









 本文详细介绍了K-means聚类算法,通过欧几里得距离将数据点分配到最近的聚类中心,包括随机初始化聚类中心、计算距离、更新聚类中心以及算法收敛条件。
本文详细介绍了K-means聚类算法,通过欧几里得距离将数据点分配到最近的聚类中心,包括随机初始化聚类中心、计算距离、更新聚类中心以及算法收敛条件。
先来看一下一个K-means的聚类效果图
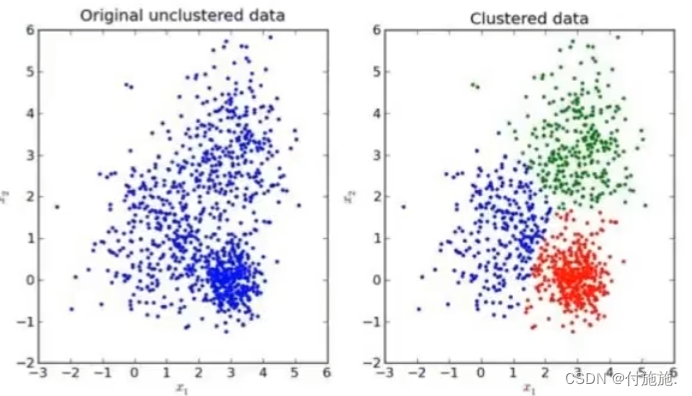
在 K-Means 算法中,距离最近通常是指欧几里得距离(Euclidean distance)。欧几里得距离是指两个数据点在特征空间内的直线距离。公式如下所示:
distance(xi,cj)=∑k=1d(xik−cjk)2distance(x_i, c_j) = \sqrt{\sum_{k=1}^d (x_{ik} - c_{jk})^2}distance(xi,cj)=∑k=1d(xik−cjk)2
其中,xix_ixi 是数据集中的第 i 个数据点,cjc_jcj 是聚类中心点,ddd 是特征空间的维度数。通过计算数据点与各个聚类中心点之间的欧几里得距离,可以确定每个数据点所属的簇。
具体而言,在下面算法的第二步中,对于每个数据点 xix_ixi,计算它与 K 个聚类中心点之间的距离(即 distance(xi,cj)distance(x_i, c_j)distance(xi,cj)),然后将其分配给距离最近的聚类中心点 cjc_jcj 所代表的聚类。
简单来说,就是找到每个数据点与各个聚类中心点之间的欧几里得距离,然后将其归类到距离最近的聚类中心点所代表的聚类中去。
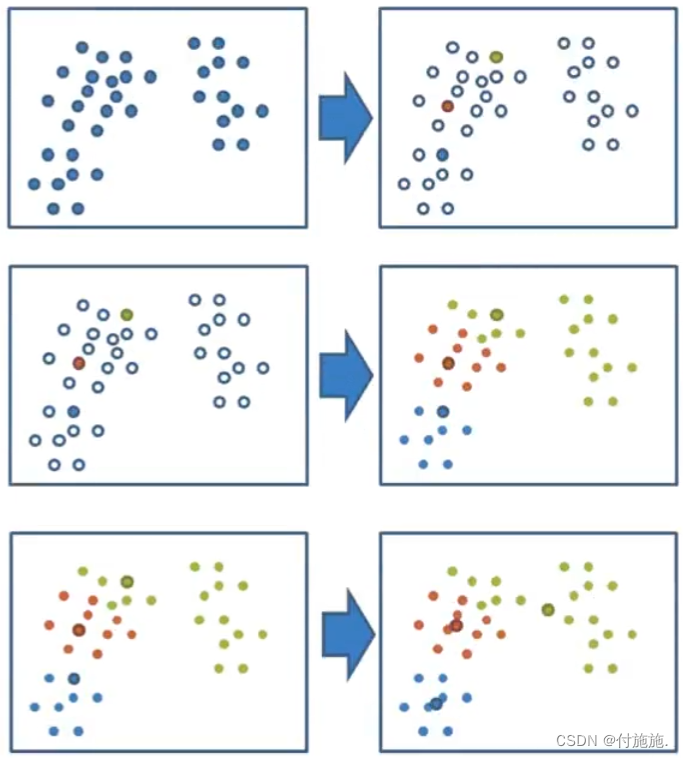
K-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心(一开始就要设置)
- 2、对于其他的每个数据点,计算其到 K 个聚类中心的距离,并将其归类到距离最近的聚类中心所属的聚类。
- 3、对于每个聚类,重新计算其新的聚类中心,通常是使用该聚类所有数据点的平均值作为新的聚类中心。
- 4、如果新的聚类中心点与原来的聚类中心点相同,则结束算法;否则重复步骤 2 和 3,直到收敛为止。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









