






一、背景
深度求索DeepSeek-R1推理模型一经推出,就以其创新的、低成本的训练方案以及可媲美全球顶尖闭源模型的惊艳效果迅速火遍全网,并在极短的时间内吸引了来自全世界的大量用户来体验及使用。广大网友在惊艳其效果的同时也在好奇如此规模庞大的模型是如何高效的进行推理的,DeepSeek内部又是建立了一套什么样的推理系统以支撑其庞大的用户需求量的。这些内容在DeepSeek_V3的技术报告中已经有了比较详细的介绍了,此外在2月的最后一周,DeepSeek更是以开源周的方式连续五天开源五大核心代码库及相关技术文档,引发了全球AI开发者的高度关注。开源内容涵盖计算优化、通信效率优化及存储加速等三大核心领域。本文主要基于通信效率优化的DeepEP通信库展开介绍。
二、DeepEP通信库核心能力
DeepEP通信库核心能力主要包括以下六个方面:
高效优化的All-to-All通信
支持节点内NVLink和节点间RDMA通信
训练及推理预填充Prefill阶段的高吞吐量计算Kernel
推理解码Decoder阶段的低延时计算Kernel
原生支持FP8分发
能够灵活的控制GPU资源,实现计算与通信的高效overlap
三、DeepEP在软件栈中的位置
DeepEP是专门针对MoE模型大规模专家并行场景进行优化的高效通信库,其依赖NVIDIA软件生态的NVSHMEM GPU通信库、GDRCopy低延时GPU显存拷贝库及IBGDA等核心技术,实现了经典的以NCCL为主的高效集合通信库的功能。官方DeepSeek-R1的推理系统即是依赖DeepEP+NVSHMEM+GDRCopy+IBGDA的方案替代了NCCL进行高效通信的。整个软件栈的架构图如下:
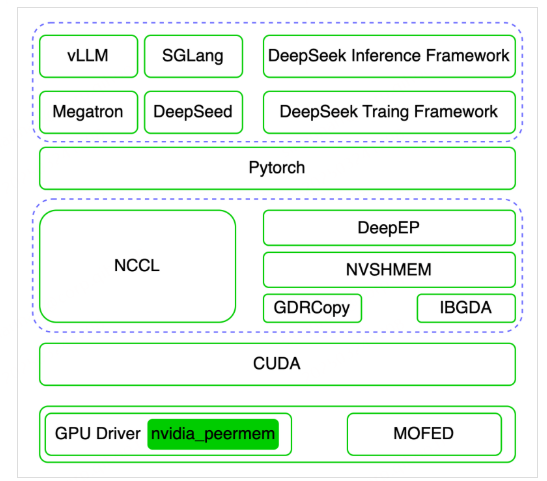
下文将详细介绍DeepEP所涉及到的相关内容。
四、MoE中的All-to-All通信
在大规模MoE模型进行训练和推理的过程中,面临的最主要问题就是大规模专家并行的All-to-All通信瓶颈,在次过程中,All-to-All通信主要分为两个阶段:Dispatch阶段和Combine阶段。如下图所示
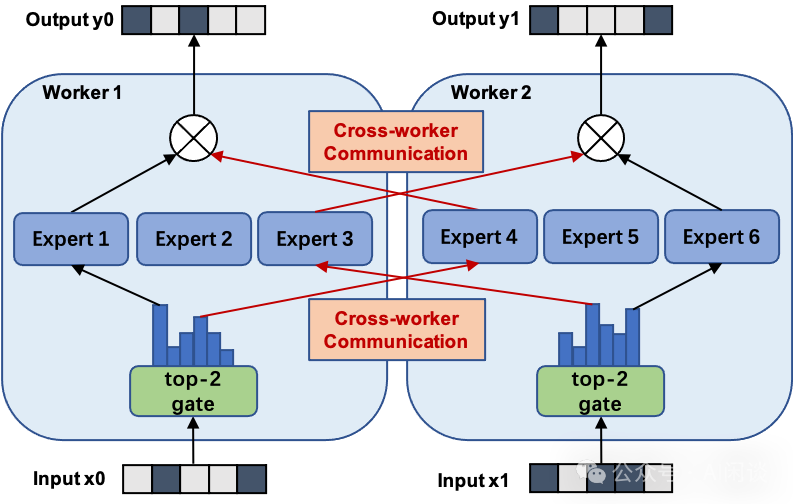
Dispatch阶段
在MoE模型中,dispatch的目的是将输入数据分发到不同的专家进行处理。由于每个输入token只需要激活top-k个专家,因此dispatch需要根据门控路由的结果将数据发送到对应的专家上。具体流程如下:
路由计算
使用一个路由网络(FFN)计算每个token对所有专家的分数
根据分数选择top-k个专家,生成对应的索引和权重
数据分发
根据top-k索引,将输入数据分发到对应的专家,每个专家会接收到属于自己的输入数据
通信机制
使用All-to-All通信方式,确保每个节点上的数据可以被正确的分发到所有其它节点上的专家
Combine阶段
在MoE模型中,combine的目的是将各个专家的输出结果合并回一个完整的输出张量。由于每个token的输出是由top-k个专家的输出加权求和得到的,因此需要重新将这些数据进行组合。具体流程如下:
结果聚合
根据top-k专家的索引和权重,将每个专家的输出结果聚合到对应的token上
通常使用加权求和的方式进行聚合
通信机制
a.使用All-to-All通信方式,将各个节点上的专家输出数据回传到原节点,以便进行结果聚合
五、NVSHMEM通信库
DeepEP利用了NVSHMEM的能力进行高效通信。NVSHMEM是一个基于OpenSHMEM的专门用于NVIDIA GPU的通信库,其核心思想是将所有GPU节点上的显存视为一个大的显存池来进行管理即分区全局地址空间(PGAS)。该库支持通过GPU共享内存直接进行数据访问,提供如shmem_put、shmem_get等可以进行细粒度数据传输的API接口。除此之外,还集成了IBGDA(InfiniBand GPUDirect Async)进行高性能的GPUDirect RDMA通信。结构图如下:

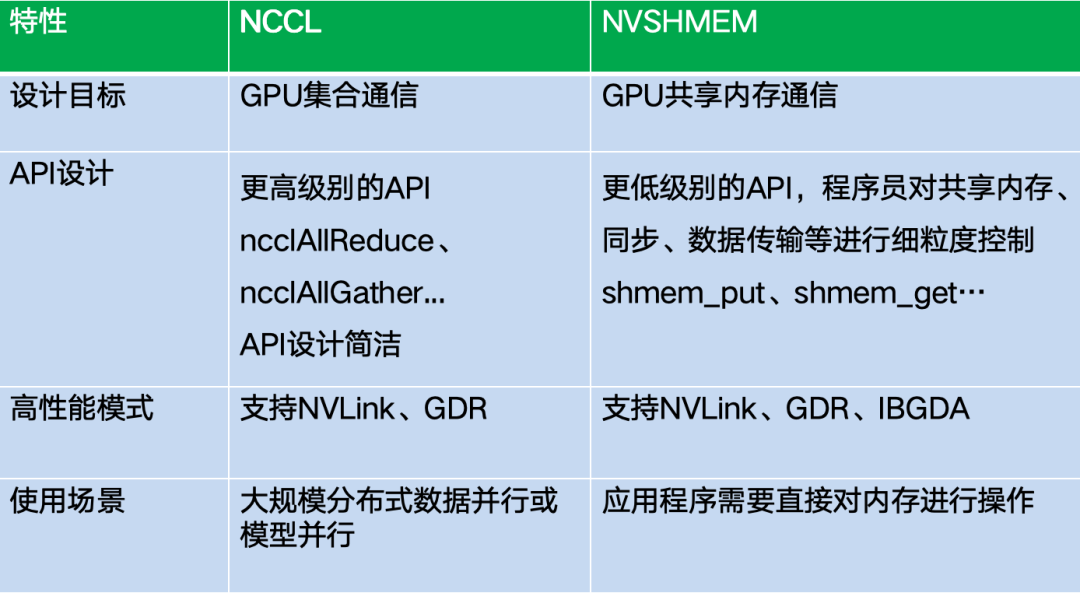
NCCL VS NVSHMEM
NVSHMEM通信库和经典的NCCL集合通信库的对比如下表所示:
六、GDRCopy低延时库
官方对GDRCopy的定义如下:基于GPUDirect RDMA技术的低延时GPU显存拷贝库,允许CPU直接访问GPU显存。示意图如下:
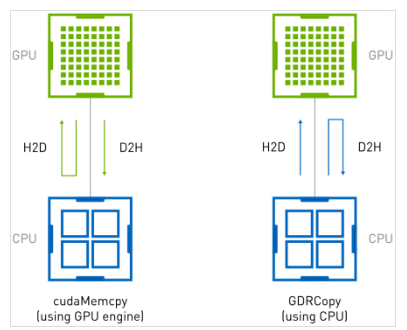
从图中我们可以看出,在使用了GDRCopy的能力后,H2D的链路缩短了,这优化了H2D的延时。NVIDIA官方给出的性能测试结果如下:
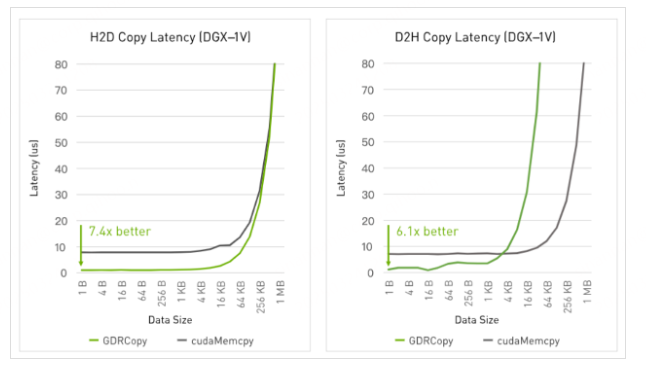
可以看出,在小消息传输的场景下,和传统的cudaMemcpy相比,利用GDRCopy后的延时有了很大程度的降低。
七、InfiniBand GPUDirect Async技术
InfiniBand GPUDirect Async简称IBGDA,是NVIDIA推出的基于InfiniBand GPUDirect RDMA(简称GDR)技术进一步优化的高效通信技术。在介绍IBGDA之前,先介绍下GDR的流程,如下图所示:
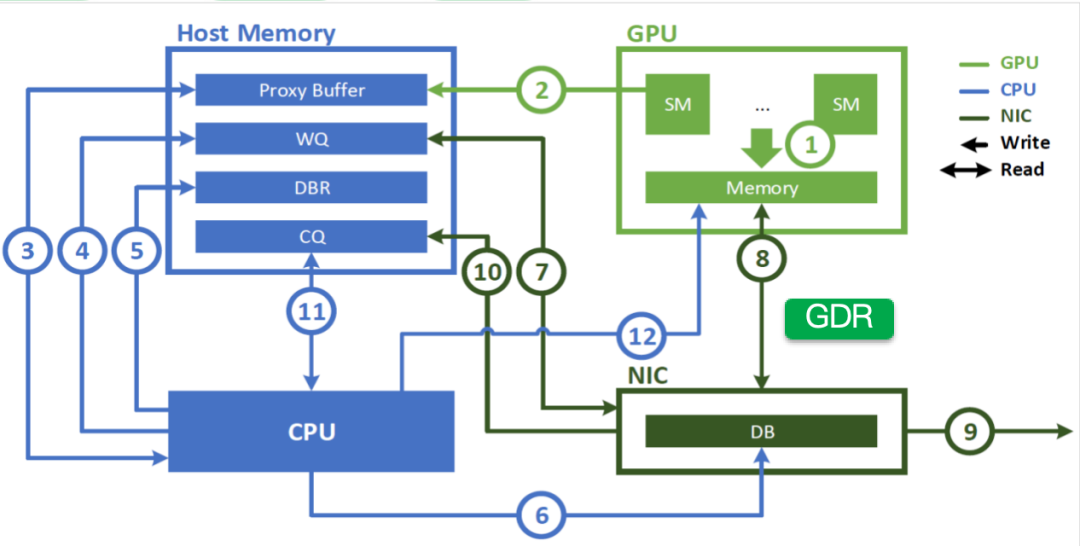
整个流程如下:
应用程序launch cuda kernel,在显存中生成数据
SM写一个work descriptor到在主机内存中的一个代理线程的proxy buffer中
proxy通知cpu进行相应的网络操作
CPU创建work descriptor到WQ队列中
CPU更新doorbell record(DBR)
CPU注册相关信息到NIC的DB中以通知NIC进行数据传输
NIC从WQ中读取work descriptor
NIC通过GDR从显存中读取数据
NIC发送数据到远端节点
NIC写完成event到CQ队列中
CPU从CQ中确认网络操作完成
CPU通知GPU操作完成,此步依赖GDRCopy
从上述流程可以看出,经典的GDR技术有比较多的非应用数据传输的步骤需要CPU的参与。由于GPU和Mellanox高性能网卡的数据处理能力都在快速增长,且远远超过CPU的处理能力,因此在对延时有极高要求的场景下,经典的GDR技术在CPU侧会成为瓶颈。
为进一步优化通信效率,NVIDIA在GDR的基础上推出了IBGDA,如下图所示:
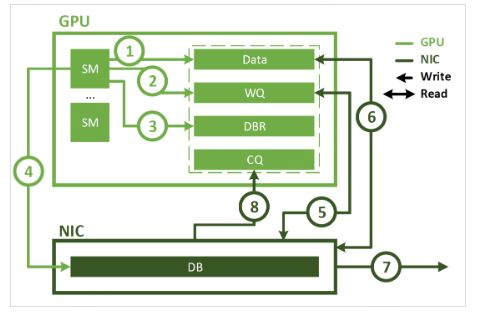
整个流程如下:
应用程序launch cuda kernel,在显存中生成数据
SM创建work descriptor到WQ中
SM更新DBR
SM通知NIC
NIC通过GDR从WQ中读取work descriptor
NIC通过GDR从显存中读取数据
NIC发送数据到远端节点
NIC通过GDR向CQ中写入完成事件
从上述流程可以看出,IBGDA将在CPU上进行的相关操作全部放到GPU中,整个过程完全不需要CPU的参与,进一步减少了通信链路,提高了通信效率。NVIDIA官方基于IBGDA技术在All-to-All场景下的延时测试如下:

注:为凸显IBGDA的效果,该测试禁用了A100节点内的NVLink;32 PEs可以理解为有32张A100;IBRC表示未启用IBGDA
从上述测试结果可以看出,在小消息传输的场景下,启用IBGDA后延时有了大幅的下降。
总结
DeepSeek基于上述相关技术,在DeepEP中实现了专门用于训练和推理Prefilling阶段的高吞吐Kernel及专门用于推理Decoding阶段的低延时Kernel。此外,DeepSeek内部还实现了一套P-D分离的推理系统来高效的部署DeepSeek相关模型以支撑庞大的用户请求量。最后,对于DeepEP及其相关内容,还有很多值得我们进一步挖掘及借鉴的点,同时我们也会持续跟进其最新进展,以期在部门内部能有一定程度的实践及落地。
天纪大模型开发平台使用地址:https://zyun.360.cn/product/tlm

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









