



1.背景
DeepGEMM 是一个为高效 FP8 通用矩阵乘法(GEMMs)设计的库,其特点如提出于 DeepSeek--V3 的精细粒度缩放,支持普通和专家混合(MoE)分组 GEMMs。用 CUDA 编写,安装时无需编译,通过轻量级即时(JIT)模块在运行时编译所有内核。目前仅支持 NVIDIA Hopper 张量核心,采用 CUDA 核心两级积累(提升)解决 FP8 张量核心积累不精确问题。它避免过度依赖 CUTLASS 和 CuTe 的模板或代数,以简洁为设计理念,只有一个约 300 行代码的核心内核函数,是学习 Hopper FP8 矩阵乘法和优化技术的干净且易获取的资源。尽管设计轻量,但在各种矩阵形状下性能可匹配或超越专家调优的库。
2.验证运行
我们分别在H20和H800上测试了 DeepSeek-V3/R1 推理中可能使用的所有形状的稠密矩阵乘法性能。并对deepgemm、vllm triton ,以及vllm cutlass 进行对比
2.1 H20 表现
分别就不同维度的稠密矩阵乘法,对比在三个架构下乘法性能,
2.1.1 指标数据
TFLOPS
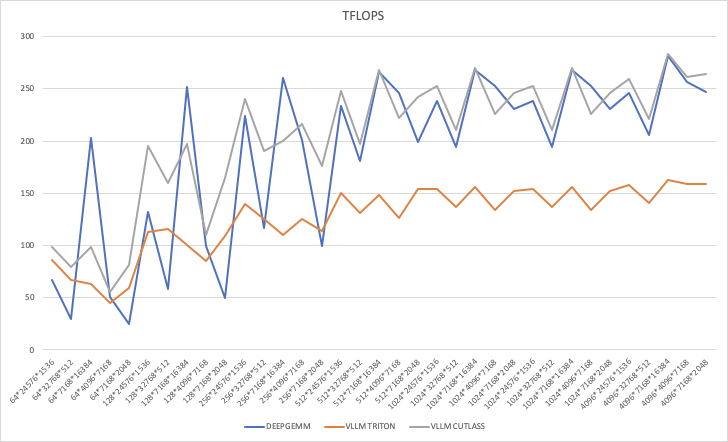
GB/s
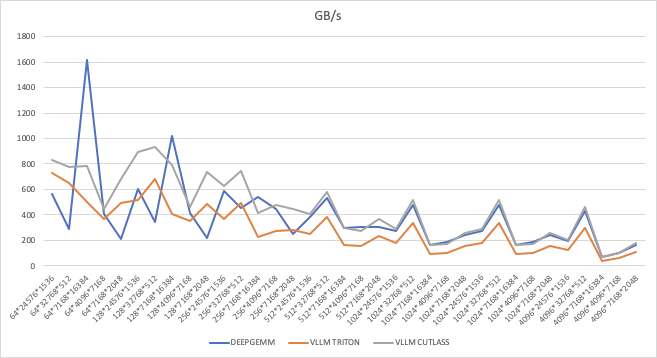
Latency
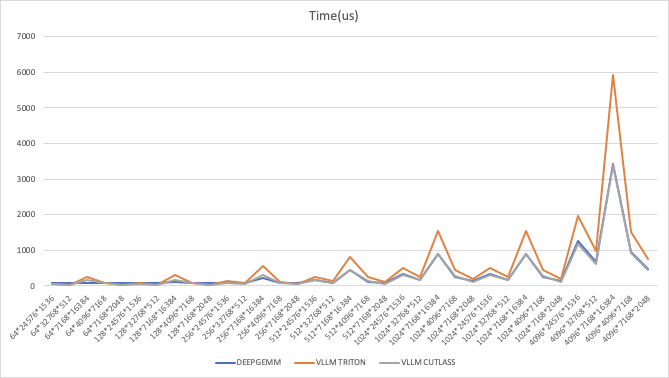
2.1.2 性能对比分析
DeepGEMM vs Cutlass
总体对比:Cutlass 的性能相较于 DeepGEMM 波动较大,加速比介于 0.77x ~ 3.31x 之间。
小规模计算(m ≤ 128):
在
m=64, k=2048的情况下,Cutlass 性能达到 3.31x DeepGEMM,表明 Cutlass 在小批量计算中的优化较好。但在
m=64, k=16384和m=128, k=16384这类大k值情况下,Cutlass 低于 DeepGEMM,仅 0.49x ~ 0.78x,可能由于 Cutlass 在大k处理上的局限性。
中等规模计算(256 ≤ m ≤ 1024):
Cutlass 在大多数情况下接近 1.0x ~ 1.78x DeepGEMM,例如
m=512, k=2048达到 1.21x,但m=512, k=7168下降至 0.90x。
大规模计算(m = 4096):
在
m=4096, k=16384的情况下,Cutlass 性能与 DeepGEMM 基本持平(1.01x)。但在
m=4096, k=7168,Cutlass 低于 DeepGEMM,仅 1.02x,说明 Cutlass 在大规模m下仍有优化空间。
DeepGEMM vs Triton
总体对比:DeepGEMM 全面优于 Triton,加速比范围在 1.38x ~ 1.95x 之间。
小规模计算(m ≤ 128):
DeepGEMM 在
m=64, k=16384领先 1.55x,在m=128, k=16384领先 1.95x,说明 DeepGEMM 在处理大k时表现优异。
中等规模计算(256 ≤ m ≤ 1024):
在
m=512, k=16384,DeepGEMM 领先 1.80x,但m=512, k=4096时 Triton 仍能保持较高的竞争力(1.75x)。
大规模计算(m = 4096):
在
m=4096, k=16384,DeepGEMM 仍然领先 1.74x,但对m=4096, k=2048,领先幅度减少至 1.66x,说明 Triton 在处理小k值的大m时相对较优化。
结论
DeepGEMM vs Cutlass:
Cutlass 在 小批量计算 (
m小,k适中) 时 比 DeepGEMM 快 3.31x,但 在大k值时性能下降,整体表现不如 DeepGEMM 稳定。在 大规模计算(m ≥ 1024) 时,Cutlass 基本与 DeepGEMM 持平(1.01x ~ 1.07x),但部分情况下略有下降(0.89x)。
DeepGEMM vs Triton:
DeepGEMM 全面优于 Triton,尤其在
k较大(如16384)的情况下,DeepGEMM 最高 1.95x Triton,展现出强大的优化能力。在 小
k值(如 2048)的大m计算 时,Triton 能维持一定的竞争力(1.66x ~ 1.74x),但仍落后于 DeepGEMM。
2.1.3 详细数据
Cutlass 与 DeepGEMM和Triton对比
m | n | k | Time | TFLOPS | GB/s | vs DeepGEMM | vs Triton |
64 | 24576 | 1536 | 49.2 | 98.1 | 832.5 | 1.47x | 1.14x |
64 | 32768 | 512 | 27.1 | 79.2 | 774.2 | 2.66x | 1.18x |
64 | 7168 | 16384 | 152.5 | 98.6 | 783 | 0.49x | 1.55x |
64 | 4096 | 7168 | 68.1 | 55.2 | 445.3 | 1.09x | 1.22x |
64 | 7168 | 2048 | 23 | 81.6 | 683 | 3.25x | 1.38x |
128 | 24576 | 1536 | 49.4 | 195.5 | 894.8 | 1.48x | 1.74x |
128 | 32768 | 512 | 26.9 | 159.4 | 936.6 | 2.72x | 1.38x |
128 | 7168 | 16384 | 152.8 | 196.7 | 794.2 | 0.78x | 1.95x |
128 | 4096 | 7168 | 68.2 | 110.1 | 459 | 1.10x | 1.30x |
128 | 7168 | 2048 | 22.8 | 164.6 | 734.8 | 3.31x | 1.50x |
256 | 24576 | 1536 | 80.4 | 240.3 | 630.6 | 1.07x | 1.72x |
256 | 32768 | 512 | 45 | 190.9 | 748.8 | 1.63x | 1.53x |
256 | 7168 | 16384 | 300.2 | 200.3 | 417.5 | 0.77x | 1.82x |
256 | 4096 | 7168 | 69.4 | 216.7 | 479.9 | 1.08x | 1.73x |
256 | 7168 | 2048 | 42.6 | 176.5 | 443.3 | 1.78x | 1.56x |
512 | 24576 | 1536 | 155.8 | 248.1 | 408.9 | 1.06x | 1.66x |
512 | 32768 | 512 | 87 | 197.5 | 581.5 | 1.09x | 1.50x |
512 | 7168 | 16384 | 448.3 | 268.3 | 297.1 | 1.01x | 1.80x |
512 | 4096 | 7168 | 135.6 | 221.7 | 274.5 | 0.90x | 1.75x |
512 | 7168 | 2048 | 62.2 | 241.8 | 371.1 | 1.21x | 1.57x |
1024 | 24576 | 1536 | 306.3 | 252.4 | 292.7 | 1.06x | 1.64x |
1024 | 32768 | 512 | 163.3 | 210.4 | 517 | 1.09x | 1.54x |
1024 | 7168 | 16384 | 891.9 | 269.7 | 167 | 1.01x | 1.73x |
1024 | 4096 | 7168 | 266.4 | 225.7 | 169.2 | 0.89x | 1.69x |
1024 | 7168 | 2048 | 122.2 | 246 | 257.4 | 1.07x | 1.62x |
1024 | 24576 | 1536 | 306.3 | 252.4 | 292.7 | 1.06x | 1.64x |
1024 | 32768 | 512 | 163 | 210.8 | 517.9 | 1.09x | 1.54x |
1024 | 7168 | 16384 | 892 | 269.6 | 166.9 | 1.01x | 1.73x |
1024 | 4096 | 7168 | 266.3 | 225.8 | 169.3 | 0.89x | 1.69x |
1024 | 7168 | 2048 | 122.2 | 246.1 | 257.5 | 1.07x | 1.62x |
4096 | 24576 | 1536 | 1190.1 | 259.8 | 206.2 | 1.06x | 1.65x |
4096 | 32768 | 512 | 620.7 | 221.4 | 462.9 | 1.07x | 1.57x |
4096 | 7168 | 16384 | 3395.3 | 283.4 | 71.6 | 1.01x | 1.74x |
4096 | 4096 | 7168 | 920.4 | 261.3 | 100.3 | 1.02x | 1.65x |
4096 | 7168 | 2048 | 455.1 | 264.3 | 179.7 | 1.07x | 1.66x |
AVERAGE PERFORMANCE
Implementation | Avg TFLOPS | TFLOPS | Avg GB/s |
DeepGEMM | 188.49 | 384.46 | 0.36 |
vLLM Triton | 126.01 | 297.19 | 0.58 |
vLLM CUTLASS | 204 | 451.96 | 0.35 |
AVERAGE SPEEDUPS
Comparison | Speedup |
|---|---|
DeepGEMM vs vLLM Triton | 1.46x faster |
DeepGEMM vs vLLM CUTLASS | 0.90x slower |
vLLM CUTLASS vs vLLM Triton | 1.59x faster |
2.2 H800表现
2.2.1 指标数据
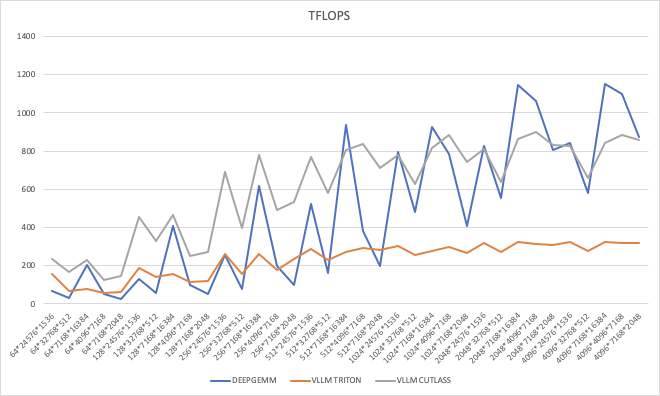
TFLOPS
GB/s
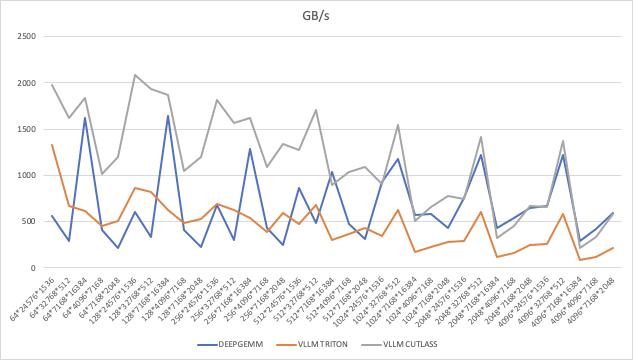
Latency
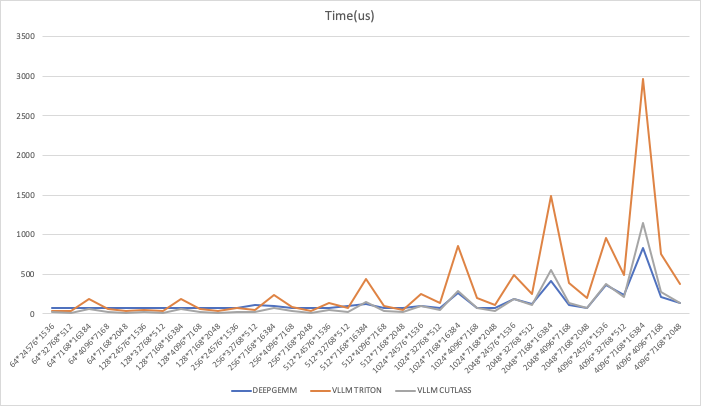
2.2.2 性能对比分析
Cutlass vs DeepGEMM
小规模矩阵 (m, n, k ≤ 256): Cutlass 明显优于 DeepGEMM,通常 快 2-5 倍,说明 Cutlass 在小矩阵优化更好。
中等规模矩阵 (512 ≤ m, n, k ≤ 2048): Cutlass 仍然 比 DeepGEMM 快 1.0x-3.5x,但随着矩阵增大,优势缩小。
大规模矩阵 (m, n, k ≥ 4096): DeepGEMM 逐渐追平甚至略超 Cutlass,特别是在 (4096, 7168, 16384) 这种大矩阵情况下,Cutlass 仅为 DeepGEMM 的 0.73x-0.98x,说明 DeepGEMM 在超大规模 GEMM 计算上更优。
Triton vs DeepGEMM
Triton 在所有情况下都明显慢于 DeepGEMM,一般 慢 2-3 倍,个别情况甚至慢 3 倍以上(如 7168×16384 计算)。
即便是 Cutlass 相对 DeepGEMM 性能下降的情况(大矩阵),DeepGEMM 仍然远超 Triton,说明 Triton 的矩阵计算优化远不及 DeepGEMM。
结论
DeepGEMM 在大规模 GEMM 计算上比 Cutlass 和 Triton 更高效,特别是 4096 及以上的矩阵。
Cutlass 在小矩阵上最优,但在超大矩阵上被 DeepGEMM 赶超。
Triton 在所有情况下最慢,DeepGEMM 远超 Triton,适合更高效的 GEMM 计算。
2.2.3 详细数据
Cutlass 与 DeepGEMM和Triton对比
m | n | k | Time | TFLOPS | GB/s | vs DeepGEMM | vs Triton |
64 | 24576 | 1536 | 49.2 | 98.1 | 832.5 | 1.47x | 1.14x |
64 | 32768 | 512 | 27.1 | 79.2 | 774.2 | 2.66x | 1.18x |
64 | 7168 | 16384 | 152.5 | 98.6 | 783 | 0.49x | 1.55x |
64 | 4096 | 7168 | 68.1 | 55.2 | 445.3 | 1.09x | 1.22x |
64 | 7168 | 2048 | 23 | 81.6 | 683 | 3.25x | 1.38x |
128 | 24576 | 1536 | 49.4 | 195.5 | 894.8 | 1.48x | 1.74x |
128 | 32768 | 512 | 26.9 | 159.4 | 936.6 | 2.72x | 1.38x |
128 | 7168 | 16384 | 152.8 | 196.7 | 794.2 | 0.78x | 1.95x |
128 | 4096 | 7168 | 68.2 | 110.1 | 459 | 1.10x | 1.30x |
128 | 7168 | 2048 | 22.8 | 164.6 | 734.8 | 3.31x | 1.50x |
256 | 24576 | 1536 | 80.4 | 240.3 | 630.6 | 1.07x | 1.72x |
256 | 32768 | 512 | 45 | 190.9 | 748.8 | 1.63x | 1.53x |
256 | 7168 | 16384 | 300.2 | 200.3 | 417.5 | 0.77x | 1.82x |
256 | 4096 | 7168 | 69.4 | 216.7 | 479.9 | 1.08x | 1.73x |
256 | 7168 | 2048 | 42.6 | 176.5 | 443.3 | 1.78x | 1.56x |
512 | 24576 | 1536 | 155.8 | 248.1 | 408.9 | 1.06x | 1.66x |
512 | 32768 | 512 | 87 | 197.5 | 581.5 | 1.09x | 1.50x |
512 | 7168 | 16384 | 448.3 | 268.3 | 297.1 | 1.01x | 1.80x |
512 | 4096 | 7168 | 135.6 | 221.7 | 274.5 | 0.90x | 1.75x |
512 | 7168 | 2048 | 62.2 | 241.8 | 371.1 | 1.21x | 1.57x |
1024 | 24576 | 1536 | 306.3 | 252.4 | 292.7 | 1.06x | 1.64x |
1024 | 32768 | 512 | 163.3 | 210.4 | 517 | 1.09x | 1.54x |
1024 | 7168 | 16384 | 891.9 | 269.7 | 167 | 1.01x | 1.73x |
1024 | 4096 | 7168 | 266.4 | 225.7 | 169.2 | 0.89x | 1.69x |
1024 | 7168 | 2048 | 122.2 | 246 | 257.4 | 1.07x | 1.62x |
1024 | 24576 | 1536 | 306.3 | 252.4 | 292.7 | 1.06x | 1.64x |
1024 | 32768 | 512 | 163 | 210.8 | 517.9 | 1.09x | 1.54x |
1024 | 7168 | 16384 | 892 | 269.6 | 166.9 | 1.01x | 1.73x |
1024 | 4096 | 7168 | 266.3 | 225.8 | 169.3 | 0.89x | 1.69x |
1024 | 7168 | 2048 | 122.2 | 246.1 | 257.5 | 1.07x | 1.62x |
4096 | 24576 | 1536 | 1190.1 | 259.8 | 206.2 | 1.06x | 1.65x |
4096 | 32768 | 512 | 620.7 | 221.4 | 462.9 | 1.07x | 1.57x |
4096 | 7168 | 16384 | 3395.3 | 283.4 | 71.6 | 1.01x | 1.74x |
4096 | 4096 | 7168 | 920.4 | 261.3 | 100.3 | 1.02x | 1.65x |
4096 | 7168 | 2048 | 455.1 | 264.3 | 179.7 | 1.07x | 1.66x |
AVERAGE PERFORMANCE
Implementation | Avg TFLOPS | Avg GB/s | Avg Time (ms) |
|---|---|---|---|
DeepGEMM | 378.44 | 632.26 | 0.17 |
vLLM Triton | 180.53 | 546.70 | 0.42 |
vLLM CUTLASS | 450.88 | 1273.15 | 0.16 |
AVERAGE SPEEDUPS
Comparison | Speedup |
|---|---|
DeepGEMM vs vLLM Triton | 1.61x faster |
DeepGEMM vs vLLM CUTLASS | 0.62x slower |
vLLM CUTLASS vs vLLM Triton | 2.45x faster |
3. 算法优劣分析
根据测试数据,我们从 计算性能(TFLOPS)、带宽利用率(GB/s)、执行时间(Time/ms)、相对加速比 等维度对 DeepGEMM、vLLM Triton、vLLM CUTLASS 进行深入分析,并最终给出适合不同应用场景的建议。
3.1 DeepGEMM
优点
✅ 计算性能较高,优于 vLLM Triton
在 H20 上,DeepGEMM 比 vLLM Triton 快 1.46x(188.49 vs 126.01 TFLOPS)。
在 H800 上,DeepGEMM 比 vLLM Triton 快 1.61x(378.44 vs 180.53 TFLOPS)。
说明 DeepGEMM 在 核心计算效率 方面比 Triton 版本更强。
✅ 适用于多种 GPU,兼容性较好
在 两款 GPU 上的性能表现均衡,虽然 CUTLASS 在 H800 上更强,但 DeepGEMM 保持较好性能。
适合用于不同的 GPU 硬件环境,不依赖特定优化。
缺点
❌ 在 H800 上比 CUTLASS 慢
H800 上 DeepGEMM 的 TFLOPS 低于 CUTLASS(378.44 vs 450.88),意味着 CUTLASS 的矩阵计算优化更好。
带宽利用率也不如 CUTLASS(632.26 vs 1273.15 GB/s),表明 CUTLASS 可能更适合高效数据传输的任务。
如果使用 H800 并追求极致性能,CUTLASS 更值得选择。
3.2 vLLM Triton
优点
✅ Triton 内核易于优化,支持自定义 Kernel
Triton 适用于优化 LLM 计算,能在不同硬件上通过 kernel-level 代码调整性能。
✅ 计算方式较灵活,适用于动态 workload
Triton 允许动态 shape 计算,比 CUDA kernel 更适合处理 动态 batch size 任务,例如 在线推理。
缺点
❌ 计算效率最低,远逊于 DeepGEMM 和 CUTLASS
在 H20 GPU 上,TFLOPS 仅 126.01,比 DeepGEMM 低 32%。
在 H800 上,TFLOPS 仅 180.53,带宽 546.7 GB/s,相比 CUTLASS(450.88 TFLOPS,1273.15 GB/s)差距很大。
DeepGEMM 比 vLLM Triton 快 1.61x,CUTLASS 比 vLLM Triton 快 2.45x!
❌ H800 上表现尤为不佳
执行时间更长(0.42ms vs DeepGEMM 0.17ms vs CUTLASS 0.16ms),表明 vLLM Triton 在大规模矩阵运算上表现不理想。
说明 Triton 版本的 kernel 可能在 算子融合 和 数据流优化 方面仍有较大优化空间。
3.3 vLLM CUTLASS
优点
✅ H800 上性能最佳,TFLOPS 和带宽最高
在 H800 上的 TFLOPS 高达 450.88(比 DeepGEMM 高 19%),说明 CUTLASS 内核优化出色。
带宽利用率远超 DeepGEMM(1273.15 vs 632.26 GB/s),意味着 CUTLASS 能更有效地管理 内存带宽。
执行时间最短(0.16ms vs DeepGEMM 0.17ms vs Triton 0.42ms),在低延迟推理场景下表现优异。
✅ 高度优化的 CUDA kernel,适合高吞吐量任务
CUTLASS 主要优化了 GEMM 计算,能最大限度发挥 GPU Tensor Core 的性能。
适合大规模 LLM 推理,尤其是 batch size 较大的情况。
缺点
❌ 在部分 GPU 上,CUTLASS 的提升有限
在 H20 上,CUTLASS 仅比 DeepGEMM 快 1.08x(204 vs 188.49 TFLOPS),提升不明显。
可能表明 CUTLASS 的优化主要针对 H100/H800 这种高端 GPU,对 H20 等架构的提升不大。
❌ 可能对动态 workload 兼容性较差
CUTLASS 适用于 大 batch size,静态 shape 计算,但可能 不如 Triton 适用于动态 shape 任务。
4. 总结
方案 | 优点 | 缺点 | 适用场景 |
DeepGEMM | 适用于多种 GPU,计算性能较好,优于 Triton | H800 上比 CUTLASS 慢 | 通用计算场景,适用于不同 GPU |
vLLM Triton | Kernel 易优化,适合动态 shape | 计算效率最低,H800 上表现尤差 | 需要 Triton 兼容性,需要优化 kernel |
vLLM CUTLASS | H800 上最高 TFLOPS & 带宽,最短执行时间 | 可能对老 GPU 提升有限,动态 workload 兼容性较差 | 大规模推理任务,H800 等高端 GPU |
天纪大模型开发平台TLM使用地址:https://zyun.360.cn/product/tlm

















 1137
1137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









