







本文依据ONFI5.1及个人工作经验整理而成,如有错误请留言。
文章为付费内容,已加入原创侵权保护,禁止私自转载及抄袭。
文章所在专栏:《黑猫带你学:NandFlash详解》
1 定义
在之前的章节中,我们知道了nand write的原理,此处不再赘述。
用下面一张图1,表示program disturb和pass disturb。其实就能明白什么叫做program disturb和pass disturb了。
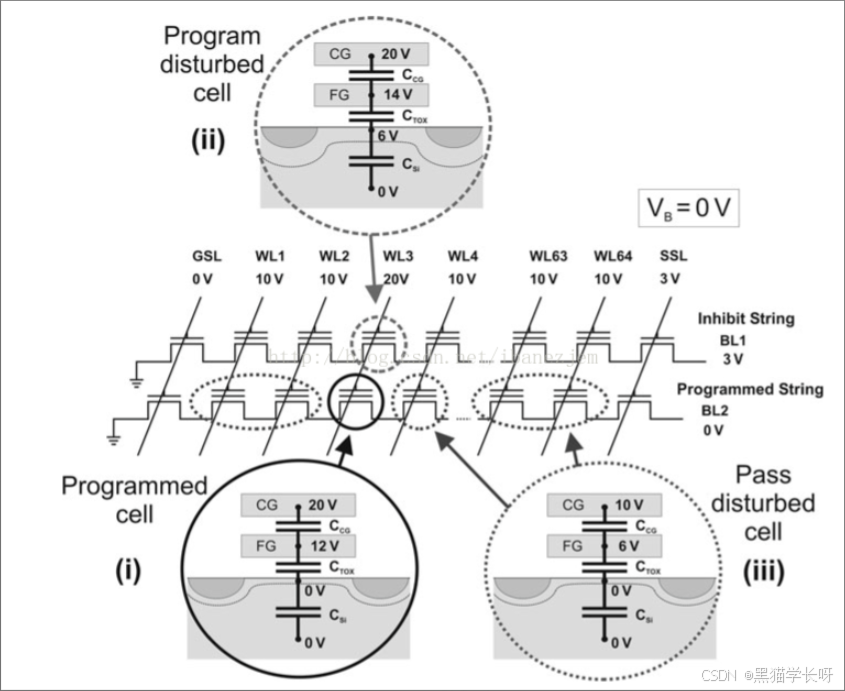
program disturb
WL3上同时存在不需要编程的Cell,比如说(BL1 WL3)的Cell。但是因为WL3增加了20V的高电压,所以会导致其他不被编程的cell也受到高压影响,然后导致电子进入浮栅中,形成弱编程。
这些不需要被编程的cell称为program-inhibit cell。
影响范围:
影响较小。在NAND闪存中,当对某个Wordline(WL)进行编程操作

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











