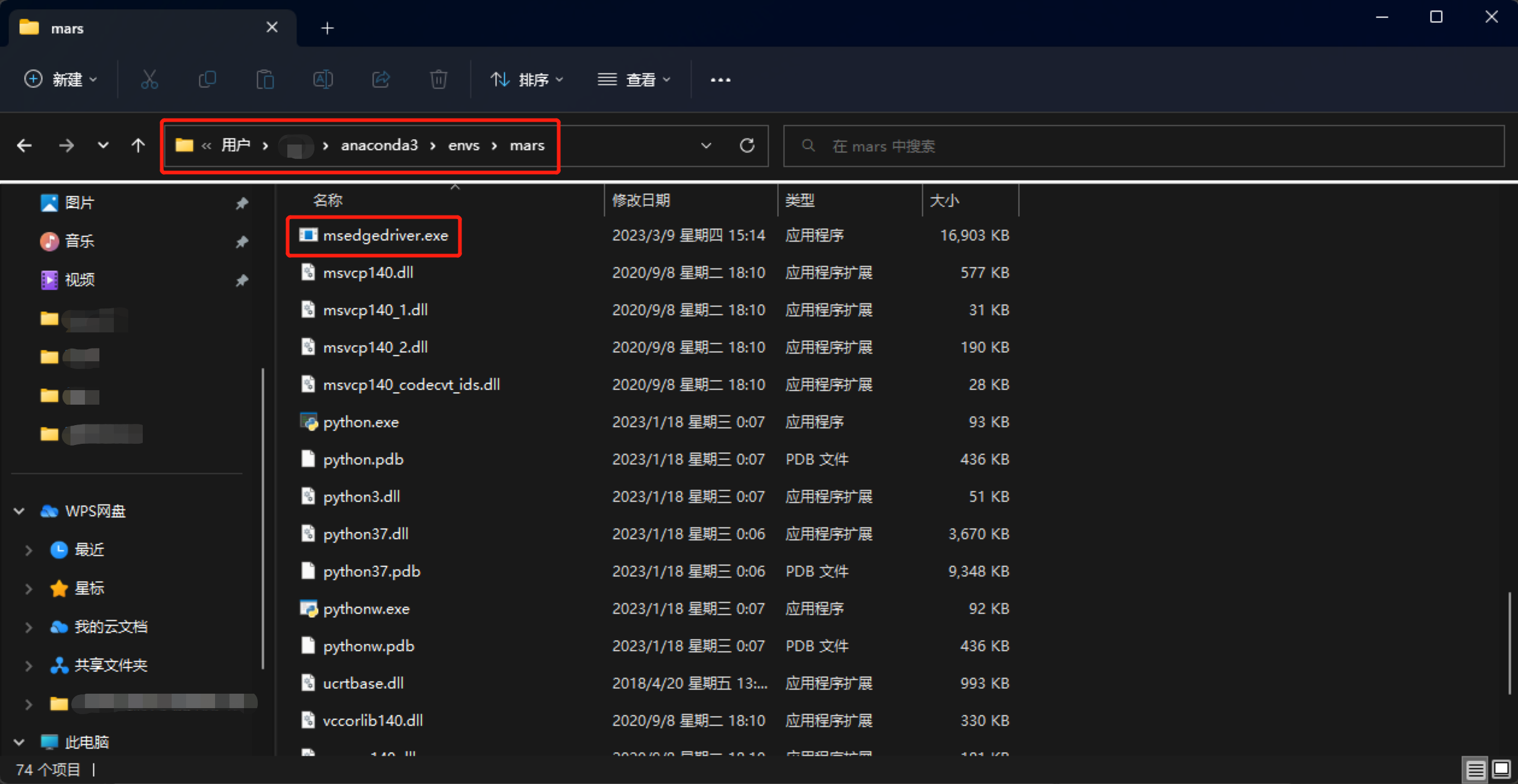
复制浏览器驱动
编程思路
代码需要完成的任务主要有两个:1.解析数据查询结果;2.根据影像ID到网页上进行下载。
-
解析数据查询结果
这个步骤的目的是从MODE直接导出的SearchResults.txt中提取出影像ID,便于在数据下载网站上进行查询。观察文件中的记录可以发现,每一幅影像对应一条记录,每条记录内的不同字段都是用逗号分隔的,因此使用简单的文件读取和字符串处理就可以获取影像ID列表。
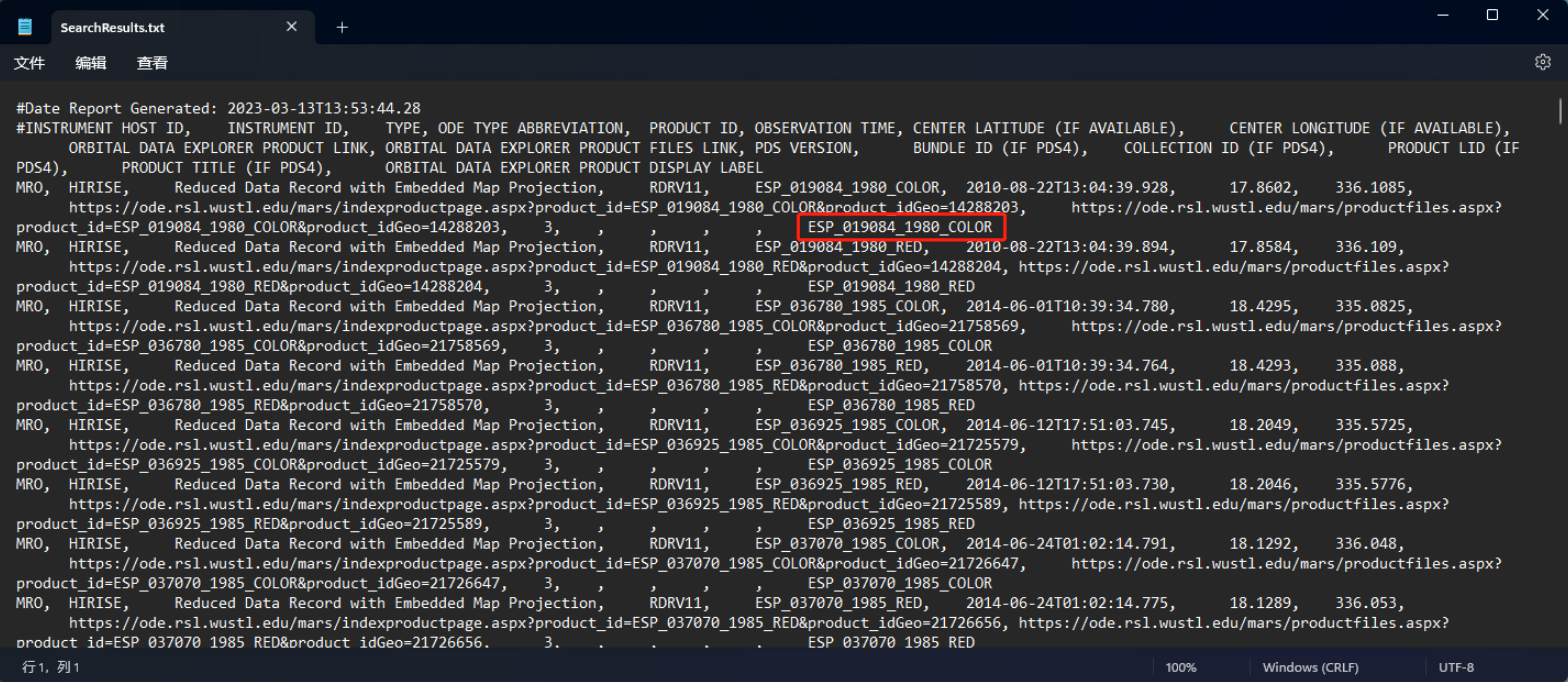
SearchResults.txt文件
-
根据影像ID到网页上进行下载
通过对影像数据详情页的url进行观察,发现不同影像对应url的前面一串内容都是固定的,只有最后一项不同,且为影像ID。那么利用这个规律,就可以根据影像ID生成一系列不同的url,从而跳转到对应的影像数据详情页。

不同影像详情页的地址
在原计划中,根据影像ID跳转到对应详情页后,由程序定位到下载链接元素,并点击进行下载。但在手动测试流程的过程中,发现我的Edge浏览器不知出于什么原因,点击下载链接后总是使用内建下载,无法由迅雷接管,不太方便。所以调整了思路,改为由程序定位到下载链接元素后,不直接点击下载,而是将下载链接保存至文本文档中,之后手动将下载链接复制到迅雷中进行批量下载。
-
通过XPath定位下载链接元素
定位下载链接元素是至关重要的一步,能否正确定位到该元素决定了能否获取正确的下载链接。在本流程中,是通过XPath来定位下载链接元素的,这个方法比较简便。获取元素XPath的具体步骤如下:
-
在Edge浏览器中打开开发人员工具(Ctrl+Shift+I)。
-
使用光标定位到目标的下载链接元素。
-
在右栏列表中对应元素处右键-复制-复制XPath。

打开Edge浏览器的开发人员工具
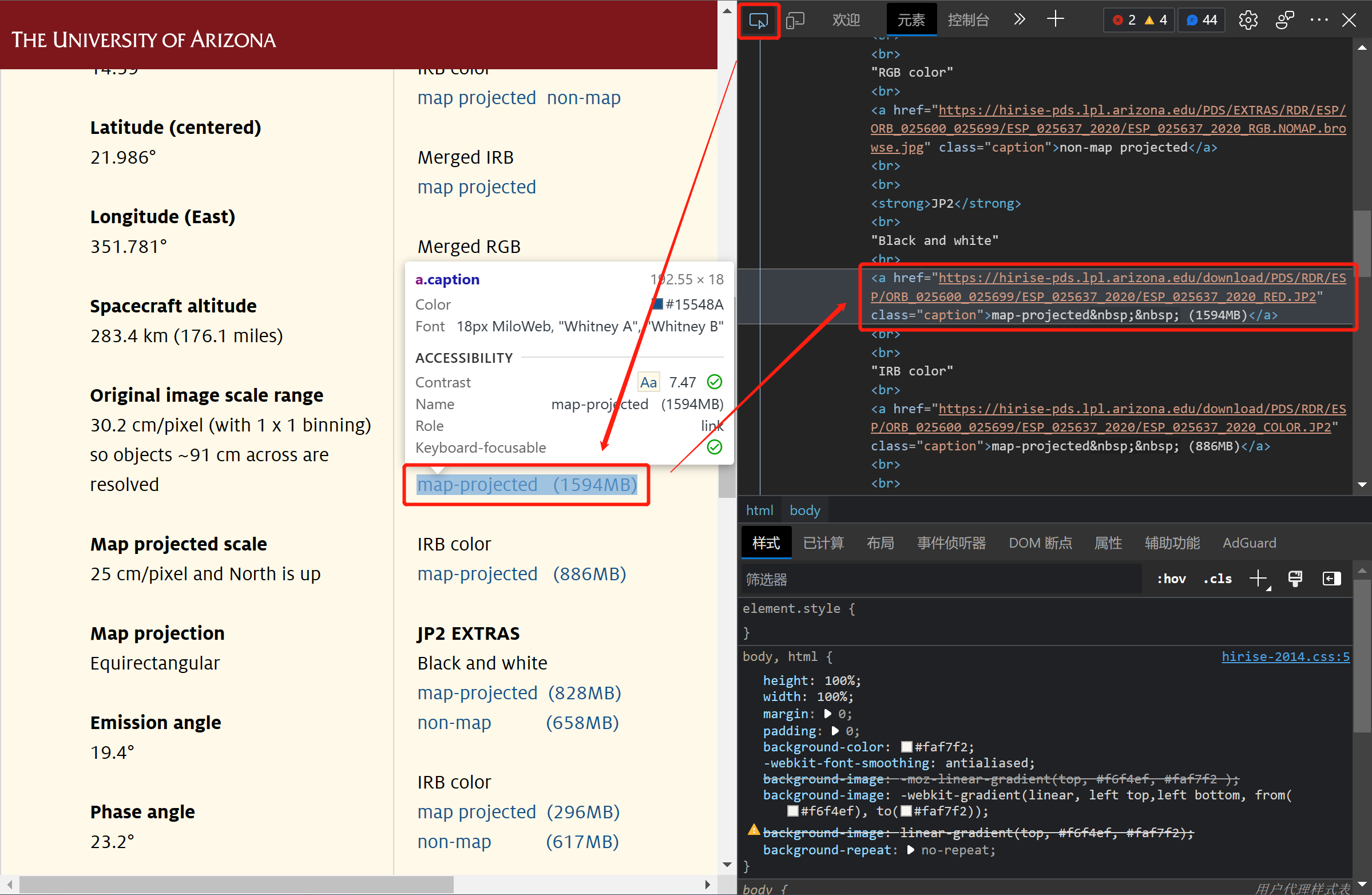
定位到目标下载链接元素
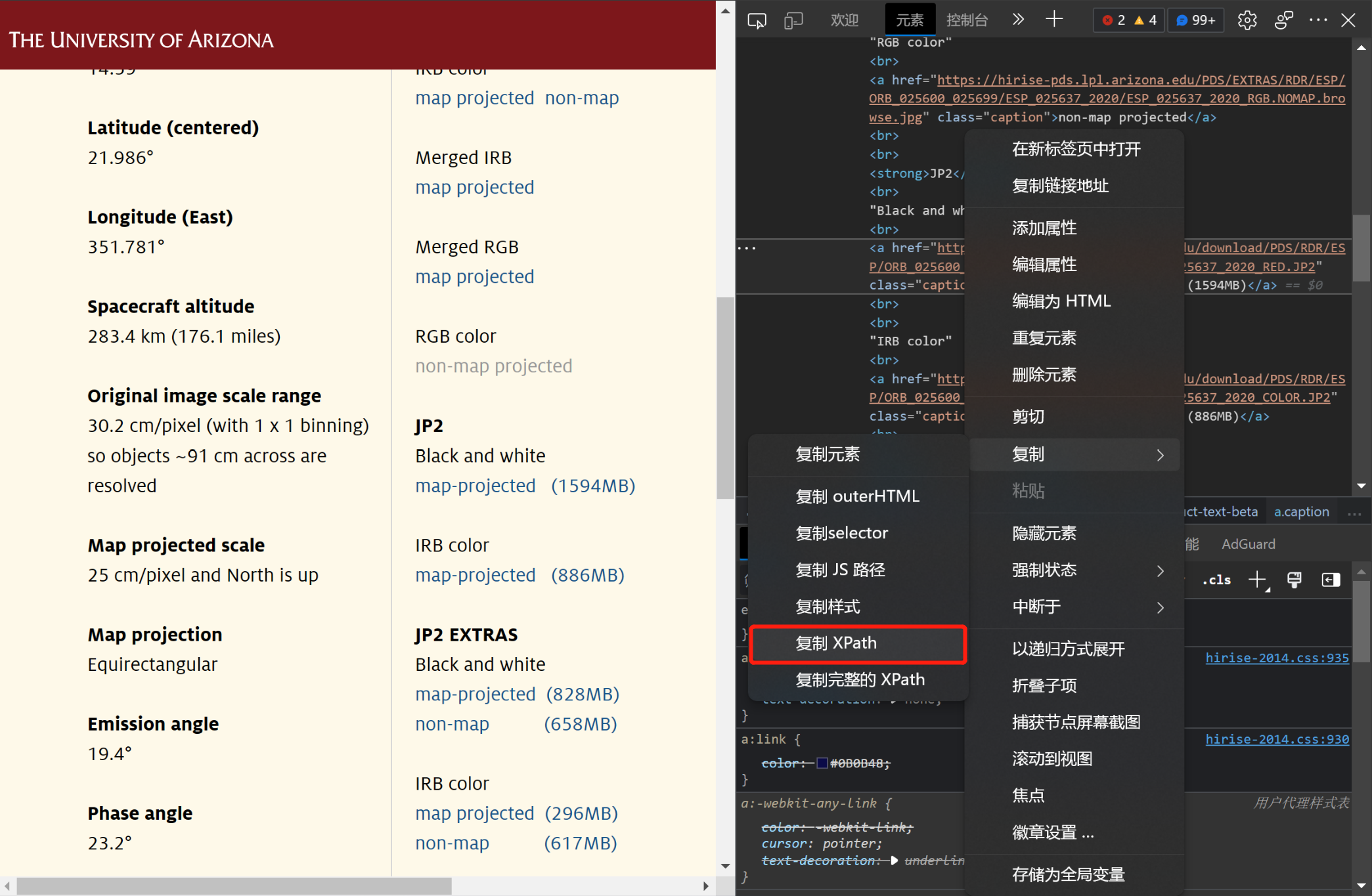
复制元素的XPath
这样就得到了下载链接元素的XPath,代码可以据此定位下载链接了。
/html/body/div[3]/div[2]/table/tbody/tr/td[2]/a[8]但在调试的过程中发现:在不同影像的详情页面中,下载链接对应元素的XPath并不是固定的。它的XPath还可能是如下的样式,其中包含的部分索引也存在变化。
/html/body/div[3]/div[1]/div[5]/table/tbody/tr/td[2]/a[8]
/html/body/div[3]/div[1]/div[5]/table/tbody/tr/td[2]/a[3]在这种情况下,单一形式的XPath并不能确保程序每次都能在详情页面中准确地找到下载链接。因此在代码中使用了循环语句来对不同情况进行遍历。在遍历的过程中,通过链接中包含的影像文件后缀来判断是否为目标下载链接,若是则进行保存,否则跳过。
至此,代码的关键步骤就完成了。
完整代码
为了提高运行效率,代码还进行了一定程度的优化,比如设置了浏览器不加载图片的选项,提高网页加载速度。
使用代码时,用户只需要写好存放搜索结果的文本文档所在的目录,并输入存放搜索结果的文本文档名字(例如这里的SearchResults),程序就能自动从网页上批量获取影像数据的下载链接,并将其保存在文本文档中,非常便捷、高效。
存放搜索结果、下载链接和缺少链接影像ID的文本文档
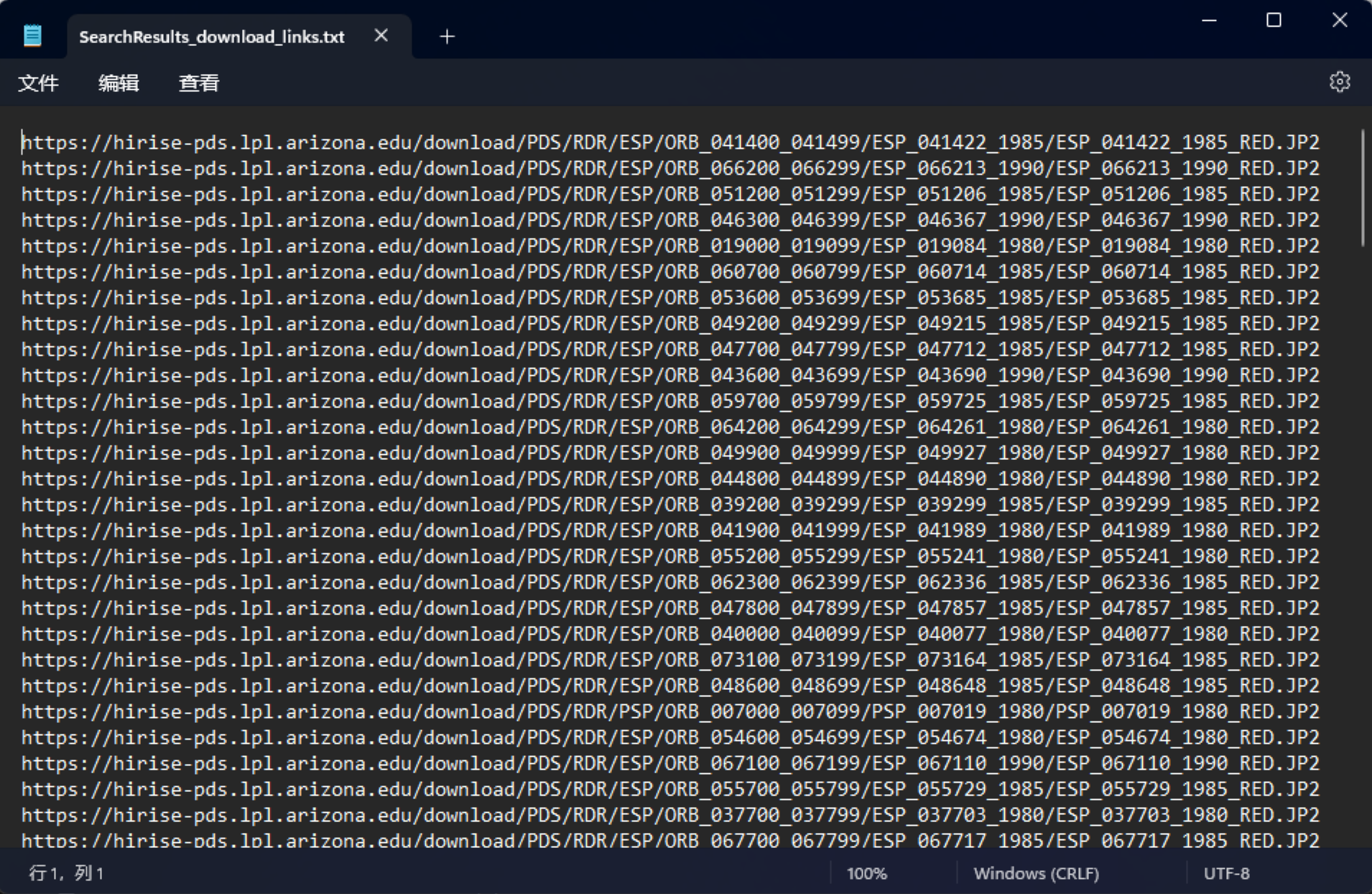
批量获取的影像下载链接
最终完整版的代码如下:
import os
from selenium import webdriver
from selenium.webdriver.common.by import By
# 路径和文件名定义
root_path = "D:\img_list" # 存放搜索结果txt所在的目录【请自行修改】
IMG_list_name = input("请输入存放搜索结果的txt文件名:") # 存放搜索结果txt的名称【请自行输入(不带后缀)】
IMG_list_path = os.path.join(root_path, "%s.txt" % IMG_list_name) # 影像ID的txt文件路径
download_links_file_path = os.path.join(root_path, "%s_download_links.txt" % IMG_list_name) # 保存下载链接的txt文件
lack_file_path = os.path.join(root_path, "%s_lack_download_links.txt" % IMG_list_name) # 保存未找到下载链接的imgID的txt文件
# 根据含有影像ID的txt文档生成影像ID列表
with open(IMG_list_path, mode='r') as f:
records_list = f.readlines()
filenames_raw_list = []
for record in records_list:
filenames_raw = record.split(",")[-1]
if "_" in filenames_raw:
filenames_raw_list.append(filenames_raw)
filenames = []
for i in filenames_raw_list:
i = i.replace("\t", "")
i = i.replace("\n", "")
i = i.replace("_COLOR", "")
i = i.replace("_RED", "")
filenames.append(i)
filenames_unique = set(filenames)
f.close()
# 用于记录获取到的下载链接和缺少下载链接的影像ID
download_links_file = open(download_links_file_path, mode='a+')
download_links_file.seek(0)
download_links = download_links_file.readlines()
lack_file = open(lack_file_path, mode='w')
lack_list = []
# Edge浏览器配置
Edge_opt = webdriver.EdgeOptions()
No_Image_loading = {"profile.managed_default_content_settings.images": 2}
Edge_opt.add_experimental_option("prefs", No_Image_loading)
driver = webdriver.Edge(options=Edge_opt) # 打开Edge浏览器(不加载图片模式)
# 遍历所有影像ID进行批量搜索和获取下载链接
for filename in filenames_unique:
Existed = False
for links in download_links:
if filename in links:
Existed = True
break
if Existed:
continue
link = 'https://www.uahirise.org/%s' % filename # 根据影像ID构建链接
driver.get(link) # 根据链接跳转网页
for i in range(10):
try:
Found = False # 标记是否找到影像
download_links_XPath1 = '/html/body/div[3]/div[2]/table/tbody/tr/td[2]/a[%s]' % str(i+1) # 元素的XPath
download_link1 = driver.find_element(By.XPATH, download_links_XPath1).get_attribute('href') # 根据XPath查找元素
suffix = download_link1.split("_")[-1] # 获取后缀
if suffix == 'RED.JP2': # 根据后缀判断是否为所要的下载链接
download_links.append(download_link1)
download_links_file.write(download_link1 + "\n")
Found = True
break
download_links_XPath2 = '/html/body/div[3]/div[1]/div[5]/table/tbody/tr/td[2]/a[%s]' % str(i + 1)
download_link2 = driver.find_element(By.XPATH, download_links_XPath2).get_attribute('href')
suffix = download_link2.split("_")[-1]
if suffix == 'RED.JP2':
download_links.append(download_link2)
download_links_file.write(download_link2 + "\n")
Found = True
break
except Exception as e:
# print(e) # 打印错误信息
pass
if Found:
print("%s的.JP2文件下载链接已获取!" % filename)
else:
print("%s的.JP2文件下载链接未获取!" % filename)
lack_list.append(filename)
driver.quit() # 关闭浏览器
download_links_file.close() # 关闭文件
print("下载链接已经获取完成!")
# 处理缺少下载链接的影像
lack_file.close()
if len(lack_list) == 0:
print("没有缺少下载链接的影像!")
else:
for filename in lack_list:
lack_file.write(filename + "\n")
print("缺少下载链接的%d幅影像ID已记录!" % len(lack_list))

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









