






一、背景介绍
在360的云计算解决方案OpenStack中,独享型实例采用绑核模式,以确保CPU隔离并提升性能。绑核模式分为单NUMA和双NUMA两种形式:单NUMA套餐将所有vCPU/内存分配绑核到计算节点的一个NUMA节点上,双NUMA套餐则将vCPU/内存平均分配绑核到两个NUMA节点上。基于计算节点为NUMA的CPU架构,绑核型单NUMA的虚拟机在性能上优于绑核型双NUMA虚拟机。为确保用户虚拟机的高性能,在奥创云管平台调度用户创建虚拟机时会优先选择单NUMA套餐,当单NUMA套餐资源不足时,再调度双NUMA套餐。计算节点随着虚拟机的创建删除动作,NUMA上CPU/内存出现碎片问题,导致无法创建绑核型单NUMA或者双NUMA套餐虚拟机。为了充分利用计算节点的CPU/内存资源,需要实现虚拟机CPU绑核NUMA不均衡分配。
二、NUMA架构
现代的计算机系统中,处理器的处理速度远快于主存的速度,所以限制计算机性能的瓶颈在存储器带宽上。NUMA(Non-Uniform Memory Access,非一致性内存访问)是一种在多处理系统中的内存设计架构,在多处理器中,CPU访问系统上各个物理内存的速度可能不一样,一个CPU访问其本地内存的速度比访问(同一系统上)其他CPU对应的本地内存快一些。NUMA的设计理念就是将处理器和存储器划分到不同的节点(NUMA Node),使它们都拥有几乎相同的资源。在NUMA节点内部会通过自己的存储总线访问内部的本地内存,而所有NUMA节点都可以通过主板上的共享总线来访问其他节点的远程内存。显然,处理器访问本地内存和远程内存的耗时并不一致,NUMA非一致性内存访问因此得名。而且因为节点划分并没有实现真正意义上的存储隔离,所以NUMA同样只会保存一份操作系统和数据库系统的副本。
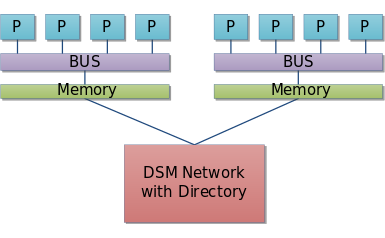
NUMA多节点的结构设计也在一定程度上解决存储器带宽瓶颈的问题。假设有一个4 NUMA节点的系统,每个NUMA节点内部具有1GB/s的存储带宽,外部共享总线也具有1GB/s的带宽。理想状态下,如果所有的处理器总是访问本地内存的话,那么系统就拥有了4GB/s的存储带宽,此时每个节点可以近似看成一个SMP;相反,在最不理想的情况下,如果所有处理器处理器总是跨节点访问远程内存的话,那么系统就只能有1GB/s的存储带宽了。
除此之外,使用外部共享总线时,可能会触发NUMA节点间的Cache同步异常,这会严重影响内存密集型工作负载的性能。当I/O性能至关重要时,共享总线上的Cache资源浪费,会让连接到远程PCIe总线上的设备(不同NUMA节点间通信)作业性能急剧下降。由于这个特性,基于NUMA开发的应用程序应该尽可能避免跨节点的远程内存访问。因为,跨节点内存访问不仅通信速度慢,还可能需要处理不同节点间内存和缓存的数据一致性。多线程在不同节点间的切换,是需要花费很大成本的。因为NUMA没有实现彻底的主存隔离。所以NUMA远没有达到无限扩展的水平,最多可支持几百个CPU。这是为了追求更高的并发性能所作出的妥协,一个节点未必就能完全满足多并发需求,多节点间线程切换实属一个折中的方案。这种做法使得NUMA具有一定的伸缩性,更加适合应用在服务器端。
三、Openstack的CPU/内存绑定分配
将虚拟机的vCPUs绑定到pCPUs,vCPU只会在指定的pCPU上运行,避免pCPU间线程切换(上下文切换,内存数据转移)带来的性能开销。
openstack创建虚拟机套餐命令
openstack flavor set <FLAVOR-NAME> \ --property hw:cpu_policy=<CPU-POLICY> \ --property hw:cpu_thread_policy=<CPU-THREAD-POLICY>CPU-POLICY有2种参数类型。
shared(默认的):允许vCPUs跨pCPU浮动,尽管vCPUs受到的NUMA Node的限制也是如此。
dedicated:Guest的vCPUs会严格的pinned到pCPUs的集合中。在没有明确vCPU拓扑的情况下,Drivers会将所有vCPU作为Sockets的一个Core或一个Thread(如果启动超线程)。如果已经明确的将vCPUs Topology Pinned到CPUs Topology中时,会严格执行CPU Pinning,将Guest内部的CPU的拓扑匹配到已经Pinned的宿主机的CPUs的拓扑中。此时的overcommit ratio 为 1.0。例如:虚拟机的两个vCPU被pinned到了一个宿主机的Core的两个Thread 上,那么虚拟机内部将会获得一个Core(对应的两个Thread)的拓扑。
如果设定为shared,那么即便为虚拟机分配了一个NUMA node,但 vCPUs仍会在 NUMA Node所拥有的 pCPUs间浮动;如果设定为dedicated,那么虚拟机就会严格按照Guest NUMA Topology和Host NUMA Topology的映射关系将vCPUs pinned到pCPUs,实现CPU的绑定。而且这种映射,往往是一个vCPU被绑定到一个pCPU的Core或Thread上(如果开启超线程)。
CPU-THREAD-POLICY有下列3种参数类型。
prefer(默认的):主机也许是SMT架构,如果是SMT架构,那么将会优先将一个vCPU绑定到一个宿主机的Thread Siblings上,否则按照一般的方式将vCPU绑定到Core上。
isolate:主机不应该是SMT架构,或者能够识别Thread Siblings并从逻辑上屏蔽它。每一个vCPU都将会被pinned到一个物理CPU的Core上(如果是多核CPU)。如果物理机是SMT架构支持超线程,那么物理Cores就具有Thread Siblings,这样的话,如果一个Guest不同的vCPU被pinned到不同的物理Core上,那么这个物理Core将不会再继续接受其他Guest的vCPU。所以,需要保证物理Core上没有Thread Siblings。
require:宿主机必须是SMT架构,每一个vCPU都分配给Thread Siblings。但如果没有足够的Thread Siblings,则会调度失败。如果主机不是 SMT架构,则配置无效。
只有设定hw:cpu_policy=dedicated时,hw:cpu_thread_policy才会生效。可见,后者设定的是vCPU pinning to pCPU的策略。
Nova分配NUMA的两种方式
自动分配NUMA的约束和限制:仅指定Guest NUMA Nodes的个数,然后由Nova根据Flavor的规格平均将vCPU/Memory分布到不同的Host NUMA Nodes上(默认从 Host NUMA Node 0 开始分配,依次递增)。这将最大程度的降低配置参数的复杂性。如果没有NUMA节点的定义,管理程序可以在虚拟机上自由使用NUMA拓扑。
不能设置numa_cpus 和numa_mem。
自动从0节点开始平均分配。
手动指定NUMA的约束和限制:不仅指定Guest NUMA Nodes的个数,还指定了每个Guest NUMA Nodes上分配的vCPU ID和 Memory Size。设定了Guest NUMA topology,由Nova来完成Guest NUMA Nodes和Host NUMA Nodes的映射关系。
设定的vCPU总数需要和虚拟机flavor中的CPU总数一致。
设定的Memory大小需要和虚拟机flavor中的memory大小一致。
必须设置numa_cpus和numa_mem。
需要从Guest NUMA Node 0开始指定各个NUMA节点的资源占用参数。
flavor属性应用场景
hw:huma_nodes=1,应该让Guest的vCPU/Memory从一个固定的Host NUMA Node中获取,避免跨NUMA Node的Memory访问,减少不可预知的通信延时,提高Guest性能。
hw:huma_nodes=N,当Guest的vCPU/Memory超过了单个Host NUMA Node占有的资源时,手动将Guest划分为多个Guest NUMA Node,然后再与 Host NUMA Node对应起来。这样做有助于Guest OS感知到Guest NUMA并优化应用资源调度。
hw:huma_nodes=N,对于Memory访问延时有高要求的Guest,即可以将vCPU/Memory完全放置到一个Host NUMA Node中,也可以主动将Guest划分为多个Guest NUMA Node,再分配到Host NUMA Node。以此来提高总的访存带宽。
如果N == 1,表示Guest的vCPU/Memory固定从一个Host NUMA Node获取。
如果N != 1,表示为Guest划分N个Guest NUMA Node,并对应到N个Host NUMA Node上。
四、双NUMA套餐不均衡CPU内存分配
nova侧分配NUMA的CPU/内存实现,如下是核心代码
def numa_fit_instance_to_host( host_topology, instance_topology, limits=None, pci_requests=None, pci_stats=None): """Fit the instance topology onto the host topology. Given a host, instance topology, and (optional) limits, attempt to fit instance cells onto all permutations of host cells by calling the _fit_instance_cell method, and return a new InstanceNUMATopology with its cell ids set to host cell ids of the first successful permutation, or None. :param host_topology: objects.NUMATopology object to fit an instance on :param instance_topology: objects.InstanceNUMATopology to be fitted :param limits: objects.NUMATopologyLimits that defines limits :param pci_requests: instance pci_requests :param pci_stats: pci_stats for the host :returns: objects.InstanceNUMATopology with its cell IDs set to host cell ids of the first successful permutation, or 将实例拓扑适配到主机拓扑,给定主机、实例拓扑和(可选)限制,尝试通过调用 `_fit_instance_cell` 方法将实例cell适配到主机cell的所有排列中,并返回一个新的 InstanceNUMATopology,其cell ID 设置为第一个成功排列的主机cell ID,或返回 None。 """ if not (host_topology and instance_topology): LOG.debug("Require both a host and instance NUMA topology to " "fit instance on host.") return elif len(host_topology) < len(instance_topology): LOG.debug("There are not enough NUMA nodes on the system to schedule " "the instance correctly. Required: %(required)s, actual: " "%(actual)s", {'required': len(instance_topology), 'actual': len(host_topology)}) return emulator_threads_policy = None if 'emulator_threads_policy' in instance_topology: emulator_threads_policy = instance_topology.emulator_threads_policy network_metadata = None if limits and 'network_metadata' in limits: network_metadata = limits.network_metadata host_cells = host_topology.cells # If PCI device(s) are not required, prefer host cells that don't have # devices attached. Presence of a given numa_node in a PCI pool is # indicative of a PCI device being associated with that node # 如果不需要 PCI 设备,优先选择没有附加设备的主机cell。某个 NUMA 节点在 PCI 池中的存在表明该节点与 PCI 设备相关联。 if not pci_requests and pci_stats: host_cells = sorted(host_cells, key=lambda cell: cell.id in [ pool['numa_node'] for pool in pci_stats.pools]) # TODO(ndipanov): We may want to sort permutations differently # depending on whether we want packing/spreading over NUMA nodes # 获取指定数量(Instance NUMA Node Count)的 Host NUMA Nodes 全排列组合, # 并且循环这些组合逐一与 instance_numa_topology.cells 进行配对, # 筛选出作为最终 Fit Instance NUMA Topology 的 Host NUMA Nodes 组合。 for host_cell_perm in itertools.permutations(host_cells, len(instance_topology)): #全排列([0,1], 1) = [(0), (1)] ([0,1], 2) = [(0,1)] chosen_instance_cells = [] chosen_host_cells = [] # 将待验证 Host NUMA Cells 和 Instance NUMA Cells 组成元组列表。 for host_cell, instance_cell in zip(host_cell_perm, instance_topology.cells): # host_cell:[0,1] instance_cell:[0,1] -> [(host_numa0, instence_cell0),(host_numa1, instence_cell1) # host_cell:[0] instance_cell:[0] -> [(host_numa0, instence_cell0)] try: cpuset_reserved = 0 if (instance_topology.emulator_threads_isolated and len(chosen_instance_cells) == 0): # For the case of isolate emulator threads, to # make predictable where that CPU overhead is # located we always configure it to be on host # NUMA node associated to the guest NUMA node # 0. # 如果 emulator_threads_policy 是 isolated 的话,就要专门留出一个 pCPU 来给 Emulator 使用,这个 pCPU 不算入 Instance NUMA Topology Request 中 cpuset_reserved = 1 LOG.warning("numa_fit_instance_to_host host_cell:{host_cell}, instance_cell:{instance_cell}".format(host_cell=host_cell, instance_cell=instance_cell)) got_cell = _numa_fit_instance_cell(host_cell, instance_cell, limits, cpuset_reserved) LOG.warning("numa_fit_instance_to_host host_cell:{host_cell}, instance_cell:{instance_cell}, got_cell:{got_cell}".format(host_cell=host_cell, instance_cell=instance_cell,got_cell=got_cell)) except exception.MemoryPageSizeNotSupported: # This exception will been raised if instance cell's # custom pagesize is not supported with host cell in # _numa_cell_supports_pagesize_request function. break if got_cell is None: break chosen_host_cells.append(host_cell) chosen_instance_cells.append(got_cell) if len(chosen_instance_cells) != len(host_cell_perm): continue if pci_requests and pci_stats and not pci_stats.support_requests(pci_requests, chosen_instance_cells): continue if network_metadata and not _numa_cells_support_network_metadata(host_topology, chosen_host_cells, network_metadata): continue return objects.InstanceNUMATopology( cells=chosen_instance_cells, emulator_threads_policy=emulator_threads_policy)可见,绑核的双numa套餐在调度和创建虚拟机时会按照CPU和内存均分去寻找合适的计算节点
可会存在一个问题:某个计算节点上面已经落了11台虚拟机,还有8个vcpu空闲,numa0剩余2个vcpu,numa1剩余6个vcpu,此时既不能落8核的单numa套餐,也不能落8核的双numa套餐,只能落小套餐,造成一定的资源浪费。
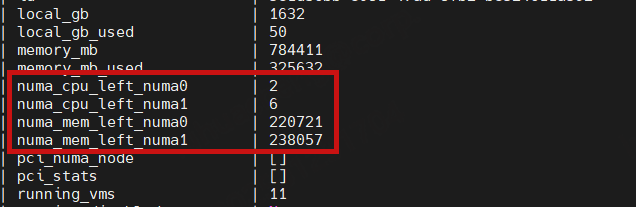
因此,需要去优化双numa套餐的cpu分配逻辑,让虚拟机能充分利用CPU资源(不优化单numa套餐的原因:保证用户虚拟机的性能)。
双NUMA套餐不均衡CPU内存分配实现:优先双numa均衡分配调度,如果双numa调度失败,根据host_cells和instance_cell构造新的单numa cells数据结构,将其传入numafit_instance_cell()函数中,得到新的got_cell,这个got_cell是单numa类型,还需要还原成双numa类型,其中的内存按照cpu和套餐cpu总数比例进行分配。
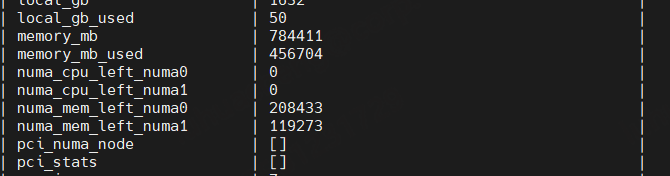
2025-01-23 10:53:49.837 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] rebuild new host_cell: NUMACell(cpu_usage=80,cpuset=set([0,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95]),id=0,memory=784410,memory_usage=440320,mempages=[NUMAPagesTopology,NUMAPagesTopology,NUMAPagesTopology],network_metadata=NetworkMetadata,pinned_cpus=set([0,4,5,6,8,9,10,11,12,13,14,15,16,17,18,19,20,21,24,26,27,28,29,30,31,32,33,34,36,37,38,39,40,41,42,43,44,45,46,47,48,52,53,54,56,57,58,59,60,61,62,63,64,65,66,67,68,69,72,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90,91,92,93,94,95]),siblings=[set([18,66]),set([17,65]),set([16,64]),set([67,19]),set([68,20]),set([59,11]),set([10,58]),set([60,12]),set([9,57]),set([5,53]),set([8,56]),set([54,6]),set([13,61]),set([52,4]),set([62,14]),set([63,15]),set([55,7]),set([0,48]),set([21,69]),set([70,22]),set([71,23]),set([40,88]),set([47,95]),set([45,93]),set([36,84]),set([43,91]),set([26,74]),set([44,92]),set([37,85]),set([24,72]),set([30,78]),set([38,86]),set([31,79]),set([29,77]),set([34,82]),set([46,94]),set([33,81]),set([41,89]),set([32,80]),set([27,75]),set([42,90]),set([28,76]),set([39,87]),set([35,83])])2025-01-23 10:53:49.837 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] rebuild new instance_cell: InstanceNUMACell(cpu_pinning_raw=None,cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=<?>,cpuset=set([0,1,2,3,4,5,6,7]),cpuset_reserved=None,id=0,memory=16384,pagesize=-2)2025-01-23 10:53:49.837 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Attempting to fit instance cell InstanceNUMACell(cpu_pinning_raw=None,cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=<?>,cpuset=set([0,1,2,3,4,5,6,7]),cpuset_reserved=None,id=0,memory=16384,pagesize=-2) on host_cell NUMACell(cpu_usage=80,cpuset=set([0,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95]),id=0,memory=784410,memory_usage=440320,mempages=[NUMAPagesTopology,NUMAPagesTopology,NUMAPagesTopology],network_metadata=NetworkMetadata,pinned_cpus=set([0,4,5,6,8,9,10,11,12,13,14,15,16,17,18,19,20,21,24,26,27,28,29,30,31,32,33,34,36,37,38,39,40,41,42,43,44,45,46,47,48,52,53,54,56,57,58,59,60,61,62,63,64,65,66,67,68,69,72,74,75,76,77,78,79,80,81,82,84,85,86,87,88,89,90,91,92,93,94,95]),siblings=[set([18,66]),set([17,65]),set([16,64]),set([67,19]),set([68,20]),set([59,11]),set([10,58]),set([60,12]),set([9,57]),set([5,53]),set([8,56]),set([54,6]),set([13,61]),set([52,4]),set([62,14]),set([63,15]),set([55,7]),set([0,48]),set([21,69]),set([70,22]),set([71,23]),set([40,88]),set([47,95]),set([45,93]),set([36,84]),set([43,91]),set([26,74]),set([44,92]),set([37,85]),set([24,72]),set([30,78]),set([38,86]),set([31,79]),set([29,77]),set([34,82]),set([46,94]),set([33,81]),set([41,89]),set([32,80]),set([27,75]),set([42,90]),set([28,76]),set([39,87]),set([35,83])])2025-01-23 10:53:49.838 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Selected memory pagesize: 1048576 kB. Requested memory pagesize: -2 (small = -1, large = -2, any = -3)2025-01-23 10:53:49.839 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Pinning has been requested2025-01-23 10:53:49.839 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Packing an instance onto a set of siblings: host_cell_free_siblings: [CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([7, 55]), CoercedSet([]), CoercedSet([]), CoercedSet([22, 70]), CoercedSet([23, 71]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([]), CoercedSet([83, 35])] instance_cell: InstanceNUMACell(cpu_pinning_raw=None,cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=<?>,cpuset=set([0,1,2,3,4,5,6,7]),cpuset_reserved=None,id=0,memory=16384,pagesize=1048576) host_cell_id: 0 threads_per_core: 2 num_cpu_reserved: 02025-01-23 10:53:49.840 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Built sibling_sets: defaultdict(<type 'list'>, {1: [CoercedSet([7, 55]), CoercedSet([22, 70]), CoercedSet([23, 71]), CoercedSet([83, 35])], 2: [CoercedSet([7, 55]), CoercedSet([22, 70]), CoercedSet([23, 71]), CoercedSet([83, 35])]})2025-01-23 10:53:49.840 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] User did not specify a thread policy. Using default for 8 cores2025-01-23 10:53:49.840 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Computed NUMA topology CPU pinning: usable pCPUs: [[7, 55], [22, 70], [23, 71], [83, 35]], vCPUs mapping: [(0, 7), (1, 55), (2, 22), (3, 70), (4, 23), (5, 71), (6, 83), (7, 35)]2025-01-23 10:53:49.841 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] Selected cores for pinning: [(0, 7), (1, 55), (2, 22), (3, 70), (4, 23), (5, 71), (6, 83), (7, 35)], in cell 02025-01-23 10:53:49.841 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] get new got_cell: InstanceNUMACell(cpu_pinning_raw={0=7,1=55,2=22,3=70,4=23,5=71,6=83,7=35},cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=VirtCPUTopology,cpuset=set([0,1,2,3,4,5,6,7]),cpuset_reserved=None,id=0,memory=16384,pagesize=1048576)2025-01-23 10:53:49.842 8 INFO nova.virt.hardware [req-f8727847-74c7-442f-9ced-26dec7bde8ef c20bbf36b9bb487b91fee105588686e8 82dbd32367414003b2470e6f7ca23ff2 - default default] get new chosen_instance_cells: [InstanceNUMACell(cpu_pinning_raw={0=7,1=55,2=22,3=70,4=23,5=71},cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=VirtCPUTopology,cpuset=set([0,1,2,3,4,5]),cpuset_reserved=None,id=0,memory=12288,pagesize=1048576), InstanceNUMACell(cpu_pinning_raw={6=83,7=35},cpu_policy='dedicated',cpu_thread_policy=None,cpu_topology=VirtCPUTopology,cpuset=set([6,7]),cpuset_reserved=None,id=1,memory=4096,pagesize=1048576)]从日志可知,8C16G内存套餐的CPU分配:numa0分配了2C,numa1分配了6C,此时,该计算节点的vcpu全部分配完了
五、相关收益
虚拟机CPU绑核NUMA不均衡分配实现能够提升资源的整体利用率,尤其在大规模资源分配需求下,提高套餐的满足率,进而提升计算资源的售卖率。
END
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn 或搜索“360智汇云”
客服电话:4000052360
欢迎使用我们的产品!😊
关注公众号,干货满满的前沿技术文章等你来。想看哪方面内容,也欢迎留言和我们交流!

















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









